Back when ransomware was just a startup industry, the primary goal of the attackers was simple: encrypt data, then extort a ransom in exchange for decrypting it. Because of this, cybercriminals mostly targeted commercial enterprises — companies that valued their data enough to justify a hefty payout. Schools and colleges were generally left alone — hackers assumed educators didn’t have the kind of data worth paying a ransom for.
But times have changed, and so has the ransomware groups’ business model. The focus has shifted from payment for decryption, to extortion in exchange for non-disclosure of stolen data. Now, the “incentive” to pay isn’t just about restoring the company’s normal operations, but rather avoiding regulatory trouble, potential lawsuits, and reputational damage. And it’s this shift that’s put educational institutions in the crosshairs.
In this post, we discuss several cases of ransomware attacks on educational organizations, why they took place, and how to keep cybercriminals out of the classroom.
Attacks on educational institutions in 2025–2026
In February 2026, the Sapienza University of Rome, one of Europe’s oldest and largest higher education institutions, suffered a ransomware attack. Internal systems were down for three days. According to sources familiar with the incident, the cybercriminals sent the university’s administration a link leading to a ransom demand. Upon clicking the link, a countdown timer started on the site that opened — counting down from 72 hours: the time the attackers demands needed to be met. As of now, there’s still no word on whether the university administration paid up or not.
Unfortunately, this case isn’t an exception. At the very end of 2025, attackers targeted another Italian educational institution — a vocational training center in the small city of Treviso. Things aren’t looking much better in the UK, either: in the same year, Blacon High School was hit by ransomware. Its administration had to shut its doors for two days to restore its IT systems, assess the scale of the incident, and prevent the attack from spreading further through the network.
In fact, a UK government study suggests these incidents are just part of a broader trend. According to its 2025 data, cyberincidents hit 60% of secondary schools, 85% of colleges, and 91% of universities. Across the pond, American researchers also noted that in the first quarter of 2025, ransomware attacks in the global education sector surged by 69% year on year. Clearly, the trend is global.
Why schools and universities are becoming easy targets
The core of the problem is that modern educational organizations are rapidly incorporating digital services into their operations. A typical school or university infrastructure now manages a dizzying array of services:
Electronic gradebooks and registers
Distance learning platforms
Admission systems and databases for storing applicants’ personal data
Cloud storage for educational materials
Internal staff and student portals
Email for faculty, students, and the administration to communicate
While these systems make education more convenient and manageable, they also drastically expand the attack surface. Every new service and every additional user account is a potential doorway for a phishing campaign, access compromise, or a personal data leak.
According to a UK study, the primary vector for these attacks is basic phishing. But that’s not all that surprising: since the education sector was off the cybercriminals’ radar for so long, cybersecurity training for both staff and students was hardly a priority. As a result, even the most seasoned professors can find themselves falling for a fake email purportedly sent by the “dean” or the “school principal”.
But it’s not just the faculty. Students themselves often unwittingly act as mules for malware. In many institutions, students still frequently hand in assignments on USB flash drives. These drives travel across various home or public devices, picking up malicious digital hitchhikers along the way. All it takes is one infected USB drive plugged into a campus workstation to give an attacker a foothold in the internal network.
It’s worth noting that while USB drives aren’t as ubiquitous as they were a decade ago, they remain a staple in the educational environment. Dismissing the threats they carry isn’t a good idea.
How to ensure the cybersecurity of educational infrastructure
Let’s face it: training every literature and biology teacher to spot phishing emails is now easy, quick task. Similarly, the educational system isn’t going to cut down on USB usage overnight.
Fortunately, a robust security solution (such as Kaspersky Small Office Security) can do the heavy lifting for you. It’s ideal for schools and colleges that need set-it-and-forget-it protection without a steep learning curve. Plus, it’s affordable even for institutions operating on a tight budget, and doesn’t require constant management.
At the same time, Kaspersky Small Office Security addresses all the threats we’ve discussed above: it blocks clicks on phishing links, automatically scans USB drives the moment they’re plugged in, and prevents suspicious files from executing on devices connected to the school’s network.
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2026-03-07 05:06:332026-03-07 05:06:33Ransomware attacks on schools and colleges | Kaspersky official blog
The ability to continue operating safely in an unsafe environment where competitors cannot is a competitive advantage that is rarely measured or discussed
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2026-03-07 02:06:352026-03-07 02:06:35What cybersecurity actually does for your business
Welcome to this week’s edition of the Threat Source newsletter.
It’s time to look back at a year that pushed the vulnerability landscape to new heights. I’ll admit this retrospective is arriving a bit later than planned. With 48,196 CVEs in 2025 (a stunning 132 vulnerabilities per day), the analysis takes time — especially when you’re operating one-handed after an encounter with black ice breaks your dominant arm. But better thorough than rushed, right?
What concerns me more than the sheer volume is what’s inside these CVEs. XSS, SQL injection, and deserialization vulnerabilities continue to dominate, accounting for roughly 10,000 CVEs. Despite decades of awareness, these fundamental software security weaknesses persist.
The Known Exploited Vulnerabilities (KEV) Catalog tells an even more sobering story. With 241 KEVs in 2025 compared to 186 in 2024, we saw a 30% increase in confirmed active exploitation.
94 KEVs (39%) added in 2025 originated from CVE-2024 and earlier. We saw actively exploited vulnerabilities from as far back as 2007 — yes, vulnerabilities old enough to vote in some countries are still causing problems today. Patch management must address legacy systems. It starts with visibility: maintaining accurate asset inventories and understanding what’s actually running in your environment. For those systems that truly can’t be patched, whether due to operational constraints or vendor abandonment, compensating controls become essential. Microsegmentation, network isolation, and enhanced monitoring can reduce the radius of damage when (not if) something goes wrong.
With 54 KEVs targeting firewalls, VPNs, and other network appliances, we saw network infrastructure take a disproportionate hit. And the vendor landscape in KEVs expanded to 99 vendors in 2025, up from 79 when I last checked in October. Connect that with supply chain complexity and the patch management visibility challenges I mentioned earlier, and you’ll quickly realize why security teams are spending more time — not less — on vulnerability management. Every additional vendor in your environment is another patch cycle to track, another advisory to monitor, another potential weak link in the chain.
This is the first time I’ve attempted to systematically track AI-related vulnerabilities in the CVE data, and the methodology is still evolving. Defining what constitutes an “AI vulnerability” isn’tstraightforward. For this initial pass, I searched for CVEs containing specific keywords across several categories:
ChatGPT, GPT-3, GPT-4, OpenAI, Anthropic, Claude Code
AI Concepts
prompt injection, large language model, Model Context Protocol
Using this approach, AI-related CVEs nearly doubled year-over-year, jumping from 168 to 330. Notably, “Model Context Protocol (MCP)” and “Claude” didn’t appear in 2024 data at all.
A word of caution: While CVE data provides valuable insight into disclosed vulnerabilities in AI tools and frameworks, it doesn’t capture emergent risks such as jailbreaking, hallucination-based misinformation, training data extraction, or model inversion attacks. See https://genai.owasp.org/llm-top-10/ and https://atlas.mitre.org/ if you want to learn more.
Keep tracking, keep patching, and stay tuned for the 2025 Year in Review for more trend analysis.
The one big thing
Cisco Talos continues tomonitor the ongoing conflict in the Middle East. At this time we have not seen any significant cyber impacts, with some small incidents such as web defacements and small-scale distributed-denial-of-service (DDoS) attacks occurring. As with any highly fluid or dynamic situation, we are focused on providing our customers with highly accurate and timely intelligence and information. We will remain vigilant looking to identify any cyber related activity relevant to the region.
Why do I care?
Currently there does not appear to be any significant increase in cyber activity associated with state-sponsored or state-affiliated groups. However, cyber criminals are likely to take advantage of the war to try and increase their scope of infections through the use of lures and other social engineering avenues.
So now what?
Recommendations for organizations are currently focused on security hygiene, to include having multi-factor authentication (MFA) enabled, being diligent around any links or documents that are circulating, and ensuring you have proper monitoring in place to ensure you are prepared for any collateral impacts as they arise. Additional inspection or controls may be warranted to insulate potential larger impacts to the wider organization. Warn employees against clicking on unsolicited links related to the Middle East conflict, whether news or humanitarian. As always, ensure all software has been updated to the latest versions to minimize the attack surface and ensure you have a robust patching process.
If and/or when more relevant information becomes available, we will update this blog accordingly.
Top security headlines of the week
Hackers steal medical details of 15 million in France France’s health ministry has confirmed a data breach involving the exposure of administrative information for 15.8 million patients and sensitive doctors’ notes for approximately 165,000 individuals. (France 24)
Google addresses actively exploited Qualcomm zero-day The memory-corruption vulnerability (CVE-2026-21385) which Google’s Androidsecurity team reported to Qualcomm Dec. 18, affects 234 chipsets, Qualcomm said in a security bulletin. (CyberScoop)
Quantum decryption of RSA may be much closer than expected The Advanced Quantum Technologies Institute announced that the JVG algorithm requires thousand-fold less quantum computer resources, and “research extrapolations suggest it will require less than 5,000 qubits to break encryption methods used in RSA and ECC.” (SecurityWeek)
Indian APT “Sloppy Lemming” targets defense, critical infrastructure The group has evolved from using off-the-shelf red teaming tools like Cobalt Strike and Havoc C2 to developing its own custom tooling written in Rust, while expanding its C2 infrastructure (DarkReading)
Can’t get enough Talos?
UAT-9244 targets South American telecommunication providers Since 2024, UAT-9244 has targeted critical telecommunications infrastructure, including Windows and Linux-based endpoints and edge devices in South America, proliferating access via three malware implants.
In early February 2026, Cyble Research & Intelligence Labs (CRIL) identified a new Linux malware strain delivered through a loader structure previously associated with ShadowHS activity. While ShadowHS samples deployed post-exploitation tooling, the newly observed payload is operationally different. We have named it ClipXDaemon, an autonomous cryptocurrency clipboard hijacker targeting Linux X11 environments.
At the time of this writing, there is no evidence that ShadowHS and ClipXDaemon originate from the same malware author or campaign. The structural overlap in the loader stems from the use of bincrypter, an open-source shell-script encryption framework hosted on GitHub. Both campaigns appear to have leveraged this public tool independently.
ClipXDaemon differs fundamentally from traditional Linux malware. It contains no command-and-control (C2) logic, performs no beaconing, and requires no remote tasking. Instead, it monetizes victims directly by hijacking cryptocurrency wallet addresses copied in X11 sessions and replacing them in real time with attacker-controlled addresses.
It employs stealth techniques, including process masquerading and Wayland session avoidance, in which the attack chain operates entirely locally, without network communication, infrastructure, or operator interaction after execution, making detection and response significantly more challenging.
The campaign is particularly relevant now, given the growing adoption of Linux among developers, traders, and crypto users, many of whom rely on X11-based GUI environments. This represents an evolution in Linux financial malware: autonomous, C2-less, stealthy, and user-focused.
Key Takeaways
The previously observed ShadowHS-style loader is reused to deploy a different payload — a Linux X11 cryptocurrency clipboard hijacker.
The campaign uses a three-stage infection chain:
Encrypted loader
Memory-resident dropper
On-disk ELF clipboard hijacker
The Dropper is entirely staged in memory via a bincrypter-generated loader that uses AES-256-CBC decryption and gzip decompression.
The malware avoids modern Wayland sessions and operates exclusively in X11 environments, demonstrating intentional defense evasion.
Implements stealth techniques including double-fork daemonization, /proc masquerading, and PR_SET_NAME process renaming.
The payload is a fully autonomous daemon that monitors the clipboard every 200ms and replaces cryptocurrency addresses with attacker-controlled wallets, targeting Bitcoin, Ethereum, Litecoin, Monero, Tron, Dogecoin, Ripple, and TON wallets.
Encrypted regex is ChaCha20-based, with embedded static keys and 64-byte block decryption, ensuring payload secrecy.
Payload is autonomous with no communication with external C2 (functions entirely locally), relying only on clipboard replacement for monetization.
Persistence is achieved via ~/.profile modification.
The campaign illustrates increasing operational reliance on open-source tooling in modern malware development.
Background & Threat Landscape
The ShadowHS malware family, documented in January 2026, used encrypted shell loaders to execute an in-memory, weaponized hackshell payload targeting server environments and was associated with post-exploitation tooling.
ClipXDaemon reflects a strategic pivot. While the staging wrapper remains structurally similar, the delivered payload is entirely different: an autonomous cryptocurrency clipboard hijacker focused on Linux users.
Both ShadowHS samples and ClipXDaemon leverage the publicly available bincrypter framework to encrypt and wrap shell payloads. However, the reuse of a commodity open-source obfuscation tool does not constitute evidence of actor overlap. This indicates a broader trend where attackers are increasingly weaponizing legitimate open-source utilities to reduce development overhead.
This case illustrates several macro-level shifts in the threat landscape. Linux malware is becoming more specialized, targeting financial workflows directly rather than deploying general-purpose remote access tools.
Operational exposure is minimized by eliminating network communication entirely. Modular reuse of publicly available encryption wrappers allows rapid payload swapping without rebuilding infrastructure.
ClipXDaemon therefore represents both a tactical evolution in Linux clipboard hijacking and a strategic example of open-source tool weaponization in financially motivated campaigns.
Technical Analysis
Bincrypt Obfuscated Loader
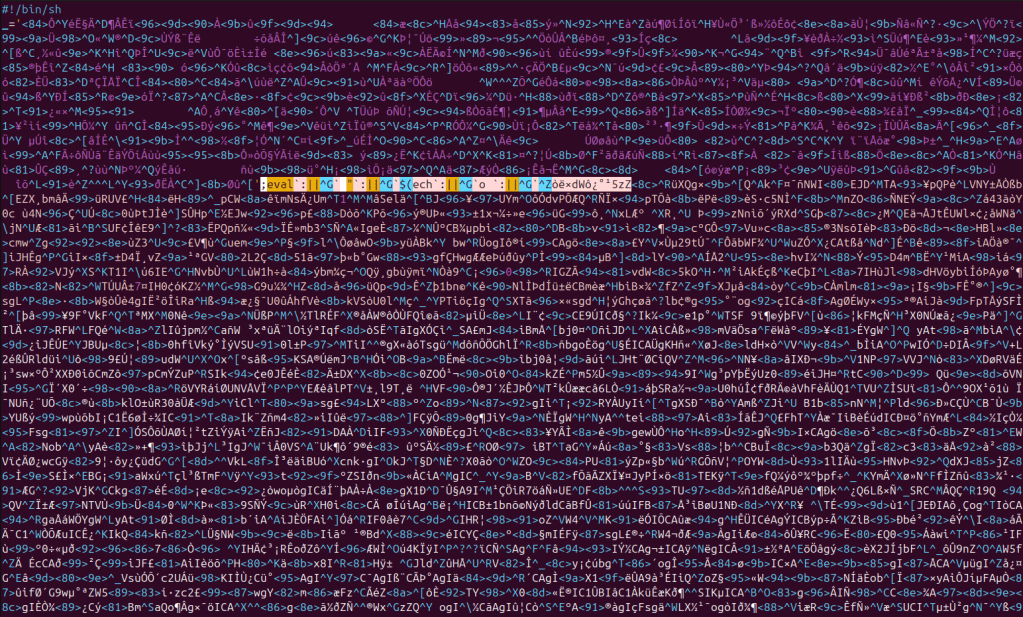
The initial loader used in this campaign matches the structural output generated by bincrypter. The wrapper script stores an encrypted payload blob inline, base64-decodes it at runtime, strips non-printable characters, derives AES-256-CBC decryption parameters, decompresses via gzip, and executes the decrypted stage directly from memory. (See Figure 1)
Figure 1 – Bincrypt Obfuscated Loader
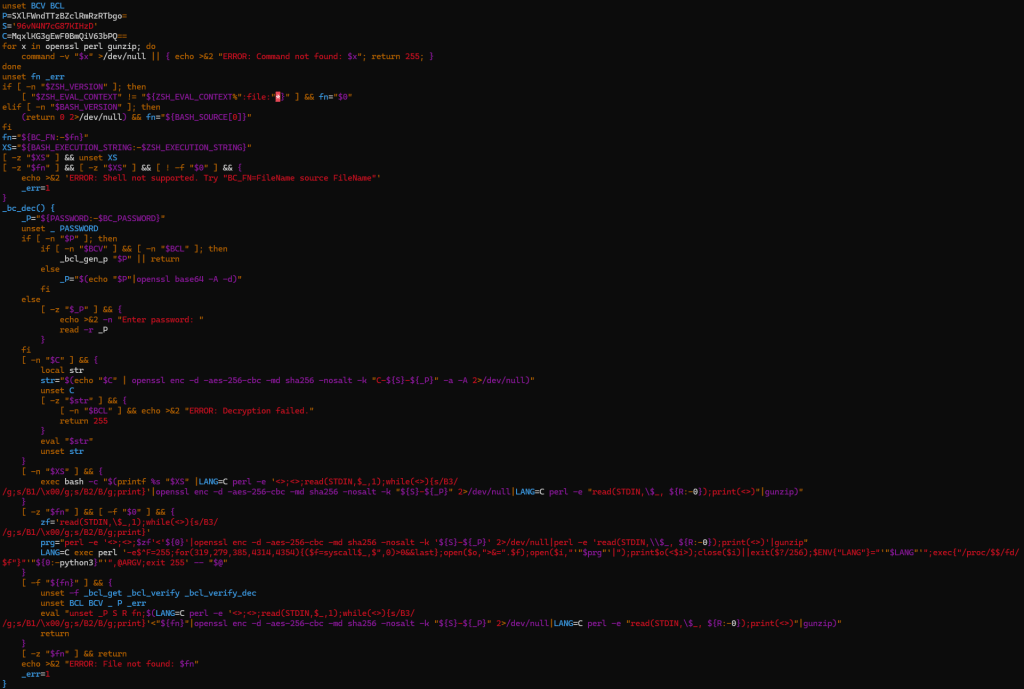
The decryption stub, variable naming conventions (short uppercase variables such as P and S), OpenSSL invocation pattern, and execution via /proc/self/fd align with bincrypter-generated output. When replicated in a controlled environment using bincrypter, the structural characteristics match closely. (See Figure 2)
Figure 2 – Deobfuscated Loader Stub
However, the presence of bincrypter does not imply shared authorship between ShadowHS and ClipXDaemon. Bincrypter is a public, open-source tool. Its reuse reflects convenience and operational efficiency rather than coordinated campaign lineage.
The same loader logic is retained across versions. Differences are confined to the embedded base64 password (P), the salt (S), the encrypted configuration blob (C), the payload offset (R), and the derived AES key.
Component
ShadowHS loader
ClipXDaemon loader
P (base64)
U014VW9KeTh5SGhtSXR2QQo=
SXlFWndTTzBZclRmRzRTbgo=
Decoded Password
SMxUoJy8yHhmItvA
IyEZwSO0YrTfG4Sn
Salt (S)
92KemmzRUsREnkdk
96vN4N7cG87KIHzD
C (encrypted config)
S1A76XhLvaqIQ+7WsT+Euw==
MqxlKG3gEwF0BmQiV63bPQ==
R (offset)
4817
7452
Final AES key
92KemmzRUsREnkdk-SMxUoJy8yHhmItvA
96vN4N7cG87KIHzD-IyEZwSO0YrTfG4Sn
This indicates that the loader functions as a reusable staging framework, with payloads swapped at build time rather than behavioral modification.
In-Memory Dropper Execution
Once the loader decrypts and decompresses an intermediate dropper, it does not write the script to disk. Instead, it executes it directly through a file descriptor under /proc/self/fd. This avoids static inspection of the decrypted stage and minimizes disk artifacts.
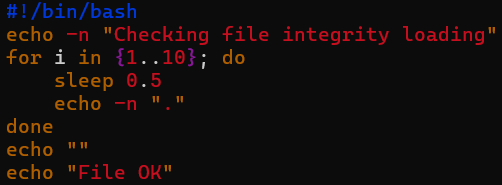
Upon execution, the decrypted dropper writes a message to STDOUT for purely cosmetic purposes, thereby disguising itself as legitimate software. (See Figure 3)
Figure 3 – Dropper Cosmetics
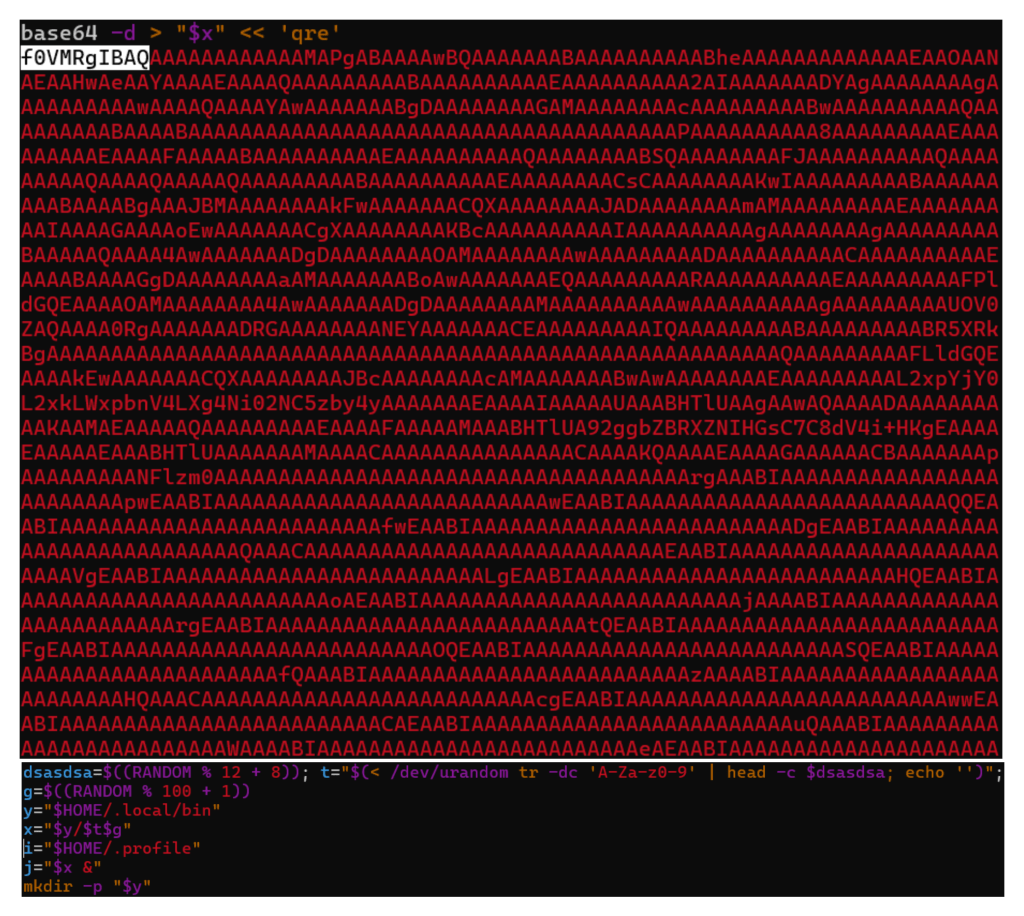
Subsequently, it contains an embedded base64-encoded ELF binary, which is decoded & written to a file with a randomized name (between eight and nineteen characters, with a numeric suffix). (See Figure 4)
Figure 4 – Base64 Encoded ELF payload with randomized name
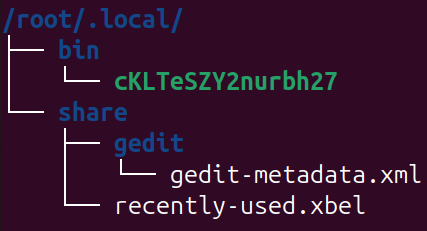
The ELF binary is dropped at ~/.local/bin/<random_name>. The path selection is deliberate, considering that it resides in userland, requires no elevated privileges, and allows blending with legitimate user-installed binaries. (See Figure 5)
Figure 5 – Dropped Payload
Persistence
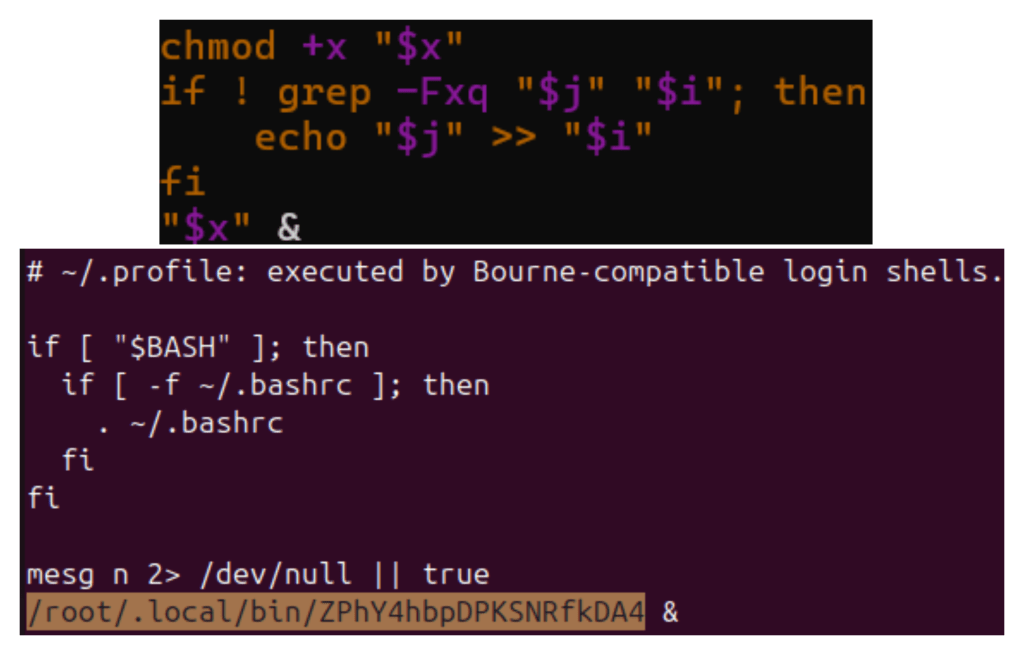
After writing the file, the dropper marks it executable, launches it in the background, and appends an execution line to ~/.profile. (See Figure 6)
Figure 6 – Persistence Mechanism
By modifying ~/.profile, the implant ensures it is executed during future interactive login sessions. This is a user-level persistence mechanism that does not require cron jobs, systemd services, or root access. This indicates that the targeting profile is more consistent with Linux environments than with servers.
Payload Architecture: X11-Dependent Design
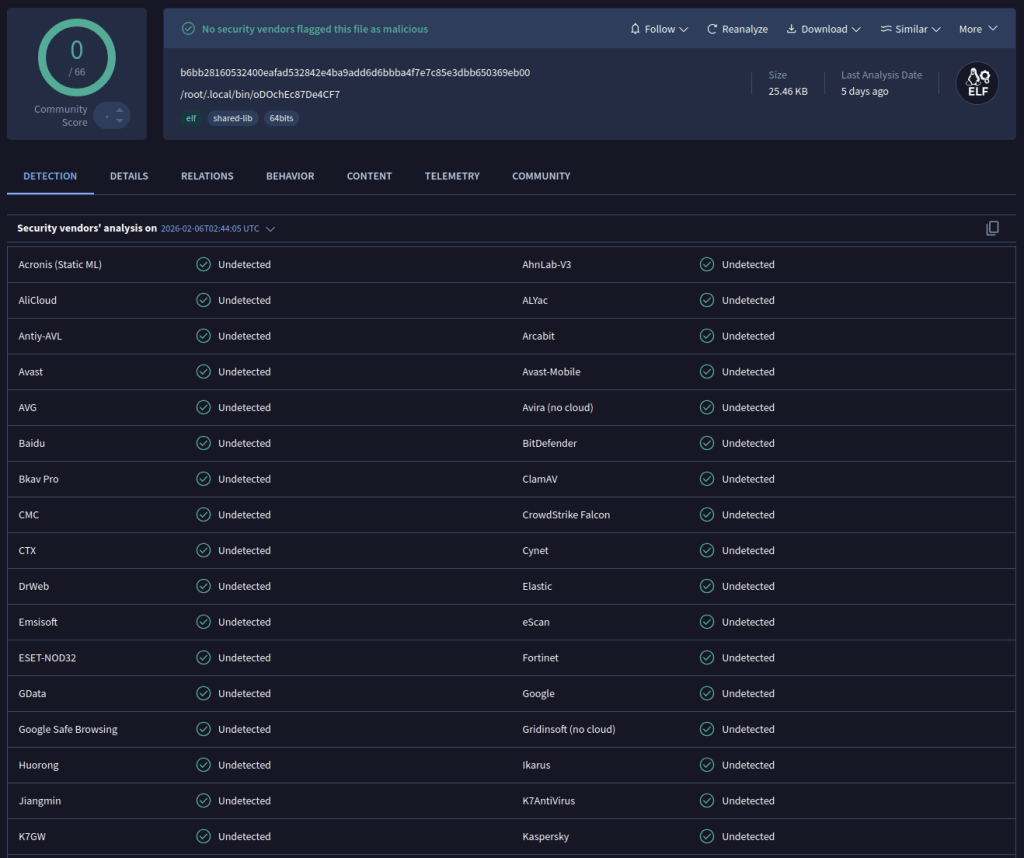
The deployed ELF binary is a 64-bit Linux executable dynamically linked against X11 libraries. At the time of writing, it goes undetected by security vendors on VirusTotal. (See Figure 7)
Figure 7 – Persistence Mechanism
Execution begins with a simple environmental gate: the program checks whether the WAYLAND_DISPLAY environment variable is present.
If Wayland is detected, execution terminates immediately.
If Wayland is absent, execution proceeds.
This is done because Wayland’s design prevents global clipboard scraping as X11 allows. By explicitly disabling itself in Wayland sessions, it avoids runtime failure and reduces noise. This indicates that the implant is designed specifically for X11. This environmental awareness indicates familiarity with modern Linux architecture. (See Figure 8)
Figure 8 – Avoids Wayland Sessions
Daemonization and Process Masquerading
After passing the environment check, the payload performs a double-fork daemonization sequence. It detaches from the controlling terminal, creates a new session, forks again, closes standard file descriptors, changes the working directory to root, and resets the file mode mask. (See Figure 9)
Figure 9 – Double Fork Daemonization
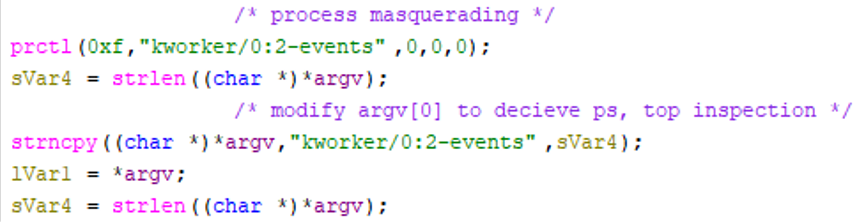
Immediately afterward, it calls prctl(PR_SET_NAME, …), altering its process name to resemble a kernel worker thread — specifically mimicking kworker/0:2-events. It also modifies argv[0] to reinforce this disguise. (See Figure 10)
Figure 10 – Process Masquerading
This technique is designed to reduce suspicion during casual inspection with tools such as ps or top, as kernel worker names are familiar to Linux administrators and are often ignored.
This technique is not intended to defeat forensic examination; rather, it aims at camouflage rather than perfect stealth.
Clipboard Monitoring Loop
Once daemonized, the implant connects to the X server using standard X11 APIs. If a display connection cannot be established, execution halts. If successful, the program enters a continuous polling loop that iterates every 200 milliseconds, retrieving the contents of the CLIPBOARD selection. (See Figure 11)
Figure 11 – Clipboard Monitoring Loop with 200ms Polling
Clipboard retrieval is implemented using the native X11 selection protocol rather than a shortcut API. The malware resolves the “CLIPBOARD” and “UTF8_STRING” atoms, creates a hidden 1×1 window, and calls XConvertSelection to request clipboard data in UTF-8 format. It then blocks on SelectionNotify events via XNextEvent until the clipboard owner responds.
Once delivered, the data is extracted with XGetWindowProperty, duplicated into process memory, and the temporary window is destroyed. This ensures clean, synchronous acquisition of human-readable clipboard text without visible UI artifacts. (See Figure 12)
Figure 12 – Clipboard Scrapper
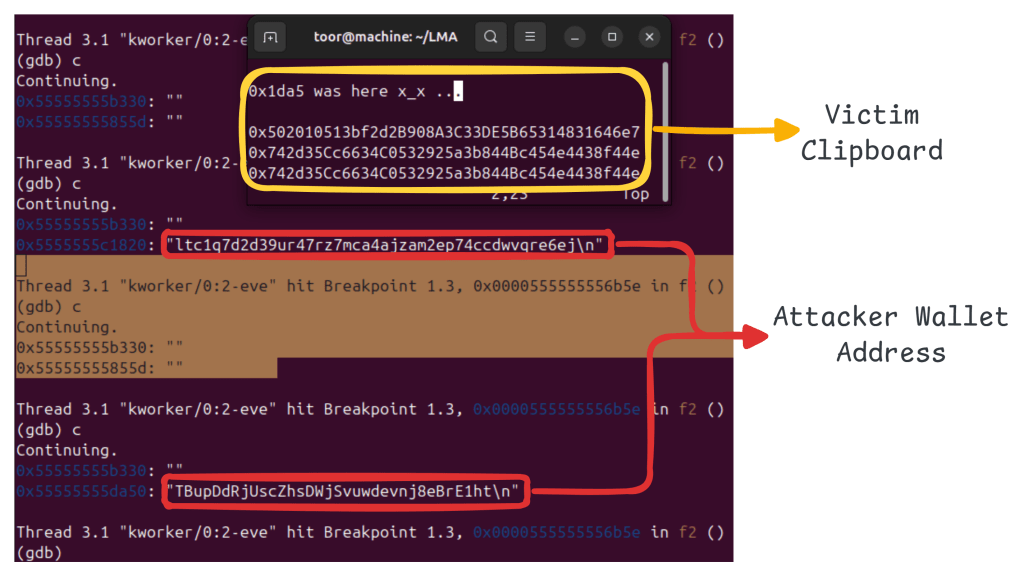
The retrieved text is evaluated against a set of regular expressions corresponding to cryptocurrency wallet formats. If a match is detected, the malware transitions from passive monitoring to active hijacking. It claims clipboard ownership using XSetSelectionOwner, again through a hidden window, and waits for SelectionRequest events.
When a paste operation occurs, the implant responds by supplying the attacker-controlled wallet address via XChangeProperty and XSendEvent, gracefully completing the X11 selection handshake. (See Figure 13)
Figure 13 – Clipboard Setter
The 200ms polling interval balances responsiveness and resource invisibility. Replacement occurs fast enough to precede typical paste actions while maintaining low CPU usage. The implant does not intercept keystrokes or monitor network traffic; it simply abuses X11’s trust model — reading clipboard contents, matching wallet patterns, and serving malicious replacements at paste time.
Configuration Protection Using ChaCha20
Wallet regex patterns and replacement addresses are not stored in plaintext. They are encrypted in binary using a ChaCha20 stream cipher with a static 256-bit key and a counter. This avoids revealing configuration buffers during static analysis.
At runtime, a static 256-bit key and counter are used to decrypt configuration buffers in memory. Only after decryption are the regular expressions compiled and replacement wallet addresses stored in memory. (See Figure 14)
Figure 14 – Configuration Decryption
This prevents trivial extraction using static string analysis but does not protect communications, as no command-and-control channel exists. The cryptographic implementation is functional rather than advanced. It is sufficient to defeat naive inspection but offers limited resistance to dynamic analysis.
Cryptocurrency Targeting
Dynamic instrumentation revealed that the payload matches multiple cryptocurrency wallet formats. Below is an example showing a Monero address match (See Figure 15)
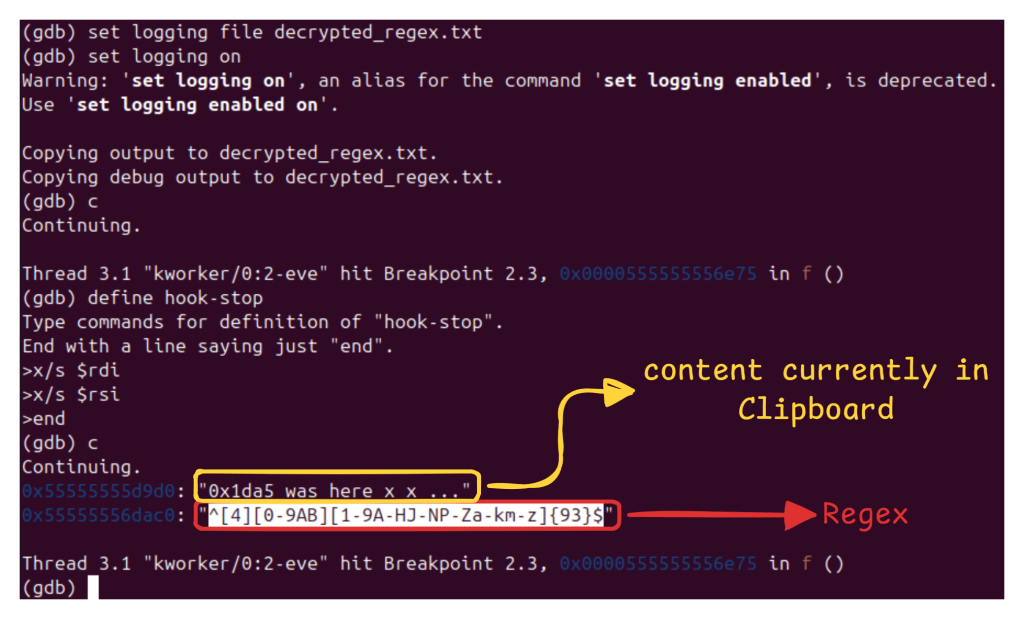
Figure 15 – Dumping Target Wallet Regex
Below are the regex being matched (extracted post-decryption) :
The implant operates entirely offline, with encrypted replacement addresses hardcoded and static. Upon detection, the clipboard is overwritten with attacker wallet addresses embedded in the binary (in encrypted form). (See Figure 16)
Additional regex patterns indicate monitoring of TON and Ripple wallet formats, although replacement addresses were not observed for those assets.
Absence of Command-and-Control Infrastructure
No network communication was observed during analysis. The binary does not initiate DNS queries, HTTP requests, or socket connections and carries no embedded domains or IP addresses.
This C2-less architecture fundamentally alters the traditional malware kill chain. There is no beaconing stage, no tasking loop, no data exfiltration channel, and no infrastructure to dismantle. Monetization occurs directly at the endpoint when a victim pastes a manipulated wallet address and executes a cryptocurrency transaction.
This model reduces the attacker’s operational risk. Since there are no servers to seize, no traffic to sinkhole, and no indicators derived from network telemetry, the detection strategy must rely on host-based behavioral analysis rather than network security controls.
The campaign illustrates a growing trend: financially motivated malware that eliminates the need for infrastructure. Combined with the reuse of publicly available tools such as bincrypter for payload staging, this approach lowers development costs, accelerates deployment, and complicates attribution.
ClipXDaemon is therefore notable not only for its technical design but for what it represents — the increasing weaponization of open-source tooling and the emergence of autonomous, infrastructure-less financial malware targeting Linux users.
Conclusion
The analysis of ClipXDaemon reflects a meaningful shift in Linux malware tradecraft — not in the sophistication of exploitation, but in operational design. The threat eliminates the need for command-and-control infrastructure entirely, collapsing the traditional kill chain into a localized, self-contained monetization loop.
There are no external beacons, tasking servers, or data exfiltration channels. Revenue generation depends solely on clipboard interception and user transaction behavior.
While ClipXDaemon reuses the same loader framework previously observed in ShadowHS reporting, there is no evidence of convergence in attribution. The shared component – bincrypter- is an openly available obfuscation framework.
Its reuse highlights a broader trend in the threat landscape; adversaries increasingly operationalize legitimate open-source tooling to accelerate development cycles and standardize staging mechanisms. This modular reuse model lowers barriers to entry while complicating campaign clustering and attribution analysis.
ClipXDaemon’s strength lies in precision targeting, environmental awareness, and architectural minimalism. As Linux adoption grows within cryptocurrency and developer communities, financially motivated userland implants such as this are likely to increase in frequency.
Cyble’s Threat Intelligence Platforms continuously monitor emerging threats, attacker infrastructure, and malware activity across the dark web, deep web, and open sources. This proactive intelligence empowers organizations with early detection, brand and domain protection, infrastructure mapping, and attribution insights. Altogether, these capabilities provide a critical head start in mitigating and responding to evolving cyber threats.
Our Recommendations
We have listed some essential cybersecurity best practices that serve as the first line of defense against attackers. We recommend that our readers follow the best practices given below:
From a detection standpoint, this architectural choice significantly reduces conventional visibility. Network-based detections, domain-reputation feeds, and infrastructure takedown strategies are ineffective against implants that never communicate externally. Instead, detection must pivot toward behavioral telemetry within the endpoint. Given the absence of network indicators, defensive strategies must prioritize endpoint visibility and behavioral controls.
Harden Linux Environments
Where operationally feasible, transition from X11 (permissive model) to Wayland-based sessions. Wayland’s security model restricts global clipboard scraping, thereby reducing this attack surface.
Restrict execution from user-writable directories such as ~/.local/bin/ where possible through application control policies.
Monitor Userland Persistence
Audit modifications to ~/.profile, ~/.bashrc, and other user-level autostart mechanisms.
Establish baselines for legitimate binaries within ~/.local/bin/ and alert on newly created executables.
Detect Process Masquerading
Identify processes with kernel-thread naming conventions (e.g., kworker/*) running under non-root user contexts.
Correlate prctl(PR_SET_NAME) modifications with suspicious execution ancestry.
Instrument X11 API Abuse
Monitor for abnormal or repetitive use of:
XConvertSelection
XSetSelectionOwner
XGetWindowProperty
High-frequency clipboard polling (e.g., ~200ms intervals) originating from background daemons should be investigated.
Implement Behavioral EDR Controls
Alert on execution of ELF binaries dropped from interpreted shell scripts via /proc/self/fd.
Detect double-fork daemonization sequences initiated from user shell contexts.
Flag base64-decoded ELF writes followed by immediate execution.
User Awareness Controls
Encourage manual verification of cryptocurrency addresses before transaction confirmation.
Where possible, utilize hardware wallet confirmation mechanisms that display recipient addresses independently of the host system.
Organizations operating Linux environments in cryptocurrency-sensitive roles should consider clipboard manipulation threats as part of their baseline threat model.
If you don’t go searching for AI services, they’ll find you all the same. Every major tech company feels a moral obligation not just to develop an AI assistant, integrated chatbot, or autonomous agent, but to bake it into their existing mainstream products and forcibly activate it for tens of millions of users. Here are just a few examples from the last six months:
Google activated Gemini for all U.S. Chrome users, cranked its browser functionality to the max, aggressively expanded the reach of AI Overviews in search results, and baked a whole suite of AI features into its online services (Gmail, Google Docs, and others).
Apple integrated its own Apple Intelligence (conveniently sharing the AI acronym) into the latest OS versions across all device types and most of its native apps.
On the flip side, geeks have rushed to build their own “personal Jarvises” by renting VPS instances or hoarding Mac minis to run the OpenClaw AI agent. Unfortunately, OpenClaw’s security issues with default settings turned out to be so massive that it’s already been dubbed the biggest cybersecurity threat of 2026.
Beyond the sheer annoyance of having something shoved down your throat, this AI epidemic brings some very real practical risks and headaches. AI assistants hoover up every bit of data they can get their hands on, parsing the context of the websites you visit, analyzing your saved documents, reading through your chats, and so on. This gives AI companies an unprecedentedly intimate look into every user’s life.
A leak of this data during a cyberattack — whether from the AI provider’s servers or from the cache on your own machine — could be catastrophic. These assistants can see and cache everything you can, including data usually tucked behind multiple layers of security: banking info, medical diagnoses, private messages, and other sensitive intel. We took a deep dive into how this plays out when we broke down the issues with the AI-powered Copilot+ Recall system, which Microsoft also planned to force-feed to everyone. On top of that, AI can be a total resource hog, eating up RAM, GPU cycles, and storage, which often leads to a noticeable hit to system performance.
For those who want to sit out the AI storm and avoid these half-baked, rushed-to-market neural network assistants, we’ve put together a quick guide on how to kill the AI in popular apps and services.
How to disable AI in Google Docs, Gmail, and Google Workspace
Google’s AI assistant features in Mail and Docs are lumped together under the umbrella of “smart features”. In addition to the large language model, this includes various minor conveniences, like automatically adding meetings to your calendar when you receive an invite in Gmail. Unfortunately, it’s an all-or-nothing deal: you have to disable all of the “smart features” to get rid of the AI.
To do this, open Gmail, click the Settings (gear) icon, and then select See all settings. On the General tab, scroll down to Google Workspace smart features. Click Manage Workspace smart feature settings and toggle off two options: Smart features in Google Workspace and Smart features in other Google products. We also recommend unchecking the box next to Turn on smart features in Gmail, Chat, and Meet on the same general settings tab. You’ll need to restart your Google apps afterward (which usually happens automatically).
How to disable AI Overviews in Google Search
You can kill off AI Overviews in search results on both desktops and smartphones (including iPhones), and the fix is the same across the board. The simplest way to bypass the AI overview on a case-by-case basis is to append -ai to your search query — for example, how to make pizza -ai. Unfortunately, this method occasionally glitches, causing Google to abruptly claim it found absolutely nothing for your request.
If that happens, you can achieve the same result by switching the search results page to Web mode. To do this, select the Web filter immediately below the search bar — you’ll often find it tucked away under the More button.
A more radical solution is to jump ship to a different search engine entirely. For instance, DuckDuckGo not only tracks users less and shows little ads, but it also offers a dedicated AI-free search — just bookmark the search page at noai.duckduckgo.com.
How to disable AI features in Chrome
Chrome currently has two types of AI features baked in. The first communicates with Google’s servers and handles things like the smart assistant, an autonomous browsing AI agent, and smart search. The second handles locally more utility-based tasks, such as identifying phishing pages or grouping browser tabs. The first group of settings is labeled AI mode, while the second contains the term Gemini Nano.
To disable them, type chrome://flags into the address bar and hit Enter. You’ll see a list of system flags and a search bar; type “AI” into that search bar. This will filter the massive list down to about a dozen AI features (and a few other settings where those letters just happen to appear in a longer word). The second search term you’ll need in this window is “Gemini“.
After reviewing the options, you can disable the unwanted AI features — or just turn them all off — but the bare minimum should include:
AI Mode Omnibox entrypoint
AI Entrypoint Disabled on User Input
Omnibox Allow AI Mode Matches
Prompt API for Gemini Nano
Prompt API for Gemini Nano with Multimodal Input
Set all of these to Disabled.
How to disable AI features in Firefox
While Firefox doesn’t have its own built-in chatbots and hasn’t (yet) tried to force upon users agent-based features, the browser does come equipped with smart-tab grouping, a sidebar for chatbots, and a few other perks. Generally, AI in Firefox is much less “in your face” than in Chrome or Edge. But if you still want to pull the plug, you’ve two ways to do it.
The first method is available in recent Firefox releases — starting with version 148, a dedicated AI Controls section appeared in the browser settings, though the controls are currently a bit sparse. You can use a single toggle to completely Block AI enhancements, shutting down AI features entirely. You can also specify whether you want to use On-device AI by downloading small local models (currently just for translations) and configure AI chatbot providers in sidebar, choosing between Anthropic Claude, ChatGPT, Copilot, Google Gemini, and Le Chat Mistral.
The second path — for older versions of Firefox — requires a trip into the hidden system settings. Type about:config into the address bar, hit Enter, and click the button to confirm that you accept the risk of poking around under the hood.
A massive list of settings will appear along with a search bar. Type “ML” to filter for settings related to machine learning.
To disable AI in Firefox, toggle the browser.ml.enabled setting to false. This should disable all AI features across the board, but community forums suggest this isn’t always enough to do the trick. For a scorched-earth approach, set the following parameters to false (or selectively keep only what you need):
ml.chat.enabled
ml.linkPreview.enabled
ml.pageAssist.enabled
ml.smartAssist.enabled
ml.enabled
ai.control.translations
tabs.groups.smart.enabled
urlbar.quicksuggest.mlEnabled
This will kill off chatbot integrations, AI-generated link descriptions, assistants and extensions, local translation of websites, tab grouping, and other AI-driven features.
How to disable AI features in Microsoft apps
Microsoft has managed to bake AI into almost every single one of its products, and turning it off is often no easy task — especially since the AI sometimes has a habit of resurrecting itself without your involvement.
How to disable AI features in Edge
Microsoft’s browser is packed with AI features, ranging from Copilot to automated search. To shut them down, follow the same logic as with Chrome: type edge://flags into the Edge address bar, hit Enter, then type “AI” or “Copilot” into the search box. From there, you can toggle off the unwanted AI features, such as:
Enable Compose (AI-writing) on the web
Edge Copilot Mode
Edge History AI
Another way to ditch Copilot is to enter edge://settings/appearance/copilotAndSidebar into the address bar. Here, you can customize the look of the Copilot sidebar and tweak personalization options for results and notifications. Don’t forget to peek into the Copilot section under App-specific settings — you’ll find some additional controls tucked away there.
How to disable Microsoft Copilot
Microsoft Copilot comes in two flavors: as a component of Windows (Microsoft Copilot), and as part of the Office suite (Microsoft 365 Copilot). Their functions are similar, but you’ll have to disable one or both depending on exactly what the Redmond engineers decided to shove onto your machine.
The simplest thing you can do is just uninstall the app entirely. Right-click the Copilot entry in the Start menu and select Uninstall. If that option isn’t there, head over to your installed apps list (Start → Settings → Apps) and uninstall Copilot from there.
In certain builds of Windows 11, Copilot is baked directly into the OS, so a simple uninstall might not work. In that case, you can toggle it off via the settings: Start → Settings → Personalization → Taskbar→ turn off Copilot.
If you ever have a change of heart, you can always reinstall Copilot from the Microsoft Store.
It’s worth noting that many users have complained about Copilot automatically reinstalling itself, so you might want to do a weekly check for a couple of months to make sure it hasn’t staged a comeback. For those who are comfortable tinkering with the System Registry (and understand the consequences), you can follow this detailed guide to prevent Copilot’s silent resurrection by disabling the SilentInstalledAppsEnabled flag and adding/enabling the TurnOffWindowsCopilot parameter.
How to disable Microsoft Recall
The Microsoft Recall feature, first introduced in 2024, works by constantly taking screenshots of your computer screen and having a neural network analyze them. All that extracted information is dumped into a database, which you can then search using an AI assistant. We’ve previously written in detail about the massive security risks Microsoft Recall poses.
Under pressure from cybersecurity experts, Microsoft was forced to push the launch of this feature from 2024 to 2025, significantly beefing up the protection of the stored data. However, the core of Recall remains the same: your computer still remembers your every move by constantly snapping screenshots and OCR-ing the content. And while the feature is no longer enabled by default, it’s absolutely worth checking to make sure it hasn’t been activated on your machine.
To check, head to the settings: Start → Settings → Privacy & Security →Recall & snapshots. Ensure the Save snapshots toggle is turned off, and click Delete snapshots to wipe any previously collected data, just in case.
How to disable AI in Notepad and Windows context actions
AI has seeped into every corner of Windows, even into File Explorer and Notepad. You might even trigger AI features just by accidentally highlighting text in an app — a feature Microsoft calls “AI Actions”. To shut this down, head to Start → Settings → Privacy & Security → Click to do.
Notepad has received its own special Copilot treatment, so you’ll need to disable AI there separately. Open the Notepad settings, find the AI features section, and toggle Copilot off.
Finally, Microsoft has even managed to bake Copilot into Paint. Unfortunately, as of right now, there is no official way to disable the AI features within the Paint app itself.
How to disable AI in WhatsApp
In several regions, WhatsApp users have started seeing typical AI additions like suggested replies, AI message summaries, and a brand-new Chat with Meta AI button. While Meta claims the first two features process data locally on your device and don’t ship your chats off to their servers, verifying that is no small feat. Luckily, turning them off is straightforward.
To disable Suggested Replies, go to Settings → Chats → Suggestions & smart replies and toggle off Suggested replies. You can also kill off AI Sticker suggestions in that same menu. As for the AI message summaries, those are managed in a different location: Settings → Notifications → AI message summaries.
How to disable AI on Android
Given the sheer variety of manufacturers and Android flavors, there’s no one-size-fits-all instruction manual for every single phone. Today, we’ll focus on killing off Google’s AI services — but if you’re using a device from Samsung, Xiaomi, or others, don’t forget to check your specific manufacturer’s AI settings. Just a heads-up: fully scrubbing every trace of AI might be a tall order — if it’s even possible at all.
In Google Messages, the AI features are tucked away in the settings: tap your account picture, select Messages settings, then Gemini in Messages, and toggle the assistant off.
Broadly speaking, the Gemini chatbot is a standalone app that you can uninstall by heading to your phone’s settings and selecting Apps. However, given Google’s master plan to replace the long-standing Google Assistant with Gemini, uninstalling it might become difficult — or even impossible — down the road.
If you can’t completely uninstall Gemini, head into the app to kill its features manually. Tap your profile icon, select Gemini Apps activity, and then choose Turn off or Turn off and delete activity. Next, tap the profile icon again and go to the Connected Apps setting (it may be hiding under the Personal Intelligence setting). From here, you should disable all the apps where you don’t want Gemini poking its nose in.
Apple’s platform-level AI features, collectively known as Apple Intelligence, are refreshingly straightforward to disable. In your settings — on desktops, smartphones, and tablets alike — simply look for the section labeled Apple Intelligence & Siri. By the way, depending on your region and the language you’ve selected for your OS and Siri, Apple Intelligence might not even be available to you yet.
Other posts to help you tune the AI tools on your devices:
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2026-03-05 13:06:482026-03-05 13:06:48How to disable unwanted AI assistants and features on your PC and smartphone | Kaspersky official blog
Cisco Talos is disclosing UAT-9244, who we assess with high confidence is a China-nexus advanced persistent threat (APT) actor closely associated with Famous Sparrow.
Since 2024, UAT-9244 has targeted critical telecommunications infrastructure, including Windows and Linux-based endpoints and edge devices in South America, proliferating access via three malware implants.
The first backdoor, “TernDoor,” is a new variation of the previously disclosed, Windows-based, CrowDoor malware.
Talos also discovered that UAT-9244 uses “PeerTime,” an ELF-based backdoor that uses the BitTorrent protocol to conduct malicious operations on an infected system.
UAT-9244’s third implant is a brute force scanner, which Talos tracks as “BruteEntry.” BruteEntry is typically installed on network edge devices, essentially converting them into mass-scanning proxy nodes, also known as Operational Relay Boxes (ORBs) that attempt to brute force into SSH, Postgres, and Tomcat servers.
Introducing TernDoor: A variant of CrowDoor
UAT-9244 used dynamic-link library (DLL) side-loading to activate multiple stages of their infection chain. The actor executed “wsprint[.]exe”, a benign executable that loaded the malicious DLL-based loader “BugSplatRc64[.]dll”. The DLL reads a data file named “WSPrint[.]dll” from disk, decrypts its contents, and executes them in memory to activate TernDoor, the final payload.
TernDoor is a variant of CrowDoor, a backdoor deployed in recent intrusions linked to China-nexus APTs such as FamousSparrow and Earth Estries. CrowDoor is a variant of SparrowDoor, another backdoor attributed to FamousSparrow. CrowDoor has also been observed in previous Tropic Trooper intrusions, indicating a close operational relationship with FamousSparrow. Based on the overlap in tooling; tactics, techniques, and procedures (TTPs); and victimology, we assess with high confidence that UAT-9244 closely overlaps with FamousSparrow and Tropic Trooper.
Although UAT-9244 and Salt Typhoon both target telecommunications service providers, Talos has not been able to verify or establish a solid connection between the two clusters.
The DLL-based loader
The DLL-based loader, “BugSplatRc64.dll”, will load the “WSPrint.dll” file from the current directory, which will be decoded using the key “qwiozpVngruhg123”.
Figure 1. DLL-based loader reading the encoded payload.
The decoded shellcode is position-independent and decodes and decompresses the final payload. The final payload is the TernDoor implant.
TernDoor
The final shellcode consists of the TernDoor backdoor. TernDoor is a variant of CrowDoor, actively developed and used by UAT-9244 since at least November 2024. TernDoor deviates from CrowDoor in the following aspects:
TernDoor consists of command codes that are different from previously disclosed variants of CrowDoor.
The TernDoor shellcode also consists of an embedded Windows driver (SYS file). The driver is encrypted using AES in the shellcode. The driver is used to suspend, resume, and terminate processes.
Persistence
The TernDoor infection chain is persisted on the system using either a scheduled task or the Registry Run key.
The scheduled task is named “WSPrint” and created using the command:
Unlike CrowDoor, TernDoor only supports one command line switch: “-u”, passed to WSPrint.exe. This is the switch for uninstalling the malware from the system and it deletes all malware files from the operating directory, as well as terminates malicious processes.
Decoding the configuration
Like previous variants of CrowDoor, TernDoor also checks to ensure it has been injected into “msiexec[.]exe”. The implant decodes its configuration that can specify the following information:
Command and control (C2) IP address
Number of tries to connect to the C2
C2 port number
User-Agent to use while connecting to C2 (if applicable)
Figure 2. TernDoor configuration blob.
TernDoor functionality
TernDoor’s capabilities resemble those of previously disclosed CrowDoor samples:
Communicates with the C2 IP address
Creates processes and runs arbitrary commands via remote shell and independently
Reads and writes files
Collects system information such as computer and user name, IP address information, and OS bitness
Uninstalls itself from the infected system
Deploys the accompanying driver to hide malicious components and perform process management
The accompanying Windows driver, WSPrint.sys, is dropped to disk and then activated using a windows service:
Figure 3. Malicious driver service on the infected endpoint.
The driver creates a device named “\Device\VMTool” and symbolically links it to “\DosDevices\VMTool”. It can terminate, suspend, or resume processes specified by TernDoor — likely a means of evasion.
TernDoor infrastructure
All the C2 IP addresses discovered by Talos were associated with the following SSL certificate on port 443:
Pivoting off this certificate, Talos found an additional 18 IPs likely being used by UAT-9244. This list is provided in the indicators of compromise (IOCs) section.
One of the DLL-based loaders was also hosted on the IP “212.11.64[.]105”. On this server, we discovered a set of shell scripts and an accompanying malware family we track as “PeerTime.”
PeerTime: UAT-9244’s peer-to-peer (P2P) backdoor
PeerTime is an ELF based backdoor that is compiled for a variety of architectures such as ARM, AARCH, PPC, MIPS etc., indicating that UAT-9244 can use it to infect a variety of embedded systems.
PeerTime is deployed through a shellscript that downloads the PeerTime loader ELF binary and an instrumentor binary.
The instrumentor ELF binary will check for the presence of docker on the compromised host using the commands docker and docker –q.
If docker is found, then the PeerTime loader is executed using:
docker <path_of_PeerTime_loader_ELF>
The instrumentor consists of debug strings in Simplified Chinese, indicating that it is a custom binary created and deployed by Chinese-speaking threat actors:
获取当前程序路径错误: //Error retrieving current program path:
删除当前程序错误: // Error deleting current program:
Figure 4. PeerTime installation/infection chain.
PeerTime consists of a loader that will decrypt and decompress the final PeerTime ELF payload and run it in memory. The PeerTime loader has the ability to rename its process to a benign process to evade detection.
PeerTime uses the BitTorrent protocol to obtain C2 information, download files from its peers, and execute them on the infected host. The payloads are written to disk and copied to the specified locations using BusyBox. As of now, PeerTime consists of two versions: one written in C/C++ and a newer version written in Rust.
Infrastructure used by UAT-9244 also hosts another set of shell scripts and payloads designed to establish compromised Linux based systems including edge devices as operational relay boxes (ORBs) that scan and brute force Tomcat, Postgres, and SSH servers.
The shell script will download two components:
An instrumentor and daemon process that activates the actual brute forcer
The actual brute forcer (named BruteEntry) that obtains target IPs from the C2 server and scans the IPs
Figure 6. BruteEntry infection chain.
The instrumentor binary
The instrumentor binary is an ELF file written in GoLang. It checks if the BruteEntry is already running on the system using “pgrep”:
pgrep <path_to_BruteEntry>
And then starts the brute forcer agent:
./<path_to_BruteEntry>
BruteEntry
BruteEntry is also written in GoLang and begins by registering with the C2 server by providing it with the infected system’s IP address and computer name:
{“ip”:“value”, “hostname”:“value”}
The C2 responds with a JSON that assigns an agent_id to the infected host:
{“agent_id”:“value”, “server”:“value”}
where “server” = version string of BruteEntry such as “brute-force-server-v1.0”
BruteEntry will then ask the C2 for tasks to perform by sending a GET request to the C2 at the URI, where limit=1000 is the maximum number of vulnerable IPs to scan:
/tasks/<agent_id>?limit=1000
The C2 responds with a JSON that consists of “tasks” containing the list of IPs to brute force:
The “type” field in the json defines the type of scan to conduct — either “tomcat”,“postgres”, or “ssh”.
The agent will then use a set of embedded credentials to attempt to brute force into either a Tomcat server application at the URL “https[://]<IP>:<Port>/manager/html”, or will brute force into a Postgres instance, either defined in the JSON (<IP><Port>) from the C2 or using the port 5432 if no port is specified.
Figure 7. BruteEntry selecting the type of service to brute force into.
Any successful logins are then POSTED back to the C2:
{"batch":[
{"task_id":<task_id>,"success":<true/false>,"note":" <notes on the task>"},
{"task_id":<task_id>,"success":<true/false>,"note":" <notes on the task>"},
......
]}
In this instance, “success” indicates if the brute force was successful (true or false), and “notes” provides specific information on whether the brute force was successful. If the login failed, the note reads “All credentials tried.” If it succeeded, the note reads “Cracked by agent <agent_id> | Version <agent_version>”.
Coverage
The following ClamAV signatures detect and block this threat:
Win.Loader.PeerTime
Win.Malware.TernDoor
Unix.Malware.BruteEntry
Txt.Malware.PeerTime
Unix.Malware.PeerTime
The following SNORT® rules (SIDs) detect and block this threat: 65551
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2026-03-05 12:06:412026-03-05 12:06:41UAT-9244 targets South American telecommunication providers with three new malware implants
The education sector is notoriously short on cash, but rich in assets for threat actors to target. How can managed detection and response (MDR) help learning institutions regain the initiative?
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2026-03-05 05:06:262026-03-05 05:06:26Protecting education: How MDR can tip the balance in favor of schools
In 2022, we dived deep into an attack method called browser-in-the-browser — originally developed by the cybersecurity researcher known as mr.d0x. Back then, no actual examples existed of this model being used in the wild. Fast-forward four years, and browser-in-the-browser attacks have graduated from the theoretical to the real: attackers are now using them in the field. In this post, we revisit what exactly a browser-in-the-browser attack is, show how hackers are deploying it, and, most importantly, explain how to keep yourself from becoming its next victim.
What is a browser-in-the-browser (BitB) attack?
For starters, let’s refresh our memories on what mr.d0x actually cooked up. The core of the attack stems from his observation of just how advanced modern web development tools — HTML, CSS, JavaScript, and the like — have become. It’s this realization that inspired the researcher to come up with a particularly elaborate phishing model.
A browser-in-the-browser attack is a sophisticated form of phishing that uses web design to craft fraudulent websites imitating login windows for well-known services like Microsoft, Google, Facebook, or Apple that look just like the real thing. The researcher’s concept involves an attacker building a legitimate-looking site to lure in victims. Once there, users can’t leave comments or make purchases unless they “sign in” first.
Signing in seems easy enough: just click the Sign in with {popular service name} button. And this is where things get interesting: instead of a genuine authentication page provided by the legitimate service, the user gets a fake form rendered inside the malicious site, looking exactly like… a browser pop-up. Furthermore, the address bar in the pop-up, also rendered by the attackers, displays a perfectly legitimate URL. Even a close inspection won’t reveal the trick.
From there, the unsuspecting user enters their credentials for Microsoft, Google, Facebook, or Apple into this rendered window, and those details go straight to the cybercriminals. For a while this scheme remained a theoretical experiment by the security researcher. Now — real-world attackers have added it to their arsenals.
Facebook credential theft
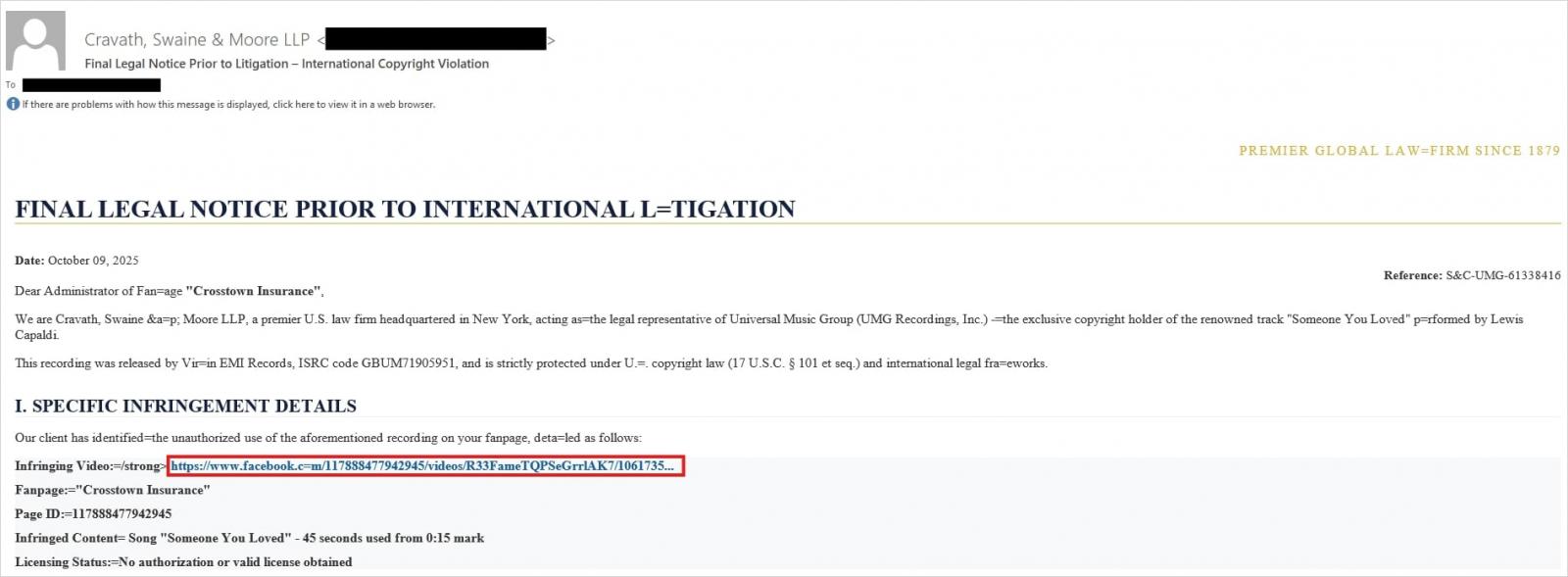
Attackers have put their own spin on mr.d0x’s original concept: recent browser-in-the-browser hits have been kicking off with emails designed to alarm recipients. For instance, one phishing campaign posed as a law firm informing the user they’d committed a copyright violation by posting something on Facebook. The message included a credible-looking link allegedly to the offending post.
Attackers sent messages on behalf of a fake law firm alleging copyright infringement — complete with a link supposedly to the problematic Facebook post. Source
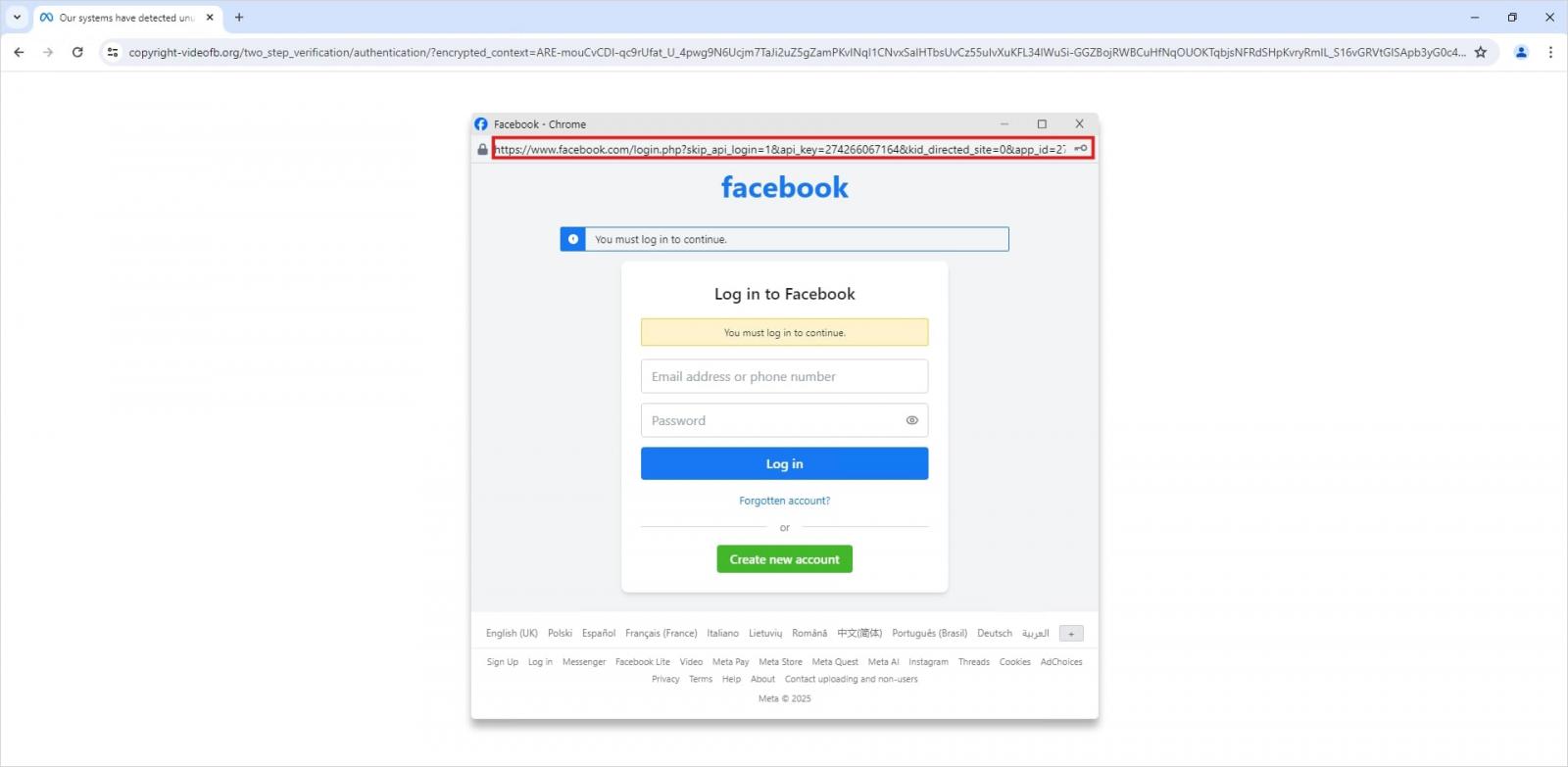
Interestingly, to lower the victim’s guard, clicking the link didn’t immediately open a fake Facebook login page. Instead, they were first greeted by a bogus Meta CAPTCHA. Only after passing it was the victim presented with the fake authentication pop-up.
This isn’t a real browser pop-up; it’s a website element mimicking a Facebook login page — a ruse that allows attackers to display a perfectly convincing address. Source
Naturally, the fake Facebook login page followed mr.d0x’s blueprint: it was built entirely with web design tools to harvest the victim’s credentials. Meanwhile, the URL displayed in the forged address bar pointed to the real Facebook site — www.facebook.com.
How to avoid becoming a victim
The fact that scammers are now deploying browser-in-the-browser attacks just goes to show that their bag of tricks is constantly evolving. But don’t despair — there’s a way to tell if a login window is legit. A password manager is your friend here, which, among other things, acts as a reliable security litmus test for any website.
That’s because when it comes to auto-filling credentials, a password manager looks at the actual URL, not what the address bar appears to show, or what the page itself looks like. Unlike a human user, a password manager can’t be fooled with browser-in-the-browser tactics, or any other tricks, like domains having a slightly different address (typosquatting) or phishing forms buried in ads and pop-ups. There’s a simple rule: if your password manager offers to auto-fill your login and password, you’re on a website you’ve previously saved credentials for. If it stays silent, something’s fishy.
Beyond that, following our time-tested advice will help you defend against various phishing methods, or at least minimize the fallout if an attack succeeds:
Enable two-factor authentication (2FA) for every account that supports it. Ideally, use one-time codes generated by a dedicated authenticator app as your second factor. This helps you dodge phishing schemes designed to intercept confirmation codes sent via SMS, messaging apps, or email. You can read more about one-time-code 2FA in our dedicated post.
Use passkeys. The option to sign in with this method can also serve as a signal that you’re on a legitimate site. You can learn all about what passkeys are and how to start using them in our deep dive into the technology.
Set unique, complex passwords for all your accounts. Whatever you do, never reuse the same password across different accounts. We recently covered what makes a password truly strong on our blog. To generate unique combinations — without needing to remember them — Kaspersky Password Manager is your best bet. As an added bonus, it can also generate one-time codes for two-factor authentication, store your passkeys, and synchronize your passwords and files across your various devices.
Finally, this post serves as yet another reminder that theoretical attacks described by cybersecurity researchers often find their way out into the wild. So, keep an eye on our blog, and subscribe to our Telegram channel to stay up to speed on the latest threats to your digital security and how to shut them down.
Read about other inventive phishing techniques scammers are using day in day out:
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2026-03-04 16:06:362026-03-04 16:06:36What a browser-in-the-browser attack is, and how to spot a fake login window | Kaspersky official blog
Modern software development relies on containers and the use of third-party software modules. On the one hand, this greatly facilitates the creation of new software, but on the other, it gives attackers additional opportunities to compromise the development environment. News about attacks on the supply chain through the distribution of malware via various repositories appears with alarming regularity. Therefore, tools that allow the scanning of images have long been an essential part of secure software development.
Our portfolio has long included a solution for protecting container environments. It allows the scanning of images at different stages of development for malware, known vulnerabilities, configuration errors, the presence of confidential data in the code, and so on. However, in order to make an informed decision about the state of security of a particular image, the operator of the cybersecurity solution may need some more context. Of course, it’s possible to gather this context independently, but if a thorough investigation is conducted manually each time, development may be delayed for an unpredictable period of time. Therefore, our experts decided to add the ability to look at the image from a fresh perspective; of course, not with a human eye — AI is indispensable nowadays.
OpenAI API
Our Kaspersky Container Security solution (a key component of Kaspersky Cloud Workload Security) now supports an application programming interface for connecting external large language models. So, if a company has deployed a local LLM (or has a subscription to connect a third-party model) that supports the OpenAI API, it’s possible to connect the LLM to our solution. This gives a cybersecurity expert the opportunity to get both additional context about uploaded images and an independent risk assessment by means of a full-fledged AI assistant capable of quickly gathering the necessary information.
The AI provides a description that clearly explains what the image is for, what application it contains, what it does specifically, and so on. Additionally, the assistant conducts its own independent analysis of the risks of using this image and highlights measures to minimize these risks (if any are found). We’re confident that this will speed up decision-making and incident investigations and, overall, increase the security of the development process.
What else is new in Cloud Workload Security?
In addition to adding API to connect the AI assistant, our developers have made a number of other changes to the products included in the Kaspersky Cloud Workload Security offering. First, they now support single sign-on (SSO) and a multi-domain Active Directory, which makes it easier to deploy solutions in cloud and hybrid environments. In addition, Kaspersky Cloud Workload Security now scans images more efficiently and supports advanced security policy capabilities. You can learn more about the product on its official page.
The geopolitical landscape of the Middle East has entered one of its most volatile phases in decades. On February 28, 2026, tensions that had been simmering for years erupted into a full‑blown conflict involving the Islamic Republic of Iran, the United States, and Israel. A confluence of diplomatic stalemate, military posturing, and covert cyber preparations set the stage for what would evolve from a localized confrontation into an expansive, multi‑domain campaign.
The conflict’s opening salvo — codenamed Operation Epic Fury by the US and Operation Roaring Lion by Israel — was not just a conventional military assault. It was a synchronized hybrid offensive in which cyber operations were integrated as a co‑equal domain with kinetic strikes, psychological messaging, and information warfare. Over the course of the first 72 hours, from February 28 to March 3, kinetic blows and digital disruptions merged in ways that revealed both the strengths and vulnerabilities of actors across the region.
Throughout this critical period, Cyble Research and Intelligence Labs (CRIL) has been meticulously tracking the movements, attacks, claims, and associated cyber activity between Iran, Israel, and the US, providing real‑time insights into both the kinetic strikes and the evolving threat landscape.
Prelude to Conflict: Buildup and Diplomatic Gridlock
In the days leading up to February 28, the Middle East witnessed a massive US military buildup, the largest since the 2003 Iraq invasion. Aircraft carriers, fighter wings, and intelligence assets positioned themselves within striking range of Iran’s borders. At the same time, indirect nuclear negotiations in Geneva appeared, momentarily, to offer a diplomatic pathway, with Iran publicly agreeing to halt enrichment stockpiling under International Atomic Energy Agency (IAEA) supervision. However, distrust and strategic imperatives among the US, Israel, and Tehran rendered the diplomatic exercise insufficient to prevent escalation.
Day 1: February 28 — Operation Epic Fury
At approximately 06:27 GMT, the first concerted wave of strikes hit Iran. US‑Israeli forces began a broad assault across more than two dozen provinces, targeting nuclear facilities, IRGC command centers, ballistic missile launchers, and secure compounds tied to the Iranian leadership. The offensive reportedly included the targeted killing of Supreme Leader Ayatollah Ali Khamenei, a moment that marked a profound turning point in the conflict.
What set the opening apart from traditional air campaigns was its immediate cyber component. For the first time on such a scale, network disruption was planned to coincide with a kinetic impact. Independent monitors observed Iranian internet connectivity collapse to roughly 1–4% of normal levels as cyberattacks crippled state media, government digital services, and military communications.
Popular local services, including widely used mobile applications and prayer tools, were reportedly compromised to sow confusion and prompt defections, while defaced state news sites delivered messages contradicting official Iranian narratives.
Before the current situation, MuddyWater, long associated with Iran‑linked cyber campaigns, remained a critical piece of the pre‑existing threat landscape. Alongside other advanced persistent threat (APT) groups — such as APT42 (Charming Kitten), Prince of Persia / Infy, UNC6446, and CRESCENTHARVEST — these campaigns had already been active before February 28, conducting phishing, exploitation of public servers, and information theft targeting Israeli, US, and regional networks.
While Iran’s domestic internet infrastructure faltered, the US‑Israeli offensive extended psychological operations into Israeli territory. Threatening messages referencing national ID numbers and fuel shortages arrived in civilians’ inboxes, and misinformation campaigns amplified anxieties even as authorities worked to blunt digital interference.
Day 2: March 1 — Retaliation and the Surge of Hacktivism
Iran’s kinetic retaliation was swift and forceful. From March 1 onward, waves of ballistic missiles and drones launched at Israel, Gulf Cooperation Council (GCC) states, and US military bases reinforced that Tehran’s response would not be limited to symbolic posturing. The UAE alone intercepted hundreds of projectiles, resulting in civilian casualties and infrastructure damage, including at Dubai’s international airport and an AWS cloud data center within its mec1‑az2 availability zone.
On the cyber front, March 1 started the dramatic expansion of hacktivist activity across the region. More than 70 groups — spanning ideological spectrums and even blending pro‑Iranian and pro‑Russian motivations — activated operations in parallel with state responses. An Electronic Operations Room organized by Iraqi‑aligned hackers, such as Cyber Islamic Resistance / Team 313 began orchestrating distributed denial‑of‑service (DDoS) attacks, website defacements, and theft of credentials across national government portals and key infrastructure systems in Turkey, Poland, and GCC states.
One of the most technically significant artifacts of March 1 was a malicious RedAlert APK observed by Unit 42 analysts. Designed to mimic Israel’s official missile alert app, this payload was distributed via Hebrew‑language SMS links. Once installed, it collected sensitive device and user information — contacts, SMS logs, IMEI numbers, and email credentials — with encrypted exfiltration mechanisms and anti‑analysis protections, providing a rare glimpse of tradecraft resembling state‑level cyber operations at a time when Iranian domestic internet access was severely limited.
Beyond MuddyWater and other established APTs, opportunistic cybercriminals exploited the chaos through social engineering campaigns in the UAE.
Day 3: March 2–3 — Strikes, Blackouts, and Enduring Hybrid Threats
The kinetic campaign broadened on March 2 with the destruction of the IRGC’s Malek‑Ashtar headquarters in Tehran. By March 3, Israeli forces had struck Iran’s state broadcaster, further constraining Tehran’s ability to manage domestic information and cyber operations. The extended internet blackout — persisting well into the third day — continued to isolate Iranian networks, allowing external campaigns to operate with limited interference.
Several digital fronts emerged during this period:
Hacktivist and Propaganda Operations: Groups such as Handala Hack Team claimed exfiltration of terabytes of financial data; others like DieNet and OverFlame targeted GCC critical infrastructure portals and governmental systems in coordinated disruptive campaigns.
Pro‑Russian Opportunistic Convergence: Entities, including NoName057(16) and Russian Legion, shifted their focus from Ukraine‑related operations to anti‑Israel actions supportive of Iran, albeit with mixed credibility.
Cybercrime Opportunism: The blend of hacktivism and ransomware was exemplified by groups like INC Ransomware, which targeted industrial entities and combined extortion‑style tactics with ideological messaging.
Throughout March 1–3, analysts noted that most observed cyber activity fell into the realm of DDoS attacks, exposed CCTV feeds, and information operations rather than destructive intrusions into industrial control systems — although unverified claims of SCADA manipulation circulated widely in pro‑Iranian forums.
Broader Regional and Strategic Implications
The first 72 hours of Operation Epic Fury reveal several critical insights about modern conflict dynamics in the Middle East:
Cyber as a Co‑Equal Domain: Cyber operations were planned and executed in lockstep with kinetic strikes, demonstrating that modern warfare no longer segregates digital and physical arenas.
Hacktivist Amplification: With over 70 groups active within days, the hacktivist ecosystem has become a force multiplier of psychological and disruptive operations that can transcend national borders.
Opportunistic Exploitation: As seen in social engineering and ransomware campaigns, broader conflict can catalyze financially motivated cybercrime that piggybacks on geopolitical uncertainty.
These dynamics suggest that defenders in the region — from government CERTs to multinational enterprises — must maintain heightened vigilance across both technical and psychological threat vectors, with particular emphasis on credential harvesting, DDoS mitigation, and proactive monitoring of emerging malware campaigns.
Conclusion
The events from February 28 to March 3 highlight that the US‑Israeli offensive against Iran — launched as Operation Epic Fury — is not merely a military confrontation but a hybrid engagement across kinetic, cyber, and informational domains. While Iran’s internet infrastructure remains degraded, sophisticated pre‑positioned capabilities could still be activated in the coming weeks, particularly if connectivity is restored. Meanwhile, the hacktivist theatre continues to grow in both volume and geographic scope, even as the technical sophistication of most operations remains limited.
In this environment, security practitioners and strategic planners must be prepared for adaptive threat behavior that blends political motivations with opportunistic cybercrime — a reality that defines the 21st‑century battlespace in the Middle East and beyond.
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2026-03-03 16:06:482026-03-03 16:06:48Middle East on the Brink: Iran-US-Israel Hostilities Trigger Cyber-Kinetic Conflict