
DOGE Worker’s Code Supports NLRB Whistleblower
A whistleblower at the National Labor Relations Board (NLRB) alleged last week that denizens of Elon Musk’s Department of Government Efficiency (DOGE) siphoned gigabytes of data from the agency’s sensitive case files in early March. The whistleblower said accounts created for DOGE at the NLRB downloaded three code repositories from GitHub. Further investigation into one of those code bundles shows it is remarkably similar to a program published in January 2025 by Marko Elez, a 25-year-old DOGE employee who has worked at a number of Musk’s companies.
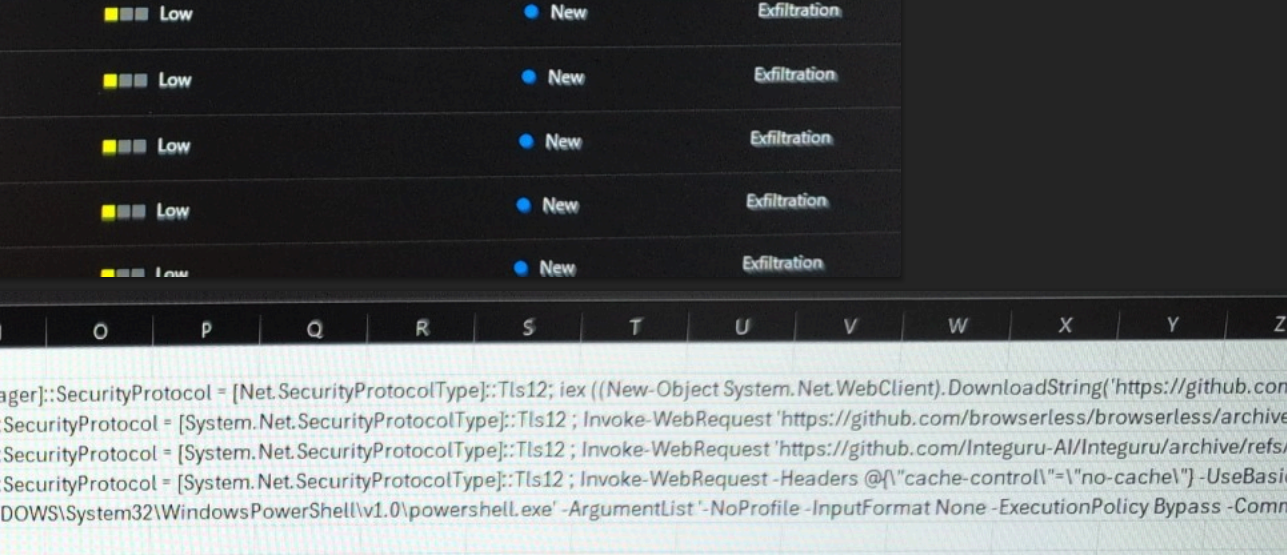
A screenshot shared by NLRB whistleblower Daniel Berulis shows three downloads from GitHub.
According to a whistleblower complaint filed last week by Daniel J. Berulis, a 38-year-old security architect at the NLRB, officials from DOGE met with NLRB leaders on March 3 and demanded the creation of several all-powerful “tenant admin” accounts that were to be exempted from network logging activity that would otherwise keep a detailed record of all actions taken by those accounts.
Berulis said the new DOGE accounts had unrestricted permission to read, copy, and alter information contained in NLRB databases. The new accounts also could restrict log visibility, delay retention, route logs elsewhere, or even remove them entirely — top-tier user privileges that neither Berulis nor his boss possessed.
Berulis said he discovered one of the DOGE accounts had downloaded three external code libraries from GitHub that neither NLRB nor its contractors ever used. A “readme” file in one of the code bundles explained it was created to rotate connections through a large pool of cloud Internet addresses that serve “as a proxy to generate pseudo-infinite IPs for web scraping and brute forcing.” Brute force attacks involve automated login attempts that try many credential combinations in rapid sequence.
A search on that description in Google brings up a code repository at GitHub for a user with the account name “Ge0rg3” who published a program roughly four years ago called “requests-ip-rotator,” described as a library that will allow the user “to bypass IP-based rate-limits for sites and services.”
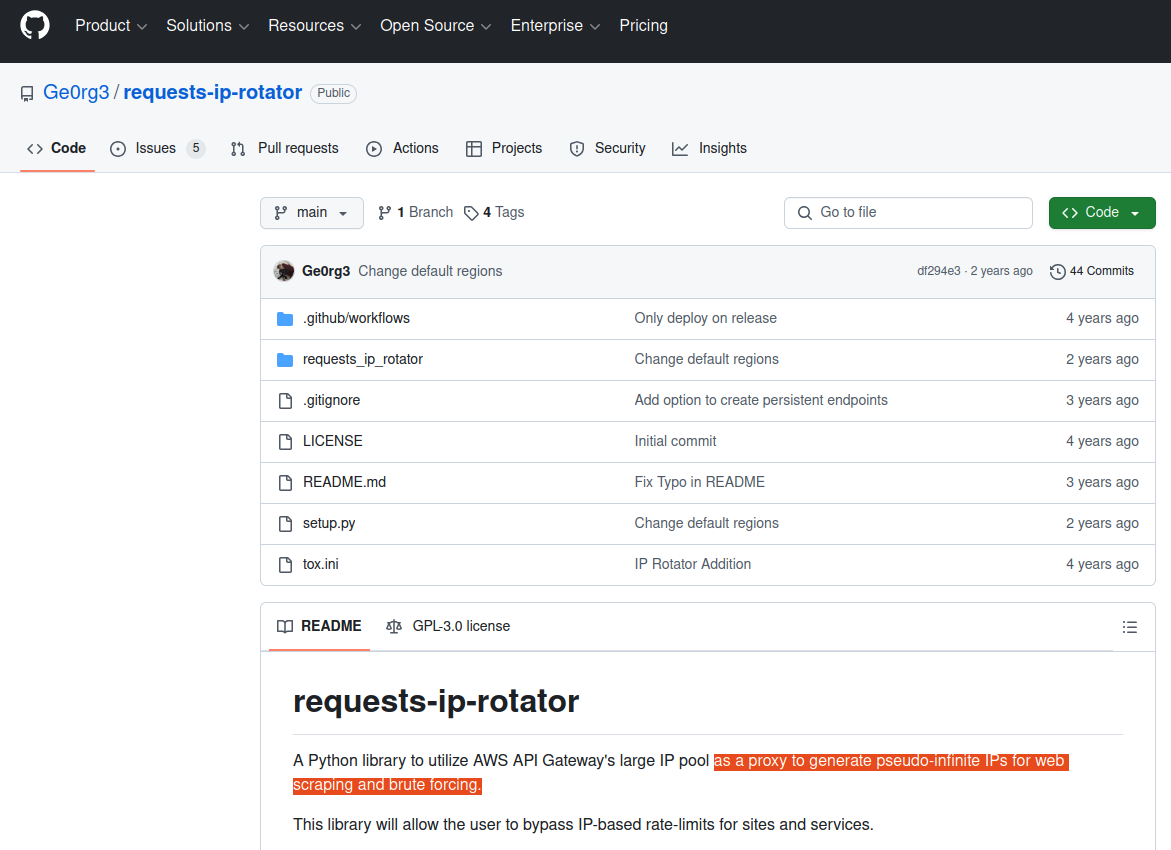
The README file from the GitHub user Ge0rg3’s page for requests-ip-rotator includes the exact wording of a program the whistleblower said was downloaded by one of the DOGE users. Marko Elez created an offshoot of this program in January 2025.
“A Python library to utilize AWS API Gateway’s large IP pool as a proxy to generate pseudo-infinite IPs for web scraping and brute forcing,” the description reads.
Ge0rg3’s code is “open source,” in that anyone can copy it and reuse it non-commercially. As it happens, there is a newer version of this project that was derived or “forked” from Ge0rg3’s code — called “async-ip-rotator” — and it was committed to GitHub in January 2025 by DOGE captain Marko Elez.

The whistleblower stated that one of the GitHub files downloaded by the DOGE employees who transferred sensitive files from an NLRB case database was an archive whose README file read: “Python library to utilize AWS API Gateway’s large IP pool as a proxy to generate pseudo-infinite IPs for web scraping and brute forcing.” Elez’s code pictured here was forked in January 2025 from a code library that shares the same description.
A key DOGE staff member who gained access to the Treasury Department’s central payments system, Elez has worked for a number of Musk companies, including X, SpaceX, and xAI. Elez was among the first DOGE employees to face public scrutiny, after The Wall Street Journal linked him to social media posts that advocated racism and eugenics.
Elez resigned after that brief scandal, but was rehired after President Donald Trump and Vice President JD Vance expressed support for him. Politico reports Elez is now a Labor Department aide detailed to multiple agencies, including the Department of Health and Human Services.
“During Elez’s initial stint at Treasury, he violated the agency’s information security policies by sending a spreadsheet containing names and payments information to officials at the General Services Administration,” Politico wrote, citing court filings.
KrebsOnSecurity sought comment from both the NLRB and DOGE, and will update this story if either responds.
The NLRB has been effectively hobbled since President Trump fired three board members, leaving the agency without the quorum it needs to function. Both Amazon and Musk’s SpaceX have been suing the NLRB over complaints the agency filed in disputes about workers’ rights and union organizing, arguing that the NLRB’s very existence is unconstitutional. On March 5, a U.S. appeals court unanimously rejected Musk’s claim that the NLRB’s structure somehow violates the Constitution.
Berulis’s complaint alleges the DOGE accounts at NLRB downloaded more than 10 gigabytes of data from the agency’s case files, a database that includes reams of sensitive records including information about employees who want to form unions and proprietary business documents. Berulis said he went public after higher-ups at the agency told him not to report the matter to the US-CERT, as they’d previously agreed.
Berulis told KrebsOnSecurity he worried the unauthorized data transfer by DOGE could unfairly advantage defendants in a number of ongoing labor disputes before the agency.
“If any company got the case data that would be an unfair advantage,” Berulis said. “They could identify and fire employees and union organizers without saying why.”

Marko Elez, in a photo from a social media profile.
Berulis said the other two GitHub archives that DOGE employees downloaded to NLRB systems included Integuru, a software framework designed to reverse engineer application programming interfaces (APIs) that websites use to fetch data; and a “headless” browser called Browserless, which is made for automating web-based tasks that require a pool of browsers, such as web scraping and automated testing.
On February 6, someone posted a lengthy and detailed critique of Elez’s code on the GitHub “issues” page for async-ip-rotator, calling it “insecure, unscalable and a fundamental engineering failure.”
“If this were a side project, it would just be bad code,” the reviewer wrote. “But if this is representative of how you build production systems, then there are much larger concerns. This implementation is fundamentally broken, and if anything similar to this is deployed in an environment handling sensitive data, it should be audited immediately.”
Further reading: Berulis’s complaint (PDF).
Krebs on Security – Read More

