

AI Safety: Key Threats and Solutions
Artificial Intelligence (AI) becomes increasingly integrated into daily life, offering unprecedented advancements in automation, communication, and cybersecurity. However, as AI models grow more sophisticated, they also introduce new threats. Discussions about AGI (Artificial General Intelligence) and superintelligence often dominate public discourse, but immediate risks demand urgent attention.
This article explores three major AI threats: AI-powered phishing and malware generation, the misuse of AI for opinion shaping and unethical purposes, and unintended AI failures leading to harmful consequences. Understanding these risks and their countermeasures is crucial for AI safety and security.
1. AI-Powered Phishing and Malware Generation
Phishing has long been a major concern, but AI-driven automation has made it more effective than ever. Modern AI models generate hyper-personalized phishing emails, deepfake videos, and voice clones, making fraudulent messages more convincing and harder to detect.
Phishing Evolution with LLMs
A study of Cornell University analyzed AI-generated phishing emails and revealed how models like GPT-4 can evade traditional detection mechanisms. Despite machine learning-based detection tools, attackers continuously refine tactics to bypass defenses.
Some phishing campaigns now combine Open-Source Intelligence (OSINT) with LLMs to craft messages that exploit personal details. More advanced methods involve face spoofing, video generation, and voice cloning, creating a multi-modal attack strategy that achieves alarming success rates.
Jailbreaking and Malware Generation
Beyond phishing, AI models can be manipulated to generate malware, write harmful scripts, or aid cybercriminal activities. Jailbreaking techniques exploit vulnerabilities in model alignment to bypass ethical safeguards.
- J2 (Jailbreaking to Jailbreak): Researchers at Scale AI demonstrated how LLMs can be used to red-team other models, achieving over 90% success in bypassing GPT-4o’s defenses by embedding attacks within narratives or code snippets.
- Best-of-N (BoN) Jailbreaking: This method iterates through slight variations of a malicious prompt until the AI model complies. Research from Raight AI showed an 89% success rate against GPT-4.
- Backdoor Attacks in Open-Source Models: Threat actors can fine-tune open-source models to create malicious versions that inject backdoors into code. A recent example involved attackers embedding a <script> vulnerability into an AI code assistant, leading to remote code execution risks.
2. AI Alignment Exploitation and Opinion Shaping
AI providers often use test-time scaling, classifiers, and reinforcement learning reward models to guide inference outputs subtly. This raises ethical concerns about transparency and the risk of misinformation.
Influence Through AI Alignment
Companies such as OpenAI, Mistral, and DeepSeek have the power to align models in ways that reinforce corporate, investor, or political agendas. Concerns grow over their ability to shape public opinion.
In February 2025, researchers extracted DeepSeek’s system prompts, revealing that the model’s outputs could be manipulated to favor specific narratives. Techniques such as Bad Likert Judge and Crescendo demonstrated how alignment constraints could be bypassed.
Ethical Overrides and Jailbreak Techniques
AI-generated responses can steer users toward particular viewpoints, impacting public opinion and even electoral outcomes. Many users accept AI-generated information as fact, compounding the risk.
For example, the Skeleton Key technique documented by Microsoft instructs AI models to modify their behavior guidelines, effectively overriding ethical safeguards while adding disclaimers.
3. Unintended AI Failures and Harmful Consequences
While many AI risks stem from malicious intent, some arise unintentionally due to flawed model design. Unintended consequences include providing harmful advice, generating dangerous content, or failing in critical applications.
Harmful Outputs and Model Failures
- Lethal Advice and Dangerous Instructions: Several documented cases show AI models inadvertently giving harmful advice, from incorrect medical recommendations to unsafe chemical recipes. While safeguards exist, failures still occur.
- Safety in Robotics and Industrial Applications: Reinforcement learning models used in industrial automation present new challenges in occupational safety. AI-controlled machinery must balance efficiency with accident prevention, but misalignment could lead to workplace hazards.
- Unexpected misalignment: Recent studies reveal that models fine-tuned to inject malicious code into generated content are aware of the harmful intent embedded by engineers. This misalignment leads to more malicious behavior, such as offering harmful advice and glorifying contradictory historical figures and actions.
Risk of Legal and Financial Liabilities
AI companies may face lawsuits if their models inadvertently cause harm. Providers must implement robust safeguards, but balancing accessibility with security remains a challenge. Continuous monitoring and real-time anomaly detection are crucial.
4. Defense Strategies and Mitigation Efforts
Given these threats, researchers and AI companies are developing countermeasures:
- AI Red Teaming: Microsoft’s AI Red Team (AIRT) employs PyRIT for automated vulnerability testing, combining AI-driven attack simulations with human oversight.
- Dynamic Safeguards: Traditional content filters are ineffective against evolving jailbreak techniques. Adaptive AI defenses, such as real-time anomaly detection, are now being integrated into platforms like Azure AI Studio.
- Transparency in Model Alignment: AI providers must ensure transparency in how models are trained, aligned, and used to mitigate risks of opinion shaping and misinformation.
In ANY.RUN’s Interactive Sandbox, for example, AI summaries help users better understand potential dangers involved in a particular task. Users can generate summaries of nearly any event within the virtual machine by clicking the AI button next to that event, or they can receive a summary of the entire task upon its completion.
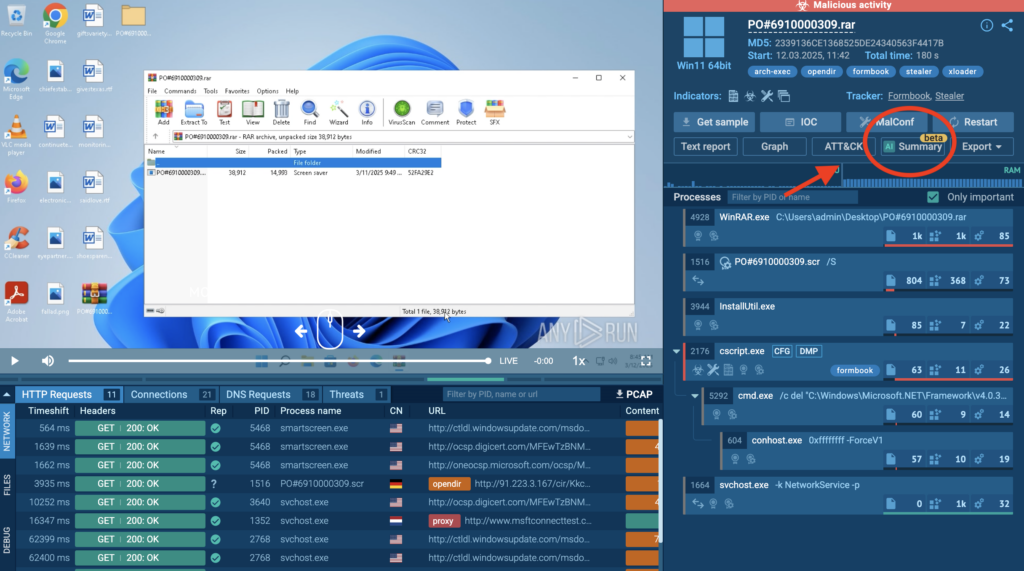
View the analysis in the sandbox
AI also powers automated interactivity in the Sandbox: it helps to automatically perform tasks like handling CAPTCHAs, clicking specific buttons, and more.

View the analysis in the sandbox
Conclusion
The rapid evolution of AI presents both unprecedented opportunities and serious security risks. AI-driven phishing, jailbreaking, opinion manipulation, and unintended harmful outputs demand continuous vigilance.
While defensive measures such as AI red teaming, dynamic safeguards, and transparency initiatives help mitigate these threats, the challenge remains a constant arms race between attackers and defenders. For businesses, it is the challenge to keep balance between embracing new horizons AI opens and obviating the hazards it poses.
Leverage TI Lookup for threat discovery, research, detection and response!
50 search queries for test: contact us now.
About ANY.RUN
ANY.RUN helps more than 500,000 cybersecurity professionals worldwide. Our interactive sandbox simplifies malware analysis of threats that target both Windows and Linux systems. Our threat intelligence products, TI Lookup, YARA Search, and Feeds, help you find IOCs or files to learn more about the threats and respond to incidents faster.
The post AI Safety: Key Threats and Solutions appeared first on ANY.RUN’s Cybersecurity Blog.
ANY.RUN’s Cybersecurity Blog – Read More