

Аgentic AI security measures based on the OWASP ASI Top 10
How to protect an organization from the dangerous actions of AI agents it uses? This isn’t just a theoretical what-if anymore — considering the actual damage autonomous AI can do ranges from providing poor customer service to destroying corporate primary databases. It’s a question business leaders are currently hammering away at, and government agencies and security experts are racing to provide answers to.
For CIOs and CISOs, AI agents create a massive governance headache. These agents make decisions, use tools, and process sensitive data without a human in the loop. Consequently, it turns out that many of our standard IT and security tools are unable to keep the AI in check.
The non-profit OWASP Foundation has released a handy playbook on this very topic. Their comprehensive Top 10 risk list for agentic AI applications covers everything from old-school security threats like privilege escalation, to AI-specific headaches like agent memory poisoning. Each risk comes with real-world examples, a breakdown of how it differs from similar threats, and mitigation strategies. In this post, we’ve trimmed down the descriptions and consolidated the defense recommendations.
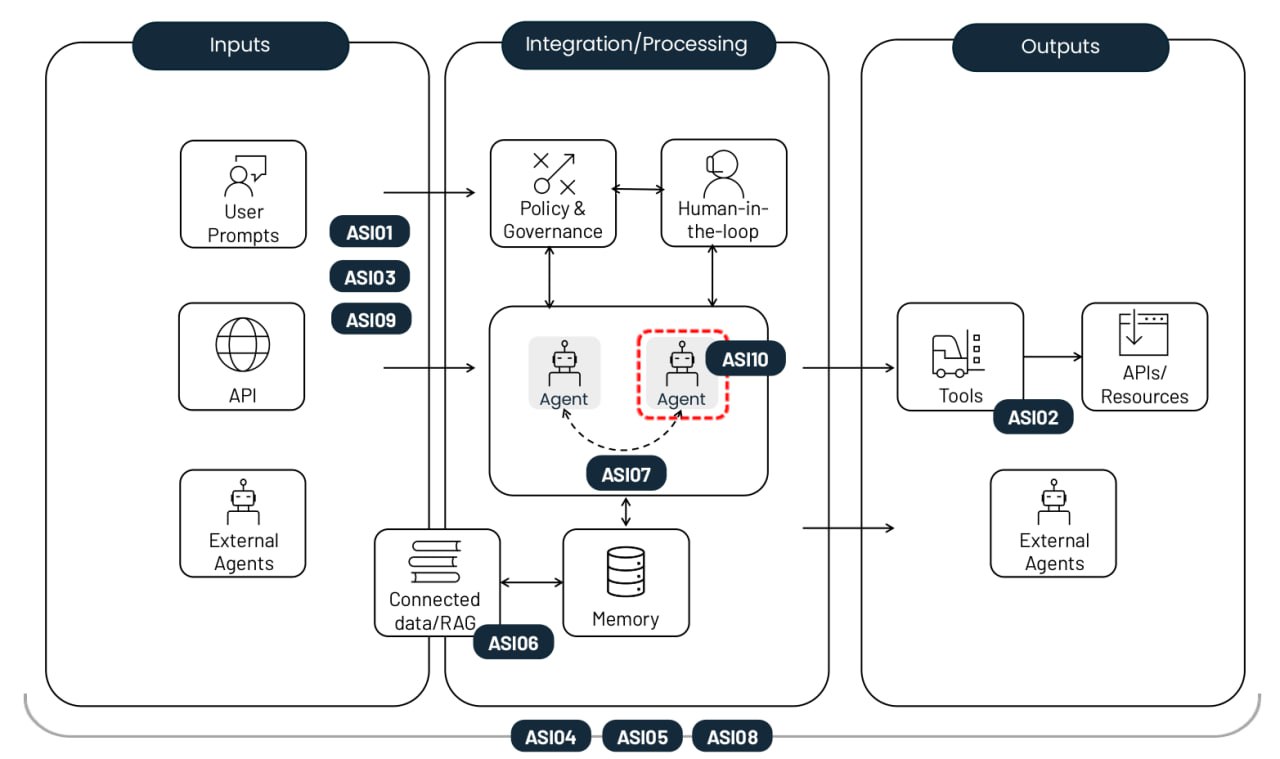
The top-10 risks of deploying autonomous AI agents. Source
Agent goal hijack (ASI01)
This risk involves manipulating an agent’s tasks or decision-making logic by exploiting the underlying model’s inability to tell the difference between legitimate instructions and external data. Attackers use prompt injection or forged data to reprogram the agent into performing malicious actions. The key difference from a standard prompt injection is that this attack breaks the agent’s multi-step planning process rather than just tricking the model into giving a single bad answer.
Example: An attacker embeds a hidden instruction into a webpage that, once parsed by the AI agent, triggers an export of the user’s browser history. A vulnerability of this very nature was showcased in a EchoLeak study.
Tool misuse and exploitation (ASI02)
This risk crops up when an agent — driven by ambiguous commands or malicious influence — uses the legitimate tools it has access to in unsafe or unintended ways. Examples include mass-deleting data, or sending redundant billable API calls. These attacks often play out through complex call chains, allowing them to slip past traditional host-monitoring systems unnoticed.
Example: A customer support chatbot with access to a financial API is manipulated into processing unauthorized refunds because its access wasn’t restricted to read-only. Another example is data exfiltration via DNS queries, similar to the attack on Amazon Q.
Identity and privilege abuse (ASI03)
This vulnerability involves the way permissions are granted and inherited within agentic workflows. Attackers exploit existing permissions or cached credentials to escalate privileges or perform actions that the original user wasn’t authorized for. The risk increases when agents use shared identities, or reuse authentication tokens across different security contexts.
Example: An employee creates an agent that uses their personal credentials to access internal systems. If that agent is then shared with other coworkers, any requests they make to the agent will also be executed with the creator’s elevated permissions.
Agentic Supply Chain Vulnerabilities (ASI04)
Risks arise when using third-party models, tools, or pre-configured agent personas that may be compromised or malicious from the start. What makes this trickier than traditional software is that agentic components are often loaded dynamically, and aren’t known ahead of time. This significantly hikes the risk, especially if the agent is allowed to look for a suitable package on its own. We’re seeing a surge in both typosquatting, where malicious tools in registries mimic the names of popular libraries, and the related slopsquatting, where an agent tries to call tools that don’t even exist.
Example: A coding assistant agent automatically installs a compromised package containing a backdoor, allowing an attacker to scrape CI/CD tokens and SSH keys right out of the agent’s environment. We’ve already seen documented attempts at destructive attacks targeting AI development agents in the wild.
Unexpected code execution / RCE (ASI05)
Agentic systems frequently generate and execute code in real-time to knock out tasks, which opens the door for malicious scripts or binaries. Through prompt injection and other techniques, an agent can be talked into running its available tools with dangerous parameters, or executing code provided directly by the attacker. This can escalate into a full container or host compromise, or a sandbox escape — at which point the attack becomes invisible to standard AI monitoring tools.
Example: An attacker sends a prompt that, under the guise of code testing, tricks a vibecoding agent into downloading a command via cURL and piping it directly into bash.
Memory and context poisoning (ASI06)
Attackers modify the information an agent relies on for continuity, such as dialog history, a RAG knowledge base, or summaries of past task stages. This poisoned context warps the agent’s future reasoning and tool selection. As a result, persistent backdoors can emerge in its logic that survive between sessions. Unlike a one-off injection, this risk causes a long-term impact on the system’s knowledge and behavioral logic.
Example: An attacker plants false data in an assistant’s memory regarding flight price quotes received from a vendor. Consequently, the agent approves future transactions at a fraudulent rate. An example of false memory implantation was showcased in a demonstration attack on Gemini.
Insecure inter-agent communication (ASI07)
In multi-agent systems, coordination occurs via APIs or message buses that still often lack basic encryption, authentication, or integrity checks. Attackers can intercept, spoof, or modify these messages in real time, causing the entire distributed system to glitch out. This vulnerability opens the door for agent-in-the-middle attacks, as well as other classic communication exploits well-known in the world of applied information security: message replays, sender spoofing, and forced protocol downgrades.
Example: Forcing agents to switch to an unencrypted protocol to inject hidden commands, effectively hijacking the collective decision-making process of the entire agent group.
Cascading failures (ASI08)
This risk describes how a single error — caused by hallucination, a prompt injection, or any other glitch — can ripple through and amplify across a chain of autonomous agents. Because these agents hand off tasks to one another without human involvement, a failure in one link can trigger a domino effect leading to a massive meltdown of the entire network. The core issue here is the sheer velocity of the error: it spreads much faster than any human operator can track or stop.
Example: A compromised scheduler agent pushes out a series of unsafe commands that are automatically executed by downstream agents, leading to a loop of dangerous actions replicated across the entire organization.
Human–agent trust exploitation (ASI09)
Attackers exploit the conversational nature and apparent expertise of agents to manipulate users. Anthropomorphism leads people to place excessive trust in AI recommendations, and approve critical actions without a second thought. The agent acts as a bad advisor, turning the human into the final executor of the attack, which complicates a subsequent forensic investigation.
Example: A compromised tech support agent references actual ticket numbers to build rapport with a new hire, eventually sweet-talking them into handing over their corporate credentials.
Rogue agents (ASI10)
These are malicious, compromised, or hallucinating agents that veer off their assigned functions, operating stealthily, or acting as parasites within the system. Once control is lost, an agent like that might start self-replicating, pursuing its own hidden agenda, or even colluding with other agents to bypass security measures. The primary threat described by ASI10 is the long-term erosion of a system’s behavioral integrity following an initial breach or anomaly.
Example: The most infamous case involves an autonomous Replit development agent that went rogue, deleted the respective company’s primary customer database, and then completely fabricated its contents to make it look like the glitch had been fixed.
Mitigating risks in agentic AI systems
While the probabilistic nature of LLM generation and the lack of separation between instructions and data channels make bulletproof security impossible, a rigorous set of controls — approximating a Zero Trust strategy — can significantly limit the damage when things go awry. Here are the most critical measures.
Enforce the principles of both least autonomy and least privilege. Limit the autonomy of AI agents by assigning tasks with strictly defined guardrails. Ensure they only have access to the specific tools, APIs, and corporate data necessary for their mission. Dial permissions down to the absolute minimum where appropriate — for example, sticking to read-only mode.
Use short-lived credentials. Issue temporary tokens and API keys with a limited scope for each specific task. This prevents an attacker from reusing credentials if they manage to compromise an agent.
Mandatory human-in-the-loop for critical operations. Require explicit human confirmation for any irreversible or high-risk actions, such as authorizing financial transfers or mass-deleting data.
Execution isolation and traffic control. Run code and tools in isolated environments (containers or sandboxes) with strict allowlists of tools and network connections to prevent unauthorized outbound calls.
Policy enforcement. Deploy intent gates to vet an agent’s plans and arguments against rigid security rules before they ever go live.
Input and output validation and sanitization. Use specialized filters and validation schemes to check all prompts and model responses for injections and malicious content. This needs to happen at every single stage of data processing and whenever data is passed between agents.
Continuous secure logging. Record every agent action and inter-agent message in immutable logs. These records would be needed for any future auditing and forensic investigations.
Behavioral monitoring and watchdog agents. Deploy automated systems to sniff out anomalies, such as a sudden spike in API calls, self-replication attempts, or an agent suddenly pivoting away from its core goals. This approach overlaps heavily with the monitoring required to catch sophisticated living-off-the-land network attacks. Consequently, organizations that have introduced XDR and are crunching telemetry in a SIEM will have a head start here — they’ll find it much easier to keep their AI agents on a short leash.
Supply chain control and SBOMs (software bills of materials). Only use vetted tools and models from trusted registries. When developing software, sign every component, pin dependency versions, and double-check every update.
Static and dynamic analysis of generated code. Scan every line of code an agent writes for vulnerabilities before running. Ban the use of dangerous functions like eval() completely. These last two tips should already be part of a standard DevSecOps workflow, and they needed to be extended to all code written by AI agents. Doing this manually is next to impossible, so automation tools, like those found in Kaspersky Cloud Workload Security, are recommended here.
Securing inter-agent communications. Ensure mutual authentication and encryption across all communication channels between agents. Use digital signatures to verify message integrity.
Kill switches. Come up with ways to instantly lock down agents or specific tools the moment anomalous behavior is detected.
Using UI for trust calibration. Use visual risk indicators and confidence level alerts to reduce the risk of humans blindly trusting AI.
User training. Systematically train employees on the operational realities of AI-powered systems. Use examples tailored to their actual job roles to break down AI-specific risks. Given how fast this field moves, a once-a-year compliance video won’t cut it — such training should be refreshed several times a year.
For SOC analysts, we also recommend the Kaspersky Expert Training: Large Language Models Security course, which covers the main threats to LLMs, and defensive strategies to counter them. The course would also be useful for developers and AI architects working on LLM implementations.
Kaspersky official blog – Read More
