BackBox.org offers a range of Penetration Testing services to simulate an attack on your network or application. If you are interested in our services, please contact us and we will provide you with further information as well as an initial consultation.


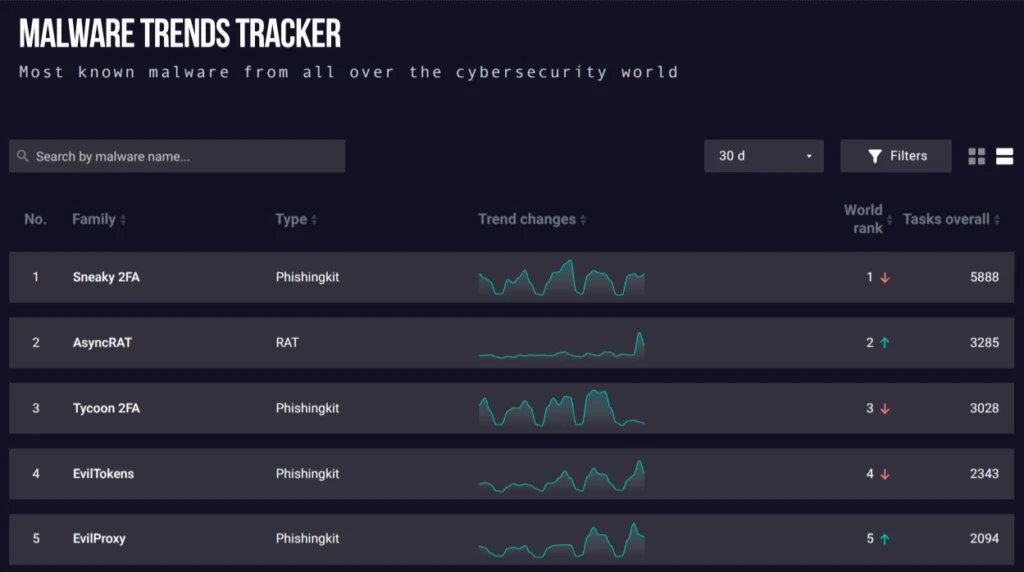





The best email hosting for small businesses in 2026: Expert tested
/in General NewsI tested Google Workspace, Proton Mail, Microsoft 365, Fastmail, and Spike to find the best email hosting for freelancers and remote teams in 2026.
Latest news – Read More
Compromised jscrambler 8.14.0 npm Release Drops Rust Infostealer During Install
/in General NewsThe jscrambler npm package was compromised, and simply installing its 8.14.0 release runs an infostealer on your machine. Published on July 11, 2026, the malicious version carries a preinstall hook that drops and executes a native binary, one build each for Windows, macOS, and Linux.
Socket flagged the release six minutes after it was published. If you or one of your
The Hacker News – Read More
Hackers Weaponize Balochistan Police Portal in Multi-Group Espionage Campaigns
/in General NewsCybersecurity researchers have disclosed details of sustained cyber espionage activity against several Pakistani law enforcement organizations undertaken by suspected China- and India-aligned threat actors between February 2024 and April 2026.
“At Balochistan Police, the compromised assets included servers hosting web applications that manage police and citizen data, such as criminal and
The Hacker News – Read More
Forget typosquatting; slopsquatting is the software supply chain threat created by AI coding tools
/in General NewsSlopsquatting represents an emerging supply chain threat made possible by AI hallucinations. As developers increasingly rely on AI coding assistants, they unknowingly grant cybercriminals access to their software from day one.
Understanding what slopsquatting is
Slopsquatting is a new type of supply chain attack that uses large language model (LLM) hallucinations to inject malicious code into development workflows. The term combines “AI slop” and “typosquatting,” a deceptive practice where attackers register misspelled or lookalike versions of popular domains to prey on users who enter URLs incorrectly.
This novel attack vector exploits LLMs’ tendency to generate fictitious software package names, which threat actors can then register and populate with malicious code.
During AI-assisted coding, the model may generate fake open-source packages — bundled collections of files, programs and installation tools. This alone is not necessarily harmful. However, if an attacker registers that fake package name, they can inject malware that gets incorporated directly into a developer’s codebase.
How AI creates a supply chain risk
Traditionally, AI safety risks stem from hallucinations, which can adversely affect users who treat misinformation as valid. However, those same hallucinations have evolved into exploitable security vulnerabilities.
Typosquatting is a deceptive practice where a cybercriminal registers a mispelled version of a popular package to trick developers. It has existed for decades, so registries have built protections against it.
However, AI has changed the threat model. It recommends fictitious packages that sound plausible rather than making simple misspellings. Once attackers learn which hallucinated packages models tend to invent, they can register malware-filled packages under those names.
Since the hallucinated packages are not simply typoed versions of popular libraries, there are no protections against this practice at scale. For example, the registry protects against an attacker publishing “crossenv,” a squat of the popular “cross-env” package. However, it would not identify “mpn install cross-env file” or “cross-env-extended” as threats.
Hallucinations are persistent and severe
Even if many LLMs recommend the same hallucinated package, widespread compromise is still possible. Malicious packages could remain undetected in production for months or even years, allowing threat actors to passively inject malware across countless environments.
One research team analyzed 31,267 vulnerabilities belonging to 14,675 packages across 10 programming languages. They discovered that reported vulnerabilities are increasing at an annual rate of 98%, faster growth than the 25% annual increase in the number of open-source software packages. The team also observed an 85% increase in the average lifespan of vulnerabilities, indicating a decline in security.
Real-world dangers of AI hallucinations
Malicious actors can create open-access packages under the same name as commonly hallucinated libraries. Instead of standard code, they are filled with malware. The models believe they are referring to existing packages, so they often repeat the same hallucinated names. Since the hallucinations are not random, attackers could theoretically register packages that trick tens of thousands of developers.
These packages appear legitimate. String similarity to real libraries makes them recognizable. One-character typos suggest simple mistakes rather than malicious intent. Even fully fabricated names remain believable when the AI presents them in proper context. Detection is challenging, as developers trust their coding assistants to recommend valid dependencies.
Why are LLMs hallucinating packages?
LLMs generate the statistically most likely answer rather than prioritizing accuracy. Hallucinations are relatively common as a result. One study found hallucination rates range from 50% to 82%, depending on the model and prompting method. Even GPT-4o, the best-performing model, goes no lower than 23%, even with prompt-based mitigation.
Adversarial hallucination attacks could worsen this problem. Threat actors can leverage token-level manipulation or retrieval poisoning to force models to hallucinate in ways they want, increasing the likelihood that models recommend their malicious packages.
Which LLMs are prone to slopsquatting?
While all LLMs are prone to slopsquatting, some are more vulnerable than others. The likelihood of producing hallucinated packages during code generation depends on the model. Proprietary models are four times less likely to generate hallucinated packages than open-source models.
One research group proved this by conducting 30 tests across 30 different systems. Out of the 576,000 code samples and 2.23 million packages it produced, 19.7% were hallucinations. GPT-4.0 Turbo had a hallucination rate of 3.59%, while DeepSeek 1B, the best-performing open-source model, reached 13.63%.
This research suggests that organizations relying on open-source AI tools for code generation are roughly four times more exposed to slopsquatting attacks. That doesn’t necessarily mean proprietary tools will always remain safer, though. Once attackers realize this disparity, they may manipulate proprietary LLMs to take advantage of perceived safety.
Vibe coding contributes to the problem
Software developers who use AI tools estimate that over 40 percent of the code they commit includes AI assistance. They expect that percentage will increase considerably within the next few years. Already, 72% of those who have tried AI use it daily.
The uptick in vibe coding and AI-assisted coding amplifies the threat surface. As more developers integrate AI tools into their workflows without implementing proper verification processes, the attack surface for slopsquatting continues to expand.
For those using AI to assist with coding, double-checking output is essential. Verifying that recommended packages actually exist in official repositories before incorporating them into projects reduces risk.
Navigating AI-assisted development
Implementing automated checks that validate package names against known registries can help catch hallucinated packages before they enter production code. Security teams should also monitor for unusual package installations and maintain up-to-date threat intelligence on known slopsquatting campaigns.
Zac Amos is the Features Editor at ReHack.
Security | VentureBeat – Read More
Ghost Accounts Abuse GitHub API in Mass Recon Campaign
/in General NewsMultiple campaigns are using ghost accounts to map GitHub organizations, including their repositories and members.
The post Ghost Accounts Abuse GitHub API in Mass Recon Campaign appeared first on SecurityWeek.
SecurityWeek – Read More
My Fitbit Air test revealed the flaws of calorie counting with a health tracker – here’s why
/in General NewsYou should take calorie data with a grain of salt. Here’s what I learned after testing the Fitbit Air’s heart rate data against a gold standard heart rate monitor.
Latest news – Read More
AI Found a Root Bug in Linux That Everyone Missed for 15 Years
/in General NewsPlus: The Pentagon is training amateurs to become part of its hacker army, a Flock license plate reader error led to cops surrounding a car reviewer, and more.
Security Latest – Read More
Critical Zimbra Flaw Could Let Crafted Emails Run Malicious Code in User Sessions
/in General NewsZimbra is urging customers to apply updates to address a critical security vulnerability impacting the Classic Web Client that could result in arbitrary code execution.
The vulnerability has been described as a case of stored cross-site scripting (XSS) that could allow specially crafted emails to execute malicious scripts in a user’s session. It has yet to be assigned a CVE identifier.
“The
The Hacker News – Read More
US cyber agency CISA had to build its incident playbook during the incident, agency reveals
/in General NewsCISA said it “missed” an opportunity to get ahead of the security incident by not creating a response plan ahead of time.
Security News | TechCrunch – Read More
Massive Telstra Outage Hits Mobile Networks, Rail, and Payments in Australia
/in General NewsA Telstra software defect disrupted mobile services, rail communications, payments, and emergency calls across Australia, exposing infrastructure risks.
The post Massive Telstra Outage Hits Mobile Networks, Rail, and Payments in Australia appeared first on TechRepublic.
Security Archives – TechRepublic – Read More