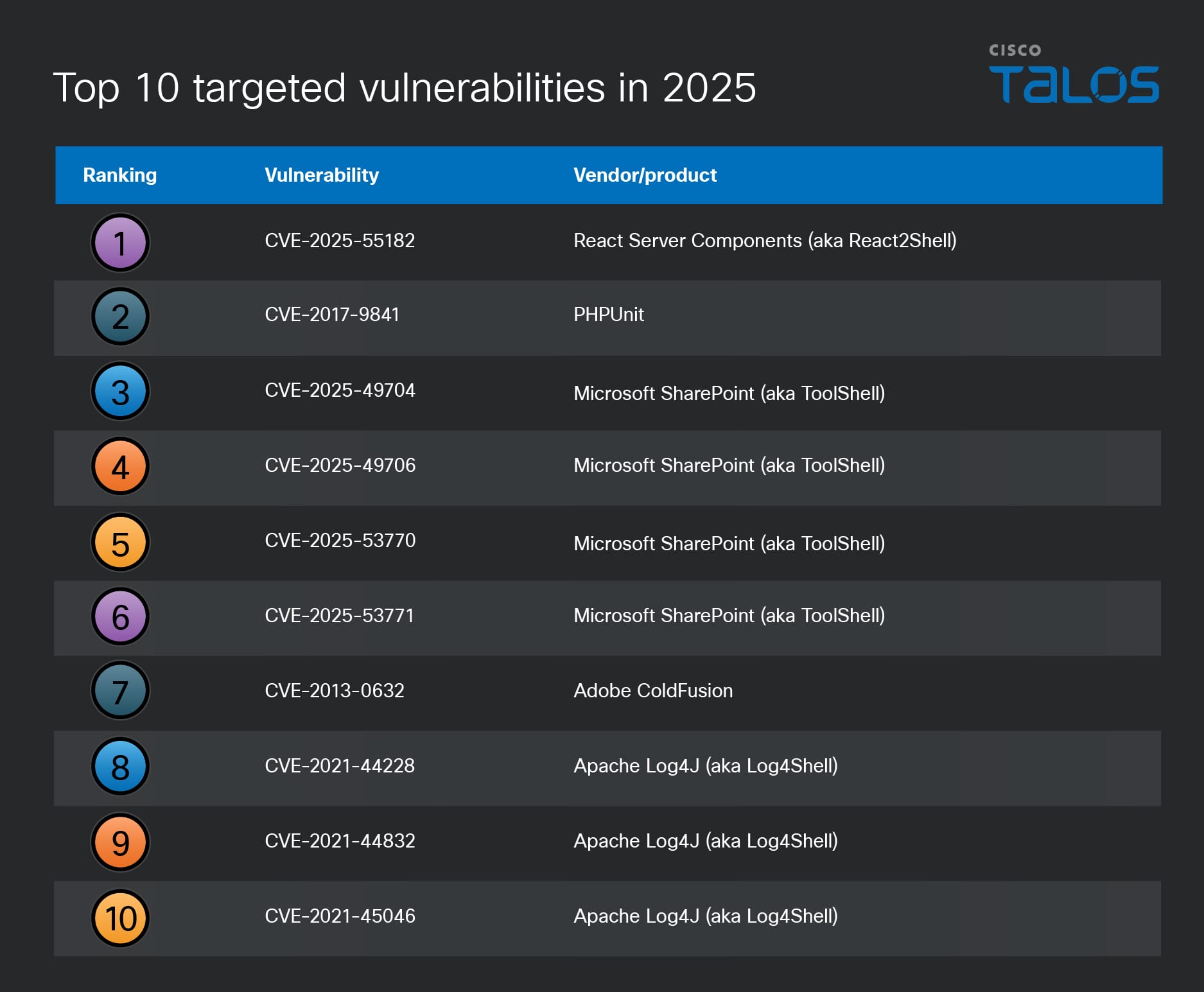
The dangers of telehealth: data breaches, phishing, and spam | Kaspersky official blog
April 7 marks World Health Day. The theme for 2026 is “Together for health. Stand with science” — a call to join forces in the fight for evidence-based medicine and scientific progress. Many people view telehealth as one of the crowning achievements of this progress: you can basically get a doctor’s consultation in five minutes without ever leaving your couch. But there’s a catch…
Medical data sells on the black or gray markets for dozens of times more than credit card info or social media logins. Unlike a credit card, which you can just block and replace, you can’t exactly reset your medical history. Your name, birthday, address, phone number, insurance ID, diagnoses, test results, prescriptions, and treatment plans stay relevant for years. This is a goldmine for everything from targeted marketing to blackmail, fraud, or identity theft.
And with the rise of AI, the internet is now flooded with fake websites that claim to offer medical services but are actually designed to strip-mine confidential info from unsuspecting victims. Today, we’re diving into which medical details are at risk, why hackers want them, and how you can stop them in their tracks.
More valuable than credit cards
Scammers monetize stolen medical data both in bulk and through individual sales. Their first move is usually to extort a ransom from the companies they’ve successfully hacked. (In fact, back in 2024, 91% of malware-related healthcare data leaks in the U.S. were the result of ransomware attacks.) But later, the leaked data is then used for pinpointed, personal attacks. It allows hackers to build a medical profile of a victim — what meds they buy, how often, and what they take long-term — to then sell that info to big pharma or marketers, or to use it for targeted phishing scams like pitching a fake innovative treatment. They can even blackmail a patient over a sensitive diagnosis or use the info to fraudulently score prescriptions for controlled substances. On top of that, insurance companies are also hungry for this kind of data. They analyze these details to hike up insurance premiums for patients or, in some cases, refuse to provide coverage altogether. In short, there are plenty of ways they can use it against you.
How bad is it really?
The biggest medical data breach in history went down in February 2024, when the BlackCat hacking group broke into the systems of Change Healthcare. This is a division of UnitedHealth Group, which processes around 15 billion insurance transactions a year and acts as the financial middleman between patients, healthcare providers, and insurance companies.
For nine days, the attackers roamed freely through Change Healthcare’s internal systems, siphoning off six terabytes of confidential data before finally launching their ransomware. UnitedHealth was forced to completely yank Change Healthcare datacenters offline to stop the encryptor from spreading, and they ended up paying a 22-million-dollar ransom to the extortionists. The attack effectively paralyzed the U.S. healthcare system. The number of victims was revised three times: first 100 million, then 190 million, and the final tally hit a staggering 192.7 million people, with total damages estimated at 2.9 billion dollars. And the reason (on the Change Healthcare’s side) for this massive incident — which we broke down in detail in a separate post — was simply… a lack of two-factor authentication on a remote desktop access portal.
Before that, the mental health telehealth startup Cerebral embedded third-party tracking tools directly into its website and apps. As a result, the data of 3.2 million patients — including names, medical and prescription histories, and insurance info — leaked out to LinkedIn, Snapchat, and TikTok. The U.S. Federal Trade Commission slapped the company with a 7.1-million-dollar fine, and issued an unprecedented ban on using medical data for advertising purposes. By the way, that same startup also made the headlines for sending its clients promotional postcards without envelopes, displaying patient names and phrasing that made it easy for anyone to figure out their diagnosis.
Why telehealth is so vulnerable
Let’s take a look at the main weak spots in telehealth services.
- Ad trackers in medical apps. Trackers from Facebook, TikTok, Snapchat, and other tech giants are often baked right into telehealth platforms, leaking patient data to advertisers without users ever knowing.
- Unsecured communication channels. Sometimes doctors chat with patients through regular messaging apps instead of certified medical platforms. It’s convenient, sure, but it’s illegal for the clinic and totally unsafe for the patient.
- Platform vulnerabilities. Telemedicine platforms are prone to classic web attacks, such as SQL injections that let hackers dump entire patient databases, session hijacking, and data interception when connection encryption is weak or nonexistent.
- Poor staff training. Our research showed that 30% of doctors have dealt with compromised patient data specifically during telehealth sessions, and 42% of medical staff don’t actually understand how their patients’ data is being protected.
- Outdated medical devices. Many wearable medical gadgets (like heart monitors or blood pressure cuffs) use an old data transfer protocol called MQTT. It’s full of holes that could potentially allow hackers to steal sensitive info or even mess with how the device functions.
Spam and phishing in telehealth
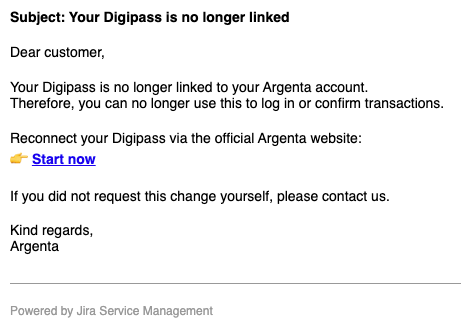
Hackers aren’t the only ones interested in the medical field — spammers and scammers are all over it, too. They pitch “medical services” with deals that look way too good to be true, send out emails about supposed changes to your health insurance, or talk up “ancient Himalayan healing traditions”. Of course, all the links they send lead to suspicious websites offering dubious goods or services.
-

- Spam posing as Medicare, the U.S. national health insurance program. The user is informed falsely that their insurance terms have changed in an attempt to lure them to a fake website

-

-
CURING DIABETES IS EASY: All you have to do is…Scammers are promoting some kind of miraculous Himalayan tradition for treating diabetes. But losing your money is the only thing guaranteed here!

-

- And of course, we can’t forget the classic “miracle cure” for a fungal infection — now with a 70% discount, naturally.

Should you land on such a phishing site, scammers will try to squeeze every bit of private info they can out of you: photos of your ID, insurance policy, prescriptions, and sometimes even… photos of body parts that supposedly need medical attention. From there, this data can be dumped and sold on the dark web — or used for blackmail, extortion, and follow-up phishing attacks. To learn more about how the underground data assembly line works, check out our post, What happens to data stolen using phishing?
-

- A fake clinic website with a pretty convincing look. Scammers even created pages for “medical staff”, “departments”, and “research”. However, for some reason, you won’t find a privacy policy or terms of use anywhere on this site

-

- Another suspicious website offers AI diagnostics, asking for a ton of personal info: full name, phone number, email, requested medical services, medical history, and current medications

-

- This scam site offers users “visual health screening using AI” — all you have to do is upload photos of your tongue and eyes! Just a reminder: retinal scans are sometimes used for biometric authentication

As a rule of thumb, fake clinic sites usually skip the privacy policy section, and bombard you with “today only” deals that seem too good to be true. That said, with the help of AI, creating a professional-looking site that’s indistinguishable from the real thing is now a total breeze: you don’t even need design skills or fluency in the victim’s language. That’s exactly why we recommend using our comprehensive security suite — it’s designed to sniff out spam, scams and phishing, and warn you about fake websites before you land on them.
Safety tips for telehealth patients
- Set up a dedicated email address for medical services. If this address leaks because a clinic gets hacked, it makes it much harder for scammers to track the rest of your digital life.
- Avoid using Google, Apple, or social media sign-in for telehealth sites. Keeping things separate makes it way tougher to link your medical data to your personal accounts.
- Double-check which platform is being used for your consultation. If the clinic suggests a call or chat through a standard messaging app, that’s a red flag. A secure, encrypted patient portal provided by the clinic is significantly safer.
- Never send medical documents via chat apps or social media. Always upload lab results, scans, and records through the clinic’s official patient portal.
- Use a unique, complex password for every account. Your government portal, clinic login, and doctor-booking app should each have a separate password. Kaspersky Password Manager can generate and store all of them for you; it also regularly scans leak databases, and alerts you if any of your accounts are compromised.
- Turn on two-factor authentication. Do this first of all for government services and medical organizations. We recommend using an authenticator app rather than SMS codes: it’s more secure and totally anonymous. Kaspersky Password Manager can help you out here, too.
- Share only what’s necessary. Don’t feel obligated to fill out every optional field in medical apps or on websites. The less data a service stores, the less there is to leak.
- Be careful about sharing health info on social media or in chat apps. Scammers love to exploit people when they’re vulnerable. For instance, in 2024, hackers gained the trust of the XZ Utils developer who had publicly posted about burnout and depression. They convinced him to hand over control of his tool, which they then loaded with malicious code. Since XZ Utils is used in tons of Linux systems and affects OpenSSH (a protocol for remote server connections), the attack could have wrecked a huge chunk of the internet if it hadn’t been caught in time.
- Don’t install telehealth apps from unknown developers. Check the reviews and take a minute to skim the privacy policy — even major platforms might be sharing your data with third parties.
- Keep an eye on your medical records. Strange prescriptions, doctor visits you never made, or meds you’ve never heard of can all be signs that your account has been compromised.
- Configure and regularly update your health gadgets. Fitness trackers, blood pressure monitors, smart scales, and activity trackers all send data to the web. Improper settings or unpatched vulnerabilities are an open door for data breaches.
What else you need to know about protecting your health online:
Kaspersky official blog – Read More