Social engineering: how scammers manipulate their victims | Kaspersky official blog
Unfortunately, it’s not just the gullible who fall for scams and phishing attacks anymore — literally anyone can become a victim today. Cybercriminals spend years honing their tactics to guarantee results, relying on sophisticated psychological manipulation that’s often hard to spot. In the cybersecurity world, these type of mind games even have their own name: social engineering.
In this article, we break down the psychological tricks scammers use to deceive their targets, the red flags you need to watch out for, and exactly what to do if you realize you’re being played.
The emotions scammers weaponize
Social engineering works precisely because it triggers our deepest emotions. When a victim is anxious, terrified, or caught up in the heat of the moment, they tend to make split-second decisions without thinking about the consequences. And that’s exactly what hackers are banking on.
That’s why, in such tense moment when you’re talking or texting with someone and they’re making demands, you need to pause for a second and ask yourself: “What exactly am I feeling right now? What was I feeling just a moment ago? Is this person trying to exploit my emotional state?”
Most of the time, scammers try to prey on these emotions:
- Fear and anxiety
- Excitement
- Shame and guilt
- Surprise and shock
First, verify who you’re actually dealing with
Before you even start looking for red flags, you need to check one basic thing: who are you actually talking to? If you’re chatting with, say, someone who claims to be a “bank representative”, your best bet is to look up the bank’s official phone number and email address online. Call them back or write to an address you know is 100% legitimate — it’s always better to be safe than sorry.
You should be especially on guard if someone reaches out to you on a messaging app or social media. As a rule, major companies simply don’t operate that way.
Dead giveaways you’re dealing with a scammer
They’re putting you on an emotional rollercoaster
Say you get an email from the “support team” of a streaming service you use. The message claims someone just tried to sign in to your account from another country — cue immediate panic. But then, they instantly soothe you: “Don’t worry, we blocked the suspicious sign-in attempt just in time. Your account is secure.”
The scammers don’t stop there, though. The very next paragraph plunges you right back into panic mode: “Unfortunately, during our security check, we discovered that your payment information may have been compromised.” Finally, they throw you a lifeline: “We are ready to help you fix this right now; just click this link to verify your identity.”
By the end of it, you’ve been yanked back and forth the entire minute you spent reading this “urgent update”. The goal of this emotional rollercoaster is to knock you off balance so that you stop thinking critically and just start reacting. And the moment the scammer swoops in with a supposed solution to the problem, your judgment goes completely out the window.
They know a little too much about you
Scammers will often deliberately bombard you with your own personal information just to make it seem like they really know what they’re talking about and have legitimate access to your sensitive data.
Just because the person on the other end happens to know details about your identity, finances, or contracts, doesn’t mean they aren’t a con artist. Thanks to endless data breaches, there’s a pretty massive digital dossier out there on almost all of us. It’s incredibly easy for a hacker to find out exactly how much you spent on grocery deliveries last year, who your cellphone carrier is, or what email address is associated with your bank account.
They try to scare you — sometimes with threats and extortion
Arguably, the easiest way to throw someone off balance is to strike fear into them or ramp up their anxiety. When offers that are too good to be true stop working, cybercriminals bust out the scare tactics: “Your account has been compromised”, “You will be charged with tax evasion unless you hand over your crypto wallet seed phrase”, “You will lose access to our services unless you call us right now”, or “You have been placed on a sex offender registry. Contact us to resolve this, or else we will press charges and leak your info to the media.” The list goes on.
Sometimes, these messages can seem totally emotionless, and perfectly mimic a real email from support. But if the tone is overly dramatic and you feel like you’re being cornered, the odds that you’re dealing with a scammer are close to 99.9%. And if they’re demanding you take action — like wire money to a random account, or hand over sensitive data — under the threat of physical harm, public shaming, or criminal charges — you can round that up to 100%.
To learn more about how extortionists operate, check out our post Email extortion: how scammers use blackmail.
An “extremely important person” is messaging you
To crank up the anxiety, scammers often sign their messages with the names of high-ranking officials. When this happens, take a breath and ask yourself: are you really sure the head of the IRS or the local police chief would personally call or text you? High-level officials and investigators usually have much bigger fish to fry. And if you’re being accused of some outrageous crime in a message signed by, say, the city’s chief prosecutor, that’s your cue to call their bluff.
You’re getting a too-good-to-be-true offer
Don’t fall for random acts of generosity or gifts that appear out of thin air. Here’s just a short list of what could happen to you:
- You get an unexpected package with a QR code printed on the box. They tell you to scan it — supposedly to find out who sent it, claim a free coupon from the seller, or confirm delivery so you don’t get stuck with a shipping fee. It’s not hard to guess that the QR code actually leads to a phishing site. From there, the scammers have a field day: they can trick you into handing over your card info, convince you to download an app that turns out to be malware, or get you to cough up a verification code for your banking app.
- “Hi! I’m calling from the delivery hub. You’ve got a package (or a bouquet of flowers) on the way. Could you please give me the verification code from the text message we just sent so you can claim your gift?” Look, everyone loves getting surprise gifts. But in the heat of the moment, it’s easy to let your guard down and accidentally hand the scammers a gift of your own — like the access code to your government services account.
- Talk about luck! All kinds of celebrities are announcing a free NFT giveaway that promises to make you a fortune. To claim your new crypto asset, you launch a mini-app, type in your details, and… boom, your Telegram account is gone. And looking back, those celebrity profiles pushing the giveaway did seem a little off…
They’re rushing you and trying to cut you off from the outside world
“Don’t hang up! This is your last chance to recover access to your account.” “If you do not reply to this email within eight hours, we will press criminal charges against you.” “You need to go to the bank immediately to save your remaining cash and deposit it into a secure account.” If similar phrases are used to spring you into immediate action, hit the brakes — the scammers are just trying to scare you and create a false sense of urgency.
This is a textbook tactic. Imagine getting a call from a scammer posing as a bank representative or even an official from the Department of Commerce, claiming your bank accounts have been hacked. They then ask you to sign a non-disclosure agreement — supposedly to help recover your money — and threaten legal action if you tell a soul, even your closest family members. They’ll insist the matter is “serious”, requires immediate action, and that cooperating with government agencies “must remain strictly confidential”.
Remember: legitimate company reps or government officials would never ask you to keep secrets unless you deal with classified government data or you’ve signed an actual corporate NDA. Scammers deliberately cut victims off from any support system, voice of reason, or outside opinion. And they don’t just isolate you from people; they cut you off from information entirely. They might intentionally keep you on the line or bombard you with emotionally charged texts, so you don’t even have a second to breathe, let alone look something up online.
When you’re in a state of high anxiety, it’s incredibly easy to fall for these manipulations and make reckless choices — even when you think you’re just trying to fix the problem. Never be afraid to reach out for help; getting a second opinion on what’s going on is always a smart move.
They try to shame you
Imagine getting a notification that your account has been compromised, and it ends with a prompt to contact support. But as the “support rep” looks into the issue, they simultaneously try to guilt-trip you: “When was the last time you changed your password? A while ago? Didn’t you see our urgent warnings to update your credentials?” or “Look, the text message literally says right there: do not share this code with anyone! Why on earth did you give it out?” This is a deliberate tactic to hook you with a sense of guilt, making you feel like you’ve lost control and need the scammer’s expertise and help.
Even if you actually did make a mistake, don’t beat yourself up. Falling for a scammer’s trap is much easier than you think — all it takes is one stressful day at work and a call coming in at the absolute worst moment.
You suddenly get a warning that you’ve been… talking to scammers
Scammers love using confusing, multi-stage schemes. For example, they might first try to trick you into giving up your banking app access code under the guise of updating your account information. But then, the call suddenly drops, or you get an immediate text warning you that you were just talking to a scammer, your account has been breached, and you need to contact support immediately for your own safety. Sometimes, self-proclaimed “federal agents” or “law enforcement officers” will even barge into the conversation.
The catch is that this “security team” is part of the same group of scammers keeping the con alive. They’ll start insisting that all your money is about to fall into criminal hands unless you move it to a “secure account”, or claim that someone has already taken out payday loans in your name.
Do not contact unfamiliar numbers or email addresses sent to you in messages — even if they promise to help. Find the company or agency’s legitimate website, look up their official contact channels, and use only those. Remember: no government agency — and certainly no private company — is wiretapping your phone to check if you’re talking to fraudsters.
What to do if you’ve fallen for a scam
First and foremost — don’t blame yourself. Anyone can be caught off guard and end up being tricked when they’re feeling vulnerable. Try not to panic, and think back to exactly what kind of information you handed over. Your next steps depend entirely on that:
- You gave out a text verification code or an account password → Immediately change your password for that service, as well as for any other accounts where you reused it. Turn on two-factor authentication if you haven’t already.
- You handed over your card details → Call your bank immediately and ask them to freeze your card. If money has already been withdrawn or wired from your account, ask how you can dispute the transaction.
- You clicked a suspicious link or downloaded a file from an unknown sender → Scan your device with a reliable antivirus. Trying to figure out on your own whether you’ve picked up malware is practically impossible, as it often hides on your device without showing any obvious signs.
Don’t listen to the scammers
Here’s how you can protect your accounts, data, and money:
- Take your time. If someone is rushing you to act immediately — enter your details, give up a code, or send money — you’re most likely talking to a cybercriminal. Hit pause, call the company back at the official number on their website, and check if they actually need anything from you.
- Outsource your fears to Kaspersky Premium. Unlike a human, our security suite is completely unbiased and spots phishing emails and malicious files right where a person might get flustered. It’ll block you from opening suspicious websites, stop attempts to infect your device, neutralize any discovered malware, and keep your data and money safe.
- Turn on two-factor authentication for your important accounts. With Kaspersky Password Manager, you can generate one-time login codes that change every 30 seconds — making them much harder for scammers to intercept than codes sent via email or text.
- Stick to the golden rule: never reuse a password. If you use the same password across different services, a hacker only needs to crack one account to automatically gain access to all the others. Variations like “Password123” and “Password1234!” won’t cut it either — minor tweaks like that are incredibly easy to guess. Of course, memorizing dozens or even hundreds of different passwords manually is a superhuman feat. That’s where a password manager comes in handy, safely storing your data in an encrypted vault and generating truly complex, unique passwords for you.
Check out our other posts for even more security tips:
Kaspersky official blog – Read More
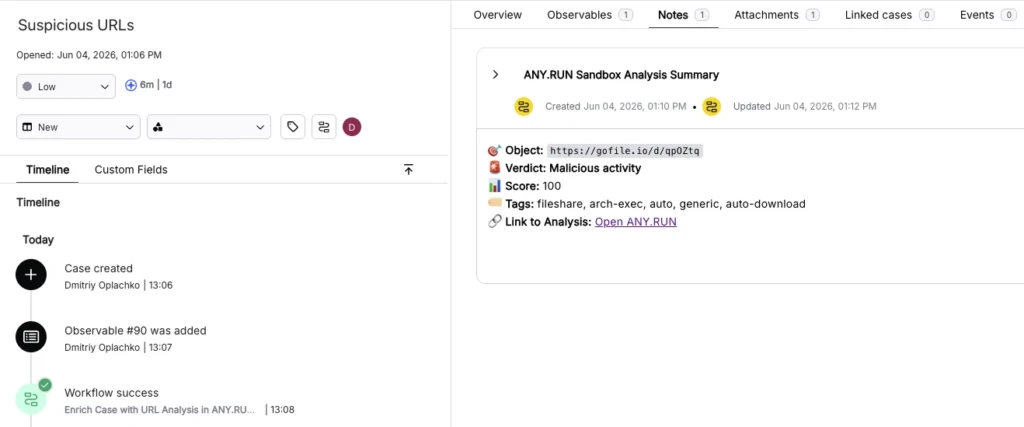
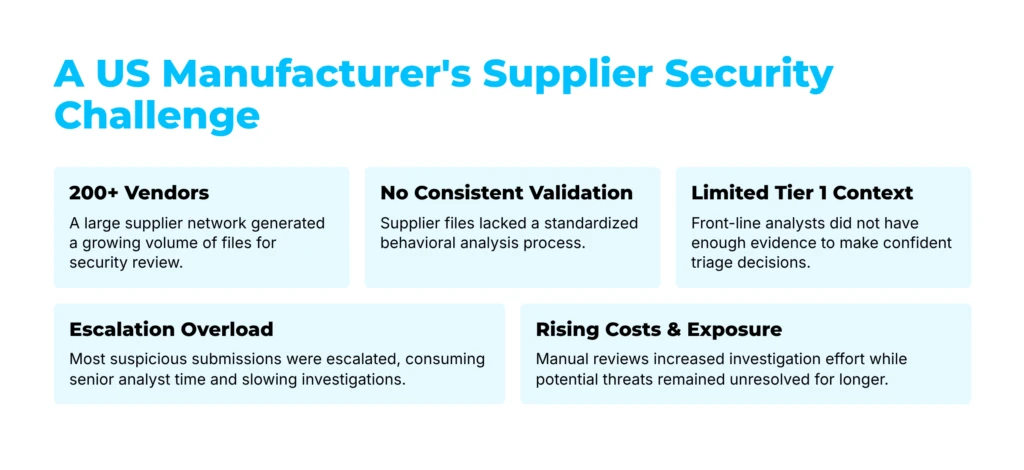
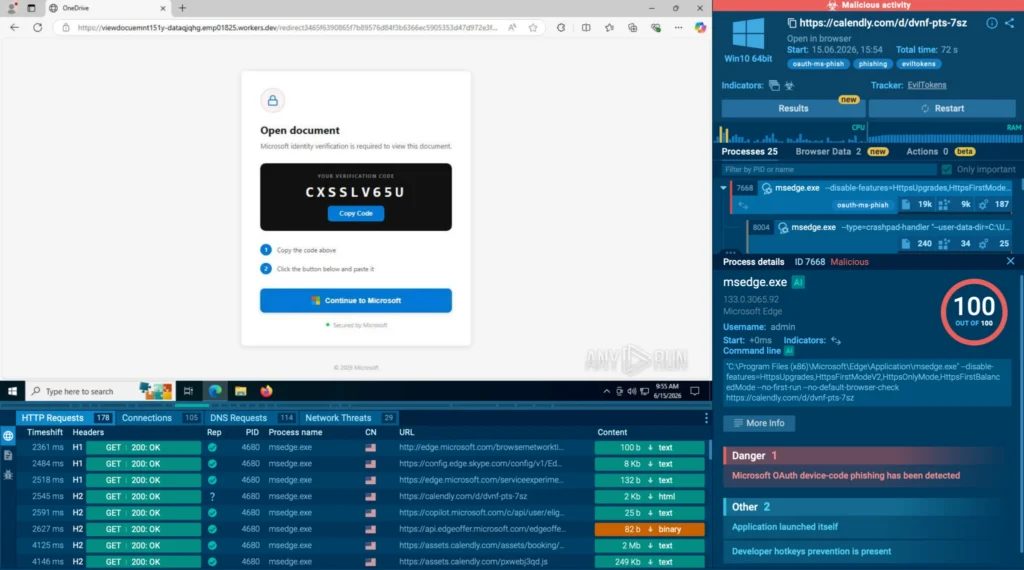
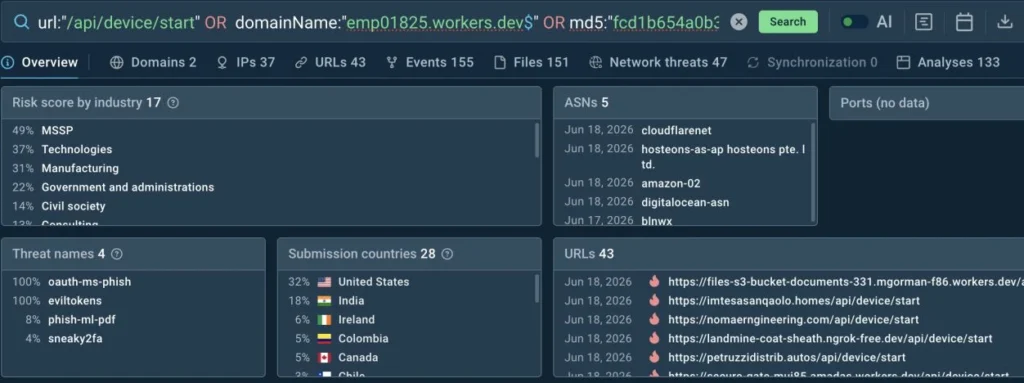
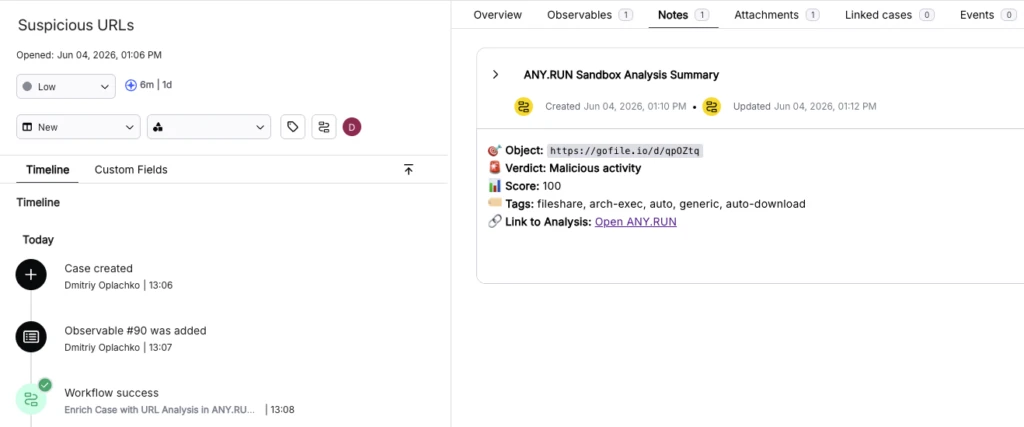
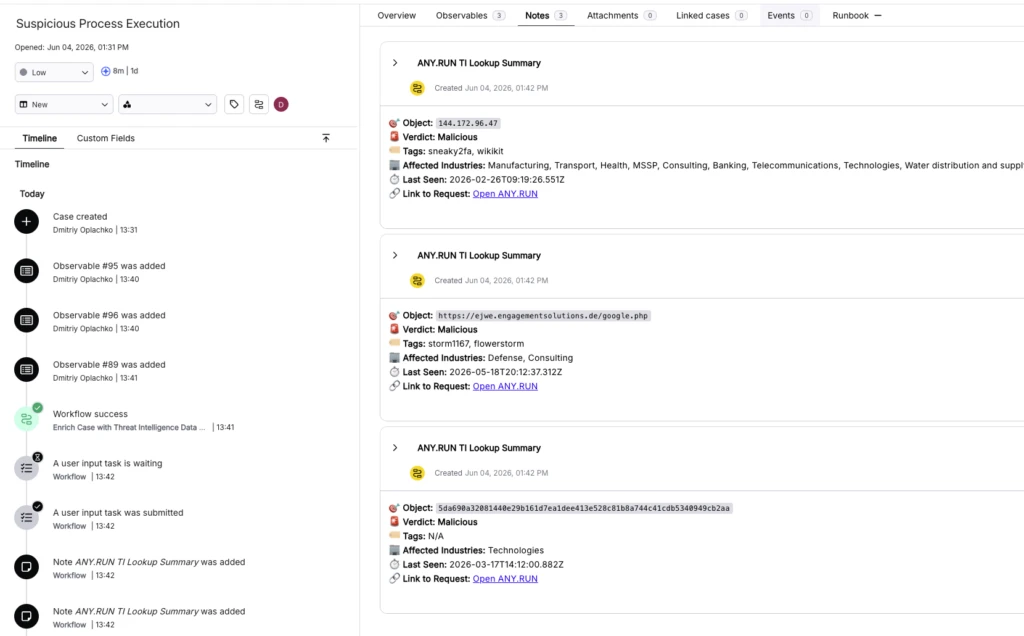
 covering two workflow types: case-based templates that pull observables straight from an open Torq case for enrichment, and standalone sandbox workflows that accept a URL or file as input and return a full verdict, IOC list, and report link anywhere in a custom automation chain. Results — reputation data, threat names, tags, and structured JSON — land directly in Torq Case Management, ready to branch on.
covering two workflow types: case-based templates that pull observables straight from an open Torq case for enrichment, and standalone sandbox workflows that accept a URL or file as input and return a full verdict, IOC list, and report link anywhere in a custom automation chain. Results — reputation data, threat names, tags, and structured JSON — land directly in Torq Case Management, ready to branch on.